Disruptor源码解读
上一篇已经介绍了Disruptor是什么?简单总结了为什么这么快?下面我们直接源码搞起来,简单粗暴。
高性能队列disruptor为什么这么快?
一、核心类接口
Disruptor 提供了对RingBuffer的封装。
RingBuffer 环形队列,基于数组实现,内存被循环使用,减少了内存分配、回收扩容等操作。
EventProcessor 事件处理器,实现了Runnable,单线程批量处理BatchEventProcessor和多线程处理WorkProcessor。
Sequencer 生产者访问序列的接口,RingBuffer生产者的父接口,其直接实现有SingleProducerSequencer和MultiProducerSequencer。
EventSequencer 空接口,暂时没用,用于以后扩展。
SequenceBarrier 消费者屏障 消费者用于访问缓存的控制器。
WaitStrategy 当没有可消费的事件时,根据特定的实现进行等待。
SingleProducerSequencer 单生产者发布实现类
MultiProducerSequencer 多生产者发布实现类
笔者简单介绍下常用的类,看不懂没关系,等看完源码自然明白。
核心类源码分析已经上传了git地址:https://github.com/Sonion/disroptor
二、生产者
开局一张图,走起。
想分析disruptor,先看生产者,这是笔者整理的生产者相关类图。

单生产者发布流程:
生产者发布消息是从Disruptor的publish方法开始,
//Disruptor.java
public <A> void publishEvent(final EventTranslatorOneArg<T, A> eventTranslator, final A arg)
{
ringBuffer.publishEvent(eventTranslator, arg);
}
实际调用的RingBuffer的publishEvent,实际上也就是做两件事,一先去获取RingBuffer上的一个可用位置,第二步在可用位置上发布数据。
//RingBuffer.java
public <A> void publishEvent(EventTranslatorOneArg<E, A> translator, A arg0)
{
final long sequence = sequencer.next();
translateAndPublish(translator, sequence, arg0);
}
来看看获取RingBuffer上的一个可用位置,先看看单生产者SingleProducerSequencer.next()方法。
//SingleProducerSequencer.java
/**
* @see Sequencer#next()
*/
@Override
public long next()
{
return next(1);
} /**
* @see Sequencer#next(int)
*/
@Override
public long next(int n)
{
if (n < 1 || n > bufferSize)
{
throw new IllegalArgumentException("n must be > 0 and < bufferSize");
}
// 获取上次申请最后的序列值
long nextValue = this.nextValue;
// n=1,得到本次需要申请的序列值
long nextSequence = nextValue + n;
// 可能发生绕环的点,本次申请值 - 环形一圈长度
long wrapPoint = nextSequence - bufferSize;
// 数值最小的序列值,理解为最慢消费者
long cachedGatingSequence = this.cachedValue;
// 序列值初始值是 -1 ,只有wrapPoint 大于 cachedGatingSequence 将发生绕环行为,生产者超一圈从后方追上消费者,生产者覆盖未消费的情况。
// 没有空坑位,将进入循环等待。
if (wrapPoint > cachedGatingSequence || cachedGatingSequence > nextValue)
{
cursor.setVolatile(nextValue); // StoreLoad fence long minSequence;
// 只有当消费者消费,向前移动后,才能跳出循环
// 每次重新获取消费者序列最小值进行轮询判断
while (wrapPoint > (minSequence = Util.getMinimumSequence(gatingSequences, nextValue)))
{
LockSupport.parkNanos(1L);
}
// 当消费者消费后,更新缓存的最小序号
this.cachedValue = minSequence;
}
// 将成功申请的序号赋值给对象实例变量
this.nextValue = nextSequence; return nextSequence;
}
next获取可以写入的序列号,回到RingBuffer的publishEvent方法,执行translateAndPublish方法,进行发布操作。
//RingBuffer.java
private void translateAndPublish(EventTranslator<E> translator, long sequence)
{
try
{
translator.translateTo(get(sequence), sequence);
}
finally
{
sequencer.publish(sequence);
}
}
translator.translateTo()对EventTranslator接口的实现。将数据放置好,进行发布。
//SingleProducerSequencer.java
/**
* @see Sequencer#publish(long)
*/
@Override
public void publish(long sequence)
{
// 更新Sequencer内部游标值
cursor.set(sequence);
// 当生产者发布新事件后,将通知等待的EventProcessor,可以进行消费
waitStrategy.signalAllWhenBlocking();
} // BlockingWaitStrategy.java
@Override
public void signalAllWhenBlocking()
{
synchronized (mutex)
{
mutex.notifyAll();
}
}
到此单生产者发布流程已经讲完。还是那句话,很简单,两步操作先去获取RingBuffer上的一个可用位置,第二步在可用位置上发布数据。
多生产者发布流程:
我们简单看下,前面和单生产者发布流程一样,实现接口AbstractSequencer,还是next()方法,我们来看。
//MultiProducerSequencer.java
/**
* @see Sequencer#next()
*/
@Override
public long next()
{
return next(1);
} /**
* @see Sequencer#next(int)
*/
@Override
public long next(int n)
{
if (n < 1 || n > bufferSize)
{
throw new IllegalArgumentException("n must be > 0 and < bufferSize");
} long current;
long next; do
{
// 当前游标值,初始化时是-1
current = cursor.get();
next = current + n; long wrapPoint = next - bufferSize;
long cachedGatingSequence = gatingSequenceCache.get(); if (wrapPoint > cachedGatingSequence || cachedGatingSequence > current)
{
long gatingSequence = Util.getMinimumSequence(gatingSequences, current); if (wrapPoint > gatingSequence)
{
LockSupport.parkNanos(1); // TODO, should we spin based on the wait strategy?
