44、NLP的其他分词功能测试
1、 命名实体识别功能测试
@Test
public void testNer(){
if (NER.create("ltp_data/ner.model")<0) {
System.err.println("load failed");
return;
}
List<String> words = new ArrayList<String>();
List<String> tags = new ArrayList<String>();
List<String> ners = new ArrayList<String>();
words.add("中国");
tags.add("ns");
words.add("国际");
tags.add("n");
words.add("广播");
tags.add("n");
words.add("电台");
tags.add("n");
words.add("创办");
tags.add("v");
words.add("于");
tags.add("p");
words.add("1941年");
tags.add("m");
words.add("12月");
tags.add("m");
words.add("3日");
tags.add("m");
words.add("。");
tags.add("wp");
NER.recognize(words, tags, ners);
for (int i = 0; i < words.size(); i++) {
System.out.println(ners.get(i));
}
NER.release();
}
结果如下所示

2、句法分析功能测试
/**
* 句法分析功能测试
*/
@Test
public void testParser(){
if (Parser.create("ltp_data/parser.model") < 0) {
System.err.println("loadfailed");
return;
}
List<String> words = new ArrayList<String>();
List<String> tags = new ArrayList<String>();
words.add("一把手");
tags.add("n");
words.add("亲自");
tags.add("d");
words.add("过问");
tags.add("v");
words.add("。");
tags.add("wp");
List<Integer> heads = new ArrayList<Integer>();
List<String> deprels = new ArrayList<String>(); int size = Parser.parse(words, tags, heads, deprels); for (int i = 0; i < size; i++) {
System.out.print(heads.get(i) + ":" + deprels.get(i));
if (i == size - 1) {
System.out.println();
} else {
System.out.print(" ");
}
}
Parser.release();
}
结果:

4、语义角色标注功能测试
@Test
public void testSrl(){
SRL.create("ltp_data/srl");
ArrayList<String> words = new ArrayList<String>();
words.add("一把手");
words.add("亲自");
words.add("过问");
words.add("。");
ArrayList<String> tags = new ArrayList<String>();
tags.add("n");
tags.add("d");
tags.add("v");
tags.add("wp");
ArrayList<String> ners = new ArrayList<String>();
ners.add("O");
ners.add("O");
ners.add("O");
ners.add("O");
ArrayList<Integer> heads = new ArrayList<Integer>();
heads.add(2);
heads.add(2);
heads.add(-1);
heads.add(2);
ArrayList<String> deprels = new ArrayList<String>();
deprels.add("SBV");
deprels.add("ADV");
deprels.add("HED");
deprels.add("WP");
List<Pair<Integer, List<Pair<String, Pair<Integer, Integer>>>>> srls = new ArrayList<Pair<Integer, List<Pair<String, Pair<Integer, Integer>>>>>();
SRL.srl(words, tags, ners, heads, deprels, srls);
for (int i = 0; i < srls.size(); ++i) {
System.out.println(srls.get(i).first + ":");
for (int j = 0; j < srls.get(i).second.size(); ++j) {
System.out.println(" tpye = "
+ srls.get(i).second.get(j).first + " beg = "
+ srls.get(i).second.get(j).second.first + " end = "
+ srls.get(i).second.get(j).second.second);
}
}
SRL.release();
}
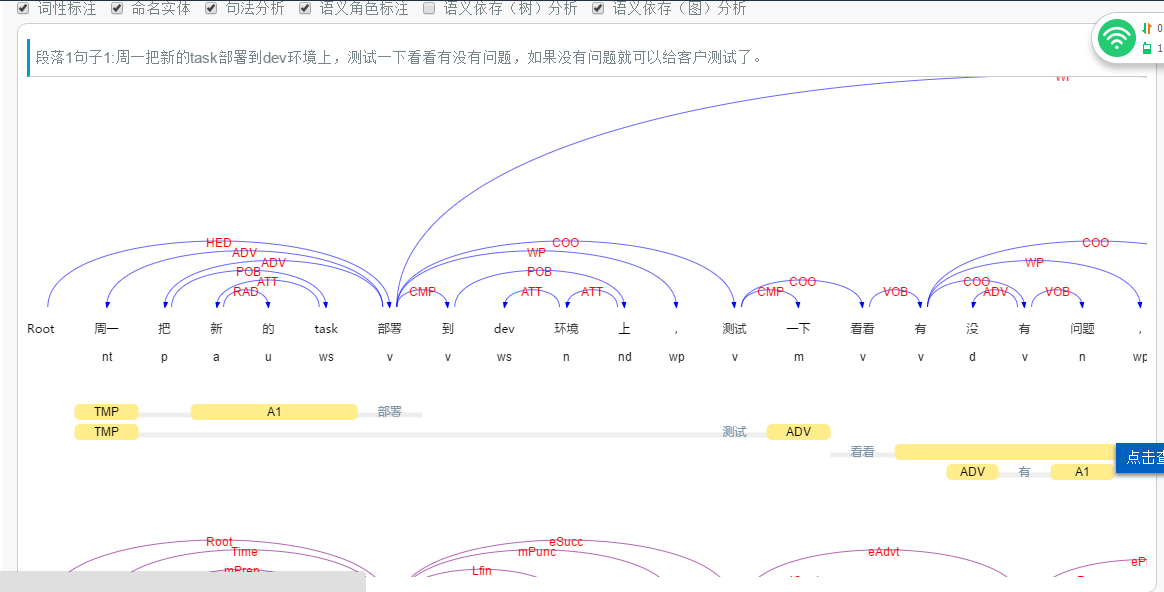
结果如下图所示:

