机器翻译注意力机制及其PyTorch实现
前面阐述注意力理论知识,后面简单描述PyTorch利用注意力实现机器翻译
Effective Approaches to Attention-based Neural Machine Translation
简介
Attention介绍
在翻译的时候,选择性的选择一些重要信息。详情看这篇文章 。
本着简单和有效的原则,本论文提出了两种注意力机制。
Global
每次翻译时,都选择关注所有的单词。和Bahdanau的方式 有点相似,但是更简单些。简单原理介绍。
Local
每次翻译时,只选择关注一部分的单词。介于soft和hard注意力之间。(soft和hard见别的论文)。
优点有下面几个
- 比Global和Soft更好计算
- 局部注意力 随处可见、可微,更好实现和训练。
应用范围
在训练神经网络的时候,注意力机制应用十分广泛。让模型在不同的形式之间,学习对齐等等。有下面一些领域:
- 机器翻译
- 语音识别
- 图片描述
- between image objects and agent actions in the dynamic control problem (不懂,以后再说吧)
神经机器翻译
思想
输入句子x=(x1,x2,⋯,xn)x=(x1,x2,⋯,xn) ,输出目标句子y=(y1,y2,⋯,ym)y=(y1,y2,⋯,ym) 。
神经机器翻译(Neural machine translation, NMT),利用神经网络,直接对p(y∣x)p(y∣x) 进行建模。一般由Encoder和Decoder构成。Encoder-Decoder介绍文章链接 。
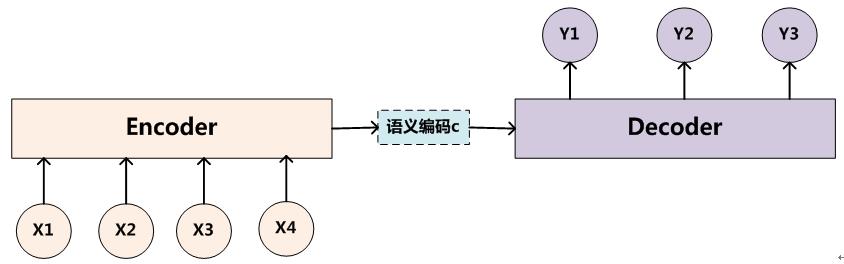
Encoder把输入句子xx 编码成一个语义向量ss (c表示也可以),然后由Decoder 一个一个产生目标单词 yiyilogp(y∣x)=m∑j=1logp(yj∣y<j,s)=m∑j=1logp(yj∣y1,⋯,yj−1,s)logp(y∣x)=∑j=1mlogp(yj∣y<j,s)=∑j=1mlogp(yj∣y1,⋯,yj−1,s)但是怎么选择Encoder和Decoder(RNN, CNN, GRU, LSTM),怎么去生成语义ss却有很多选择。
概率计算
结合Decoder上一时刻的隐状态hj−1hj−1和encoder给的语义向量ss,通过函数ff ,就可以计算出当前的隐状态hjhj :hj=f(hj−1,s)hj=f(hj−1,s)通过函数gg对当前隐状态hjhj进行转换,再softmax,就可以得到翻译的目标单词yiyi了(选概率最大的那个)。
