通过数据库中的表,使用 MyEclipse2017的反向生成工具-->hibernate反转引擎引擎(MyEclipse2017自带的插件) 来反转生成实体类和对应的映射文件
通过数据库中的表,使用 MyEclipse2017的反向生成工具-->hibernate反转引擎引擎(MyEclipse2017自带的插件) 来反转生成实体类和对应的映射文件
文章目录
Java视图
1、在MyEclipse中,Java视图下,新建一个普通的java project,新建该项目的目的是:用来接收反转引擎生成的实体类和对应的映射文件。
2、在项目上右键 --> Configure Facets... --> Install Hibernate Facet
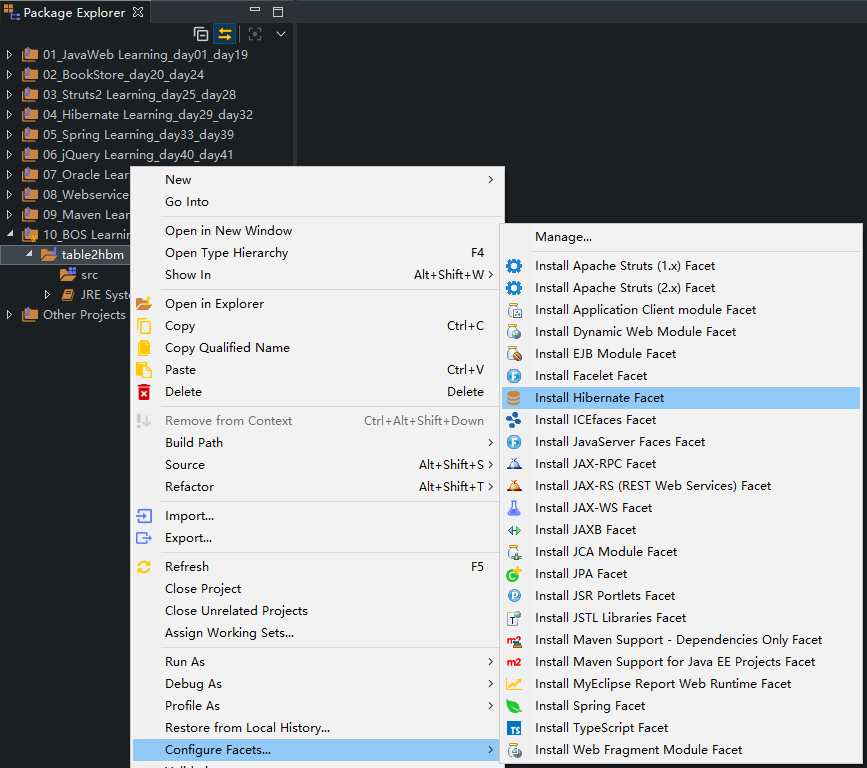
3、选择Hibernate的版本和运行库
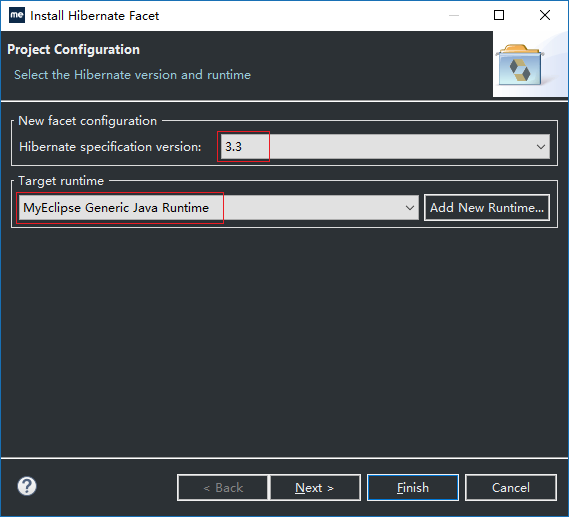
4、点击Next
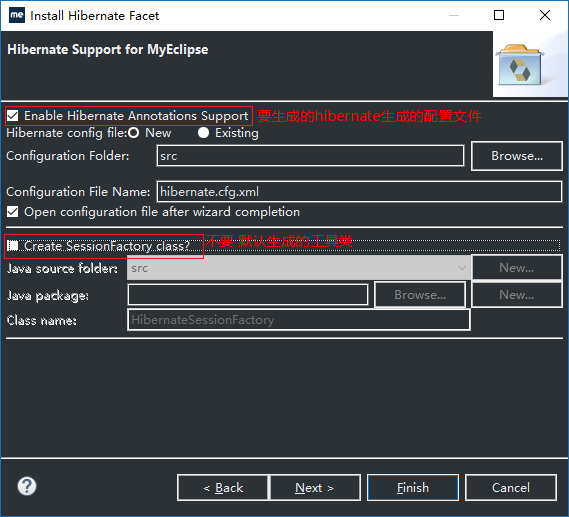
5、点击Next