continue;
} gatingSequenceCache.set(gatingSequence);
}
else if (cursor.compareAndSet(current, next))
{
break;
}
}
while (true); return next;
}
可以看到多生产者发布流程和单生产者发布流程区别不大,最后当然还是调用publish发布,publish有点区别,我们来看。
/**
* @see Sequencer#publish(long)
*/
@Override
public void publish(final long sequence)
{
//多生产者是采用availableBuffer数组设置
setAvailable(sequence); waitStrategy.signalAllWhenBlocking();
} /**
* @see Sequencer#publish(long, long)
*/
@Override
public void publish(long lo, long hi)
{
for (long l = lo; l <= hi; l++)
{
setAvailable(l);
}
waitStrategy.signalAllWhenBlocking();
}
对比SingleProducerSequencer的publish,MultiProducerSequencer的publish没有设置cursor,而是将内部使用的availableBuffer数组对应位置进行设置。availableBuffer是一个记录RingBuffer槽位状态的数组,通过对序列值sequence&bufferSize-1,获得槽位号,再通过位运算,获取序列值所在的圈数,进行设置。使用更高效的位与和右移操作。
private void setAvailable(final long sequence)
{
// calculateIndex 与&, calculateAvailabilityFlag 移位操作
setAvailableBufferValue(calculateIndex(sequence), calculateAvailabilityFlag(sequence));
} private void setAvailableBufferValue(int index, int flag)
{
// 使用Unsafe更新属性,因为是直接操作内存,所以需要计算元素位置对应的内存位置buffer地址
long bufferAddress = (index * SCALE) + BASE;
// availableBuffer是标志可用位置的int数组,初始全为-1
UNSAFE.putOrderedInt(availableBuffer, bufferAddress, flag);
} private int calculateAvailabilityFlag(final long sequence)
{
return (int) (sequence >>> indexShift);
} private int calculateIndex(final long sequence)
{
return ((int) sequence) & indexMask;
}
到此,多生产者发布流程也讲完了,是不是很easy,如果大家有问题,评论区我们一起讨论。
三、消费者
老规矩,再来一张图,这个就比较简单了。
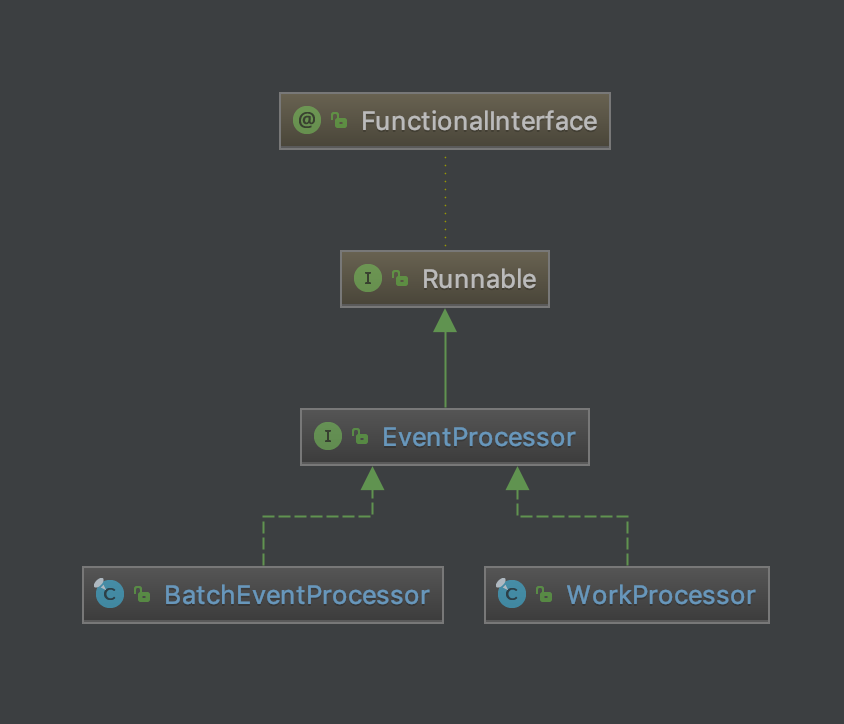
EventProcessor是整个消费者事件处理框架,EventProcessor接口继承了Runnable接口,主要有两种实现:单线程批量处理BatchEventProcessor和多线程处理WorkProcessor。
在使用Disruptor帮助类构建消费者时,使用handleEventsWith方法传入多个EventHandler,内部使用多个BatchEventProcessor关联多个线程执行。这种情况类似JMS中的发布订阅模式,同一事件会被多个消费者并行消费。适用于同一事件触发多种操作。
而使用Disruptor的handleEventsWithWorkerPool传入多个WorkHandler时,内部使用多个WorkProcessor关联多个线程执行。这种情况类似JMS的点对点模式,同一事件会被一组消费者其中之一消费。适用于提升消费者并行处理能力。
BatchEventProcessor单线程批处理事件(理解为广播消费,重复消费)
// EventHandlerGroup.java
public EventHandlerGroup<T> then(final EventHandler<? super T>... handlers)
{
return handleEventsWith(handlers);
}
public EventHandlerGroup<T> handleEventsWith(final EventHandler<? super T>... handlers)
{
return disruptor.createEventProcessors(sequences, handlers);
}
//Disruptor.java
// barrierSequences是EventHandlerGroup实例的序列,就是上一个事件处理者组的序列
EventHandlerGroup<T> createEventProcessors(