gg一般是线性变换,维数变化是[1,h]→[1,vocab_size][1,h]→[1,vocab_size]。p(yj∣y<j,s)=softmaxg(hj)p(yj∣y<j,s)=softmaxg(hj)语义向量ss 会贯穿整个翻译的过程,每一步翻译都会使用到语义向量的内容,这就是注意力机制。
本论文的模型
本论文采用stack LSTM的构建NMT系统。如下所示:
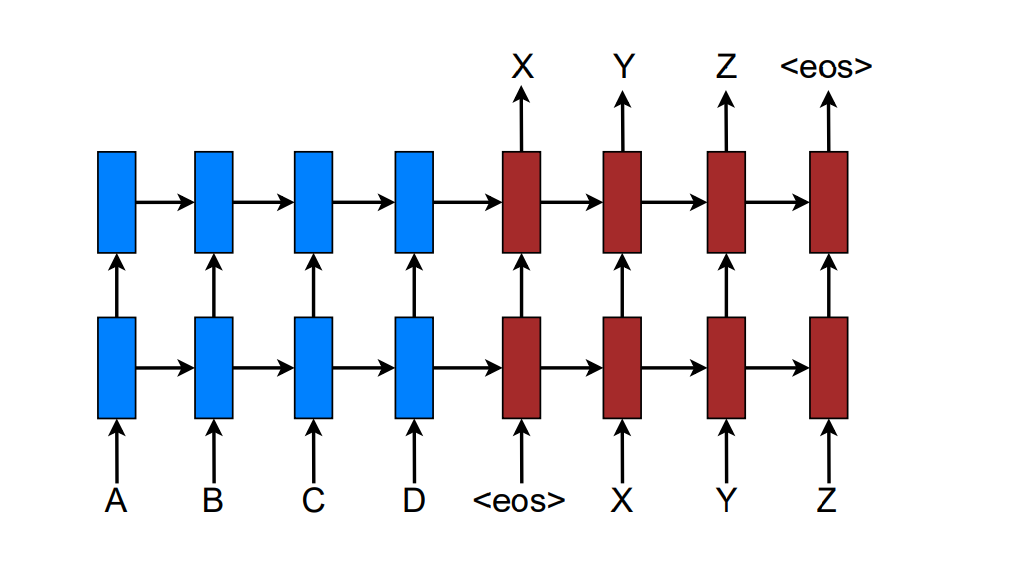
训练目标是Jt=∑(x,y)−logp(y∣x)Jt=∑(x,y)−logp(y∣x)
注意力模型
注意力模型广义上分为global和local。Global的attention来自于整个序列,而local的只来自于序列的一部分。
解码总体流程
Decoder时,在时刻tt,要翻译出单词ytyt ,如下步骤:
- 最顶层LSTM的隐状态 htht
- 计算带有原句子信息语义向量ctct。Global和Local的区别在于ctct的计算方式不同
- 串联ht,ctht,ct,计算得到带有注意力的隐状态 ^ht=tanh(Wc[ct;ht])h^t=tanh(Wc[ct;ht])
- 通过注意力隐状态得到预测概率 p(yt∣y<t,x)=softmax(Ws^ht)p(yt∣y<t,x)=softmax(Wsh^t)
Global Attention
总体思路
在计算ctct 的时候,会考虑整个encoder的隐状态。Decoder当前隐状态htht, Encoder时刻s的隐状态¯hsh¯s。
对齐向量αtαt代表时刻tt 输入序列中的单词对当前单词ytyt 的对齐概率,长度是TxTx, 随着输入句子的长度而改变 。xsxs与ytyt 的对齐概率如下:αt(s)=align(ht,¯hs)=score(ht,¯hs)∑Txi=1score(ht,¯hi),实际上softmaxαt(s)=align(ht,h¯s)=score(ht,h¯s)∑i=1Txscore(ht,h¯i),实际上softmax结合上面的解码总体流程,有下面的流程all(¯hs),ht→αt→ct.ct,ht→^ht.^ht→ytall(h¯s),ht→αt→ct.ct,ht→h^t.h^t→yt简单来说是ht→αt→ct→^ht→ytht→αt→ct→h^t→yt 。
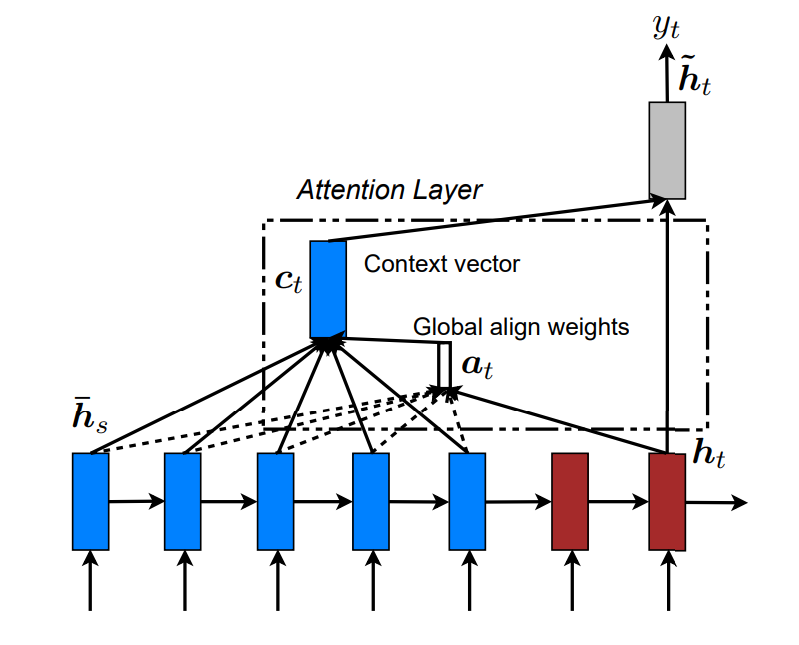
score计算
score(ht,¯hs)score(ht,h¯s) 是一种基于内容content-based的函数,有3种实现方式score(ht,¯hs)=⎧⎪⎨⎪⎩hTt¯hsdothTtWa¯hsgeneralvTatanh(Wa[ht;¯hs])concatscore(ht,h¯s)={htTh¯sdothtTWah¯sgeneralvaTtanh(Wa[ht;h¯s])concat缺点
生成每个目标单词的时候,都必须注意所有的原单词, 这样计算量很大,翻译长序列可能很难,比如段落或者文章。