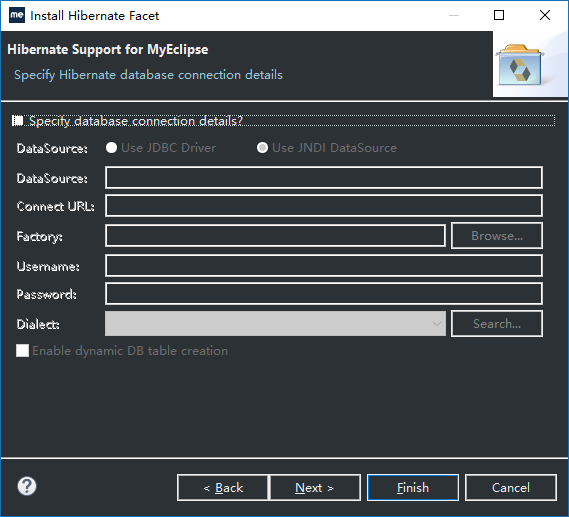
6、点next,再点Finish,这时一个hibernate项目创建完成 ,项目的图标有变化,表示的是hibernate项目。如下图所示:
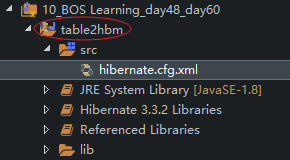
7、再创建自己的包结构
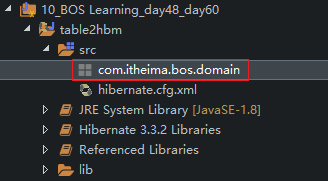
Hibernate视图
8、我们再切换到 Hibernate视图
9、在DB Browser下的 空白处右键 --> New
填写信息,如下图所示:

10、Test Driver 通过后,我们点击Next
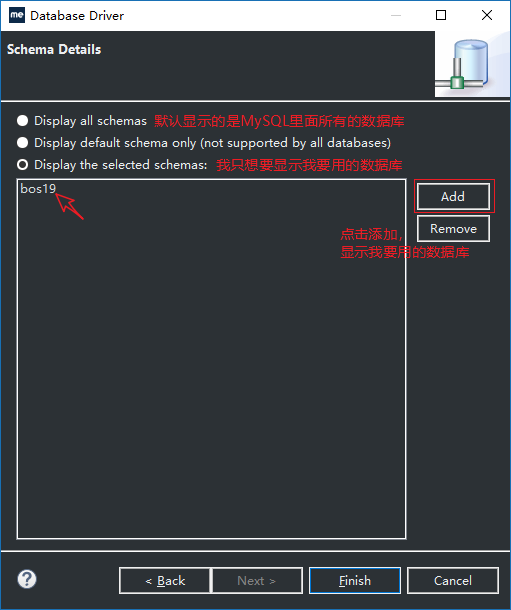
11、如图选好后,点击Finish,我们看到DB Browser下多了一个conn1。双击打开,我们就会看到需要用到的数据库了。
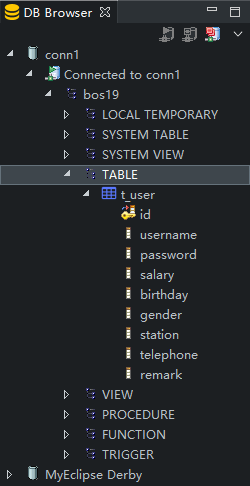
12、选中表, 右键 Heibernate Reverse Engineering...