下面插入一段原网站的分词示例
分词依据
http://www.ltp-cloud.com/intro/#pos_how 具体大家可以来前边这个网址中查看分类依据,感觉哈工大讲得很牛呀!
词性标注
词性标注(Part-of-speech Tagging, POS)是给句子中每个词一个词性类别的任务。 这里的词性类别可能是名词、动词、形容词或其他。 下面的句子是一个词性标注的例子。 其中,v代表动词、n代表名词、c代表连词、d代表副词、wp代表标点符号。
国务院/ni 总理/n 李克强/nh 调研/v 上海/ns 外高桥/ns 时/n 提出/v ,/wp 支持/v 上海/ns 积极/a 探索/v 新/a 机制/n 。/wp
词性作为对词的一种泛化,在语言识别、句法分析、信息抽取等任务中有重要作用。 比方说,在抽取“歌曲”的相关属性时,我们有一系列短语:
儿童歌曲
欢快歌曲
各种歌曲
悲伤歌曲








44、NLP的其他分词功能测试的更多相关文章
- HanLP vs LTP 分词功能测试
文章摘自github,本次测试选用 HanLP 1.6.0 , LTP 3.4.0 测试思路 使用同一份语料训练两个分词库,同一份测试数据测试两个分词库的性能. 语料库选取1998年01月的人民日报语 ...
- NLP实现文本分词+在线词云实现工具
实现文本分词+在线词云实现工具 词云是NLP中比较简单而且效果较好的一种表达方式,说到可视化,R语言当仍不让,可见R语言︱文本挖掘——词云wordcloud2包 当然用代码写词云还是比较费劲的,网上也 ...
- 【nlp】中文分词基础原则及正向最大匹配法、逆向最大匹配法、双向最大匹配法的分析
分词算法设计中的几个基本原则: 1.颗粒度越大越好:用于进行语义分析的文本分词,要求分词结果的颗粒度越大,即单词的字数越多,所能表示的含义越确切,如:“公安局长”可以分为“公安 局长”.“公安局 长” ...
- NLP系列-中文分词(基于统计)
上文已经介绍了基于词典的中文分词,现在让我们来看一下基于统计的中文分词. 统计分词: 统计分词的主要思想是把每个词看做是由字组成的,如果相连的字在不同文本中出现的次数越多,就证明这段相连的字很有可能就 ...
- NLP系列-中文分词(基于词典)
中文分词概述 词是最小的能够独立活动的有意义的语言成分,一般分词是自然语言处理的第一项核心技术.英文中每个句子都将词用空格或标点符号分隔开来,而在中文中很难对词的边界进行界定,难以将词划分出来.在汉语 ...
- 【NLP】中文分词:原理及分词算法
一.中文分词 词是最小的能够独立活动的有意义的语言成分,英文单词之间是以空格作为自然分界符的,而汉语是以字为基本的书写单位,词语之间没有明显的区分标记,因此,中文词语分析是中文信息处理的基础与关键. ...
- NLP自然语言处理 jieba中文分词,关键词提取,词性标注,并行分词,起止位置,文本挖掘,NLP WordEmbedding的概念和实现
1. NLP 走近自然语言处理 概念 Natural Language Processing/Understanding,自然语言处理/理解 日常对话.办公写作.上网浏览 希望机器能像人一样去理解,以 ...
- 43、哈工大NLP自然语言处理,LTP4j的测试+还是测试
1.首先需要构建自然语言处理的LTP的框架 (1)需要下载LTP的源码包即c++程序(https://github.com/HIT-SCIR/ltp)下载完解压缩之后的文件为ltp-master (2 ...
- nlp词性标注
nlp词性标注 与分词函数不同,jieba库和pyltp库词性标注函数上形式相差极大. jieba的词性标注函数与分词函数相近,jieba.posseg.cut(sentence,HMM=True)函 ...
随机推荐
- 用RollViewPager实现Android滚动banner
最近项目中要实现一个循环滚动的banner,效果如下图 这个自己写实在是不方便,而且写出来也很难保证没有bug和性能缺陷,好在网上有人开源了一个实现滚动banner的RollViewPager框架,亲 ...
- 批量修改sql server 2008的架构
--批量修改架构.名称为XJADMINATT的所有表修改为dbo-- --把执行的结果,拷贝到命令行,执行命令即可-- declare @name sysname declare csr1 curso ...
- SQLSERVER 复制同一张表的递归结构
CREATE PROCEDURE [dbo].[Pro_Copy] @OLDJiFenSeriesId VARCHAR(), @NEWJiFenSeriesId VARCHAR() AS BEGIN ...
- .NET中的动态编译
代码的动态编译并执行是一个.NET平台提供给我们的很强大的工具用以灵活扩展(当然是面对内部开发人员)复杂而无法估算的逻辑,并通过一些额外的代码来扩展我们已有 的应用程序.这在很大程度上给我们提供了另外 ...
- 11、java中的模板方法设计模式
/* 需求:获取一段程序运行的时间. 原理:获取程序开始和结束的时间并相减即可. 获取时间:System.currentTimeMillis(); 当代码完成优化后,就可以解决这类问题. 这种方式,模 ...
- java对xml文件的读取
<?xml version="1.0" encoding="UTF-8"?> <body> <names type="1 ...
- php连接数据库、创建数据库、创建数据表
<?php $con = mysql_connect("localhost", "root", "root"); if(!$con){ ...
- ubuntu16041,安装opencv3.1.0
[非常感谢:http://www.linuxdiyf.com/linux/18482.html] 1.依赖关系: sudo apt-get install build-essentialsudo ap ...
- selenium查找动态的iframe的name
WebElement frame1 = driver.findElement(By.xpath("/html/body/div[9]/div[2]/div/iframe"));dr ...
- firefox火狐浏览器过滤广告插件:Adblock Plus
firefox火狐浏览器过滤广告插件:Adblock Plus