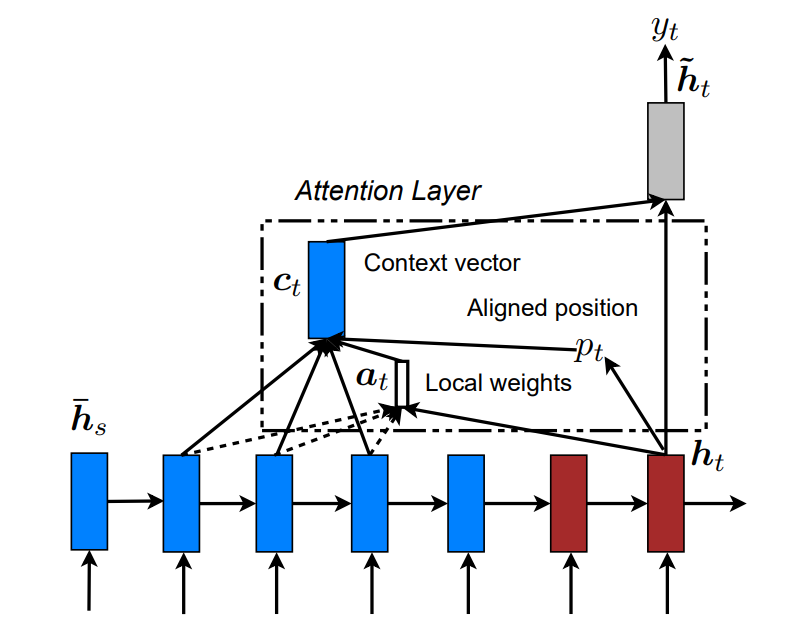
Local Attention
在生成目标单词的时候,Local会选择性地关注一小部分原单词去计算αt,ctαt,ct,这样就解决了Global的问题。如下图
Soft和Hard注意
Soft 注意 :类似global注意,权值会放在图片的所有patches中。计算复杂。
Hard 注意: 不同时刻,会选择不同的patch。虽然计算少,但是non-differentiable,并且需要复杂的技术去训练模型,比如方差减少和强化学习。
Local注意
类似于滑动窗口,计算一个对齐位置ptpt,根据经验设置窗口大小DD,那么需要注意的源单词序列是 :[pt−D,pt+D][pt−D,pt+D]αtαt 的长度就是2D2D,只需要选择这2D2D个单词进行注意力计算,而不是Global的整个序列。
对齐位置选择
对齐位置的选择就很重要,主要有两种办法。
local-m (monotonic) 设置位置, 即以当前单词位置作为对齐位置pt=tpt=tlocal-p (predictive) 预测位置
SS 是输入句子的长度,预测对齐位置如下pt=S⋅sigmoid(vTptanh(Wpht)),pt∈[0,S]pt=S⋅sigmoid(vpTtanh(Wpht)),pt∈[0,S]对齐向量计算
αtαt的长度就是2D2D,对于每一个s∈[pt−D,pt+D]s∈[pt−D,pt+D], 为了更好地对齐,添加一个正态分布N(μ,σ2)N(μ,σ2),其中 μ=pt,σ=D2μ=pt,σ=D2。
计算对齐概率:αt(s)=align(ht,¯hs)exp(−(s−μ)22σ2)=align(ht,¯hs)exp(−2(s−pt)2D2)αt(s)=align(ht,h¯s)exp(−(s−μ)22σ2)=align(ht,h¯s)exp(−2(s−pt)2D2)
Input-feeding
前面的Global和Local两种方式中,在每一步的时候,计算每一个attention (实际上是指 ^hth^t),都是独立的,这样只是次最优的。
在每一步的计算中,这些attention应该有所关联,当前知道之前的attention才对。实际是应该有个coverage set去追踪之前的信息。
我们会把当前的注意^hth^t 作为下一次的输入,并且做一个串联,来计算新的attention,如下图所示
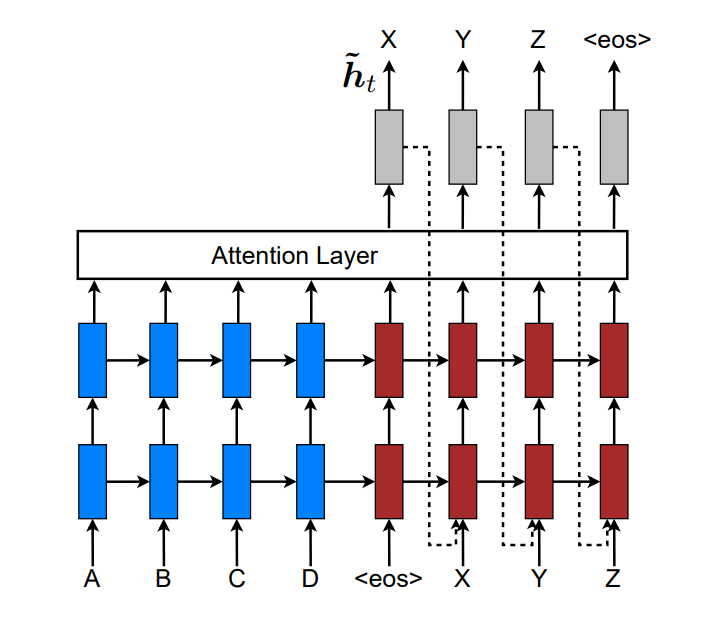
这样有两重意义:
- 模型会知道之前的对齐选择
- 会建立一个水平和垂直都很深的网络
PyTorch实现机器翻译
计算输入语义
比较简单,使用GRU进行编码,使用outputs作为哥哥句子的编码语义。PyTorch RNN处理变长序列