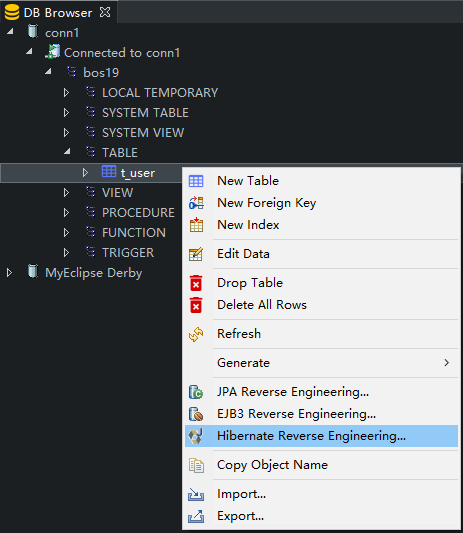
13、选中自己新建的那个 table2hbm项目,以及对应的包结构,勾选上要生成的文件,点击Next
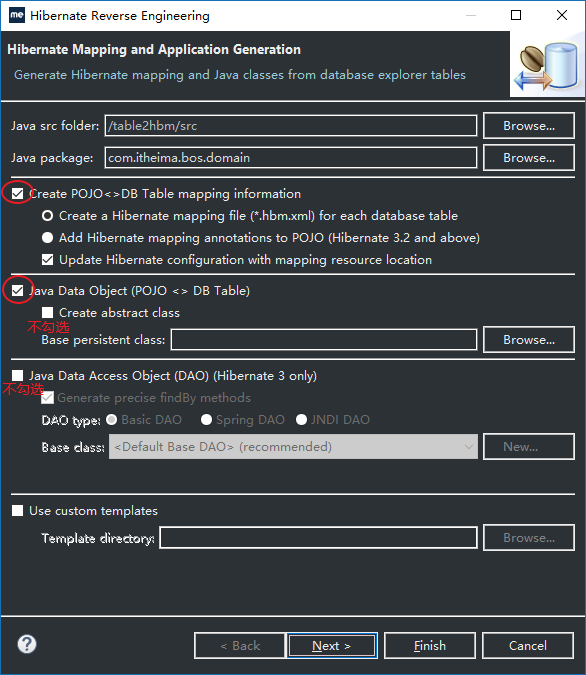
14、由于目前我们只是一张表,所以不需要勾选表与表之间的关系,点击Next
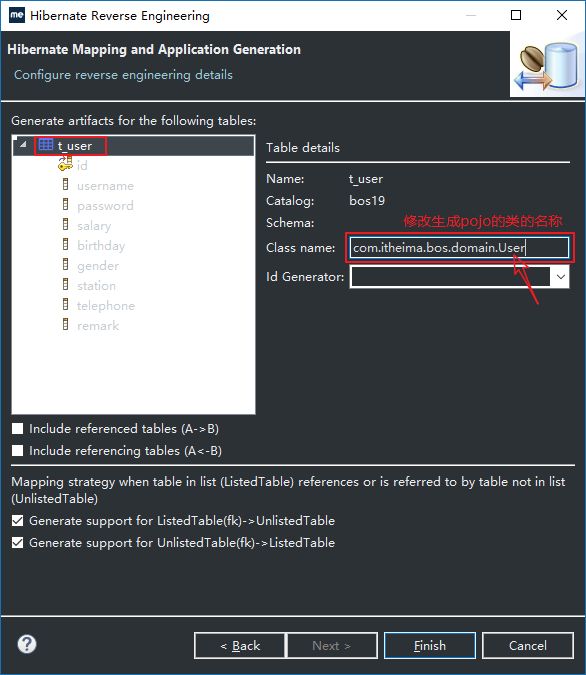
15、因为默认生成的pojo类名是TUser,不好,我们需要自定义的,如下图所示:
16、点击Finish,到此为止,实体类和对应的映射文件就自动生成好了。我们切换至Java视图,可以看到自己想要的,如下图所示:
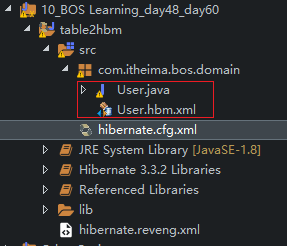
eclipse
17、由于实际开发中,为了响应速度和开发效率,我们一般使用eclipse,而不使用带了很多插件的MyEclipse,我们使用它仅仅是为了使用一下它的插件而已!
所以我们再将我们想要的东西(上图红色框框中的),复制粘贴到我们在Eclipse中的项目里面去,如下图所示:
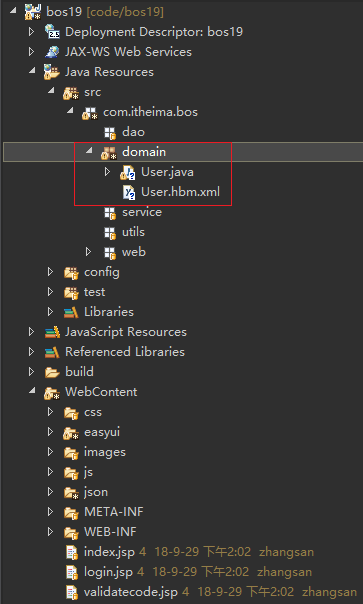
18、我们查看下复制过来的两个文件,发现 User.hbm.xml 文件有一些小问题,需要就行修正
(1)、
原来使用的.dtd是:
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
我们项目中使用的.dtd是:
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
我们要把原来使用的.dtd换成我们项目中使用的.dtd。
(2)、
将User.hbm.xml 文件中的属性 catalog="bos19" 删除掉,这样该文件就对数据库名称就没有要求了,数据库名称你爱改成什么都行!