final Sequence[] barrierSequences,
final EventHandler<? super T>[] eventHandlers)
{
checkNotStarted();
// processorSequences本次事件处理器组的序列组
final Sequence[] processorSequences = new Sequence[eventHandlers.length];
final SequenceBarrier barrier = ringBuffer.newBarrier(barrierSequences); for (int i = 0, eventHandlersLength = eventHandlers.length; i < eventHandlersLength; i++)
{
final EventHandler<? super T> eventHandler = eventHandlers[i]; final BatchEventProcessor<T> batchEventProcessor =
new BatchEventProcessor<>(ringBuffer, barrier, eventHandler); if (exceptionHandler != null)
{
batchEventProcessor.setExceptionHandler(exceptionHandler);
} consumerRepository.add(batchEventProcessor, eventHandler, barrier);
processorSequences[i] = batchEventProcessor.getSequence();
}
// 每次添加完事件处理器后,更新门控序列,用于后续调用链的添加判断。
updateGatingSequencesForNextInChain(barrierSequences, processorSequences); return new EventHandlerGroup<>(this, consumerRepository, processorSequences);
} // 门控,是指后续消费链的消费,不能超过前边。
private void updateGatingSequencesForNextInChain(final Sequence[] barrierSequences, final Sequence[] processorSequences)
{
if (processorSequences.length > 0)
{
//GatingSequences一直保存消费链末端消费者的序列组
ringBuffer.addGatingSequences(processorSequences);
for (final Sequence barrierSequence : barrierSequences)
{
ringBuffer.removeGatingSequence(barrierSequence);
}
// 取消标记上一组消费者为消费链末端
consumerRepository.unMarkEventProcessorsAsEndOfChain(barrierSequences);
}
}
BatchEventProcessor构建消费者链时的逻辑都在createEventProcessors这个方法中。
先简单说下ConsumerRepository,这个类主要保存消费者的各种关系,如通过EventHandler引用获取EventProcessorInfo信息,通过Sequence获取ConsumerInfo信息等。
因为要使用引用做key,所以数据结构使用IdentityHashMap。
IdentityHashMap使用的是==比较key的值,而HashMap使用的是equals()HashMap使用的是hashCode()查找位置,IdentityHashMap使用的是System.identityHashCode(object)IdentityHashMap理论上来说速度要比HashMap快一点另外一点呢就是
IdentityHashMap中key能重复,但需要注意一点的是key比较的方法是==,所以若要存放两个相同的key,就需要存放不同的地址。
这个createEventProcessors方法接收两个参数,barrierSequences表示当前消费者组的屏障序列数组,如果当前消费者组是第一组,则取一个空的序列数组;否则,barrierSequences就是上一组消费者组的序列数组。createEventProcessors方法的另一个参数eventHandlers,这个参数是代表事件消费逻辑的EventHandler数组。
Disruptor为每个EventHandler实现类都创建了一个对应的BatchEventProcessor,所有消费者共用一个SequenceBarrier。
在构建BatchEventProcessor时需要以下传入三个构造参数:dataProvider是数据存储结构如RingBuffer;sequenceBarrier用于跟踪生产者游标,协调数据处理;eventHandler是用户实现的事件处理器,也就是实际的消费者。
//BatchEventProcessor.java
@Override
public void run()
{
if (running.compareAndSet(IDLE, RUNNING))
{
sequenceBarrier.