1 |
def forward(self, input_seqs, input_lengths, hidden=None): |
计算对齐向量
实际上就是attn_weights, 也就是输入序列对当前要预测的单词的一个注意力分配。
输入输出定义
Encoder的输出,所有语义cc,encoder_outputs, [is, b, h]。 is=input_seq_len是输入句子的长度
当前时刻Decoder的htht, decoder_rnn_output, [ts, b, h] 。实际上ts=1, 因为每次解码一个单词
1 |
def forward(self, rnn_outputs, encoder_outputs): |
计算得分
使用gerneral的方式,先过神经网络(线性层),再乘法计算得分
1 |
# 过Linear层 (b, h, is) |
softmax计算对齐向量
每一行都是原语义对于某个单词的注意力分配权值向量。对齐向量实际例子
1 |
# [b,ts,is] |
计算新的语义
新的语义也就是,对于翻译单词wtwt所需要的带注意力的语义。
输入输出
1 |
def forward(self, input_seqs, last_hidden, encoder_outputs): |
当前时刻Decoder的隐状态
输入上一时刻的单词和隐状态,通过GRU,计算当前的隐状态。实际上ts=1
1 |
# (ts, b, h), (nl, b, h) |
计算对齐向量
当前时刻的隐状态 rnn_output 和源句子的语义encoder_outputs,计算对齐向量。对齐向量
每一行都是原句子对当前单词(只有一行)的注意力分配。
1 |
# 对齐向量 [b,ts,is] |
计算新的语义
原语义和原语义对当前单词分配的注意力,计算当前需要的新语义。
1 |
# 新的语义 |
预测当前单词
结合新语义和当前隐状态预测新单词
1 |
# 语义和当前隐状态结合 [ts, b, 2h] < [ts, b, h], [ts, b, h] |
总结
1 |
# 1. 对齐向量 |
机器翻译注意力机制及其PyTorch实现的更多相关文章
- Pytorch系列教程-使用Seq2Seq网络和注意力机制进行机器翻译
前言 本系列教程为pytorch官网文档翻译.本文对应官网地址:https://pytorch.org/tutorials/intermediate/seq2seq_translation_tutor ...
- TensorFlow从1到2(十)带注意力机制的神经网络机器翻译
基本概念 机器翻译和语音识别是最早开展的两项人工智能研究.今天也取得了最显著的商业成果. 早先的机器翻译实际脱胎于电子词典,能力更擅长于词或者短语的翻译.那时候的翻译通常会将一句话打断为一系列的片段, ...