参考链接:https://blog.csdn.net/wt346326775/article/details/41210423
我的博客园地址:https://www.cnblogs.com/chenmingjun
我的CSDN地址:https://blog.csdn.net/u012990179
我的蚂蚁笔记博客地址:https://blog.leanote.com/chenmingjun
Copyright ©2018-2019 黑泽明军
【转载文章务必保留出处和署名,谢谢!】
通过数据库中的表,使用 MyEclipse2017的反向生成工具-->hibernate反转引擎引擎(MyEclipse2017自带的插件) 来反转生成实体类和对应的映射文件的更多相关文章
- 分享一个SQLSERVER脚本(计算数据库中各个表的数据量和每行记录所占用空间)
分享一个SQLSERVER脚本(计算数据库中各个表的数据量和每行记录所占用空间) 很多时候我们都需要计算数据库中各个表的数据量和每行记录所占用空间 这里共享一个脚本 CREATE TABLE #tab ...
- 清空SQL Server数据库中所有表数据的方法(转)
清空SQL Server数据库中所有表数据的方法 其实删除数据库中数据的方法并不复杂,为什么我还要多此一举呢,一是我这里介绍的是删除数据库的所有数据,因为数据之间可能形成相互约束关系,删除操作可能陷入 ...
- MySql 查询数据库中所有表名
查询数据库中所有表名select table_name from information_schema.tables where table_schema='csdb' and table_type= ...
- SQLServer 命令批量删除数据库中指定表(游标循环删除)
DECLARE @tablename VARCHAR(30),@sql VARCHAR(500)DECLARE cur_delete_table CURSOR READ_ONLY FORWARD_ON ...
- 通过jdbc获取数据库中的表结构
通过jdbc获取数据库中的表结构 主键 各个表字段类型及应用生成实体类 1.JDBC中通过MetaData来获取具体的表的相关信息.可以查询数据库中的有哪些表,表有哪些字段,字段的属性等等.Met ...
- 利用SQL语句查询数据库中所有表
Oracle: SELECT * FROM ALL_TABLES;系统里有权限的表 SELECT * FROM DBA_TABLES; 系统表 SELECT * FROM USER_TABLES; 当 ...
- python生成数据库中所有表的DESC描述
在数据库设计完成之后, 常常需要在 wiki 或其他文档中保存一份数据库中所有表的 desc 描述, 尤其是每个字段的含义和用途. 手动去生成自然是不可取的. 因此, 我编写了一个简单的 python ...
- SQlServer 从系统表 sysobjects 中获取数据库中所有表或存储过程等对象
[sysobjects] 一.概述 系统对象表. 保存当前数据库的对象,如约束.默认值.日志.规则.存储过程等,该表中包含该数据库中的表 存储过程 视图等所有对象 在sqlserver2005,sql ...
- PostgreSQL数据库中获取表主键名称
PostgreSQL数据库中获取表主键名称 一.如下表示,要获取teacher表的主键信息: select pg_constraint.conname as pk_name,pg_attribute. ...
随机推荐
- DRF的三大认证组件
目录 DRF的三大认证组件 认证组件 工作原理 实现 权限组件 工作原理 实现 频率组件 工作原理 实现 三种组件的配置 DRF的三大认证组件 认证组件 工作原理 首先,认证组件是基于BaseAuth ...
- C++之程序流程_选择结构
C/C++支持最基本的三种程序运行结构:==顺序结构.选择结构.循环结构== * 顺序结构:程序按顺序执行,不发生跳转* 选择结构:依据条件是否满足,有选择的执行相应功能* 循环结构:依据条件是否满足 ...
- 7.springboot+mybatis+redis整合
选择生成的依赖 选择保存的工程路径 查询已经生成的依赖,并修改mysql的版本 <dependencies> <dependency> <groupId>org.s ...
- SpringCloud学习笔记《---06 Config 分布式配置中心---》基础篇
- JS对象 indexOf() 方法可返回某个指定的字符串值在字符串中首次出现的位置。
返回指定的字符串首次出现的位置 indexOf() 方法可返回某个指定的字符串值在字符串中首次出现的位置. 语法 stringObject.indexOf(substring, startpos) 参 ...
- javascript 的学习笔记(第一天)
1.==与=== == 先转换类型,再比较 === 直接比较 2.parseInt 把字符串转成整数 parsefloat 把字符串转成小数 3. 变量的作用域:变量起作用的范围 局部变量: ...
- JQuery ajax提交表单及表单验证
JQuery ajax提交表单及表单验证 博客分类: jsp/html/javascript/ajax/development Kit 开源项目 注:经过验证,formValidator只适合一个 ...
- javaScript 习题总结(持续更新)
判定偶数 function collect_all_even(collection) { return collection.filter(item => item%2 == 0); } 两个集 ...
- create table常用命令
CREATE TABLE students( stuID INTEGER NOT NULL , stuname ) not null, sex int NOT NULL ); CREATE TABLE ...
- MySql查询分页数据
MySql查询分页数据