- NLP教程(6) - 神经机器翻译、seq2seq与注意力机制
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www.showmeai.tech/article-det ...
- (转)注意力机制(Attention Mechanism)在自然语言处理中的应用
注意力机制(Attention Mechanism)在自然语言处理中的应用 本文转自:http://www.cnblogs.com/robert-dlut/p/5952032.html 近年来,深度 ...
- 注意力机制(Attention Mechanism)在自然语言处理中的应用
注意力机制(Attention Mechanism)在自然语言处理中的应用 近年来,深度学习的研究越来越深入,在各个领域也都获得了不少突破性的进展.基于注意力(attention)机制的神经网络成为了 ...
- 自然语言处理中的自注意力机制(Self-attention Mechanism)
自然语言处理中的自注意力机制(Self-attention Mechanism) 近年来,注意力(Attention)机制被广泛应用到基于深度学习的自然语言处理(NLP)各个任务中,之前我对早期注意力 ...
- TensorFlow LSTM 注意力机制图解
TensorFlow LSTM Attention 机制图解 深度学习的最新趋势是注意力机制.在接受采访时,现任OpenAI研究主管的Ilya Sutskever提到,注意力机制是最令人兴奋的进步之一 ...
- 深度学习之注意力机制(Attention Mechanism)和Seq2Seq
这篇文章整理有关注意力机制(Attention Mechanism )的知识,主要涉及以下几点内容: 1.注意力机制是为了解决什么问题而提出来的? 2.软性注意力机制的数学原理: 3.软性注意力机制. ...
- DeepLearning.ai学习笔记(五)序列模型 -- week2 序列模型和注意力机制
一.基础模型 假设要翻译下面这句话: "简将要在9月访问中国" 正确的翻译结果应该是: "Jane is visiting China in September" ...
随机推荐
- Python基础第十天
一.内容
- python创建文件
创建文件: 1. os.mknod(“test.txt”) 创建空文件 2. open(“test.txt”,w) 直接打开一个文件,如果文件不存在则创建文件 import os def mkdir_ ...
- 【192】PowerShell 相关知识
默写说明: 查询别名所指的真实cmdlet命令. Get-Alias -name ls 查看可用的别名,可以通过 “ls alias:” 或者 “Get-Alias”. 查看所有以Remove打头的c ...
- (转)Silverlight_5_Toolkit_December_2011 安装后点击Toolkit Samples没反应的解决方法
Silverlight Toolkit官方下载地址: http://silverlight.codeplex.com/ http://blog.csdn.net/hcj116/article/deta ...
- Rails bootstrap导入
创建: 2018/03/24 完成: 2018/03/24 适用于Sass, Scss. Less的自己网上搜吧 如何判断是不是Sass/Scss?项目里搜 gem 'sass-rails' ,gem ...
- 洛谷 P2770 航空路线问题【最大费用最大流】
记得cnt=1!!因为是无向图所以可以把回来的路看成另一条向东的路.字符串用map处理即可.拆点限制流量,除了1和n是(i,i+n,2)表示可以经过两次,其他点都拆成(i,i+n,1),费用设为1,原 ...
- 洛谷P1505 [国家集训队]旅游(树剖+线段树)
传送门 这该死的码农题…… 把每一条边变为它连接的两个点中深度较浅的那一个,然后就是一堆单点修改/路径查询,不讲了 这里就讲一下怎么搞路径取反,只要打一个标记就好了,然后把区间和取反,最大最小值交换然 ...
- WFS1.1.0协议(增删改查)+openlayers4.3.1前端构建+geoserver2.15.1安装部署+shpfile数据源配置
WFS简介 1.WFS即,Web要素服务,全称WebFeatureService.GIS下,支持对地理要素的插入,更新,删除,检索和发现服务. 2.属于OGC标准下的通信协议.OGC标准下的GIS服务 ...
- 组合数学练习题(一)——Chemist
题意: 从 n 个人中选出不超过 k 个人,再在选出的人中选出一些人成为队员,再在队员中选一名队长,求不同的方案数.答案 mod 8388608. 共有T组询问,每次给你n和k.T ≤ 10^4 k ...
- Six degrees of Kevin Bacon
转自:https://blog.csdn.net/a17865569022/article/details/78766867 Input* Line 1: Two space-separated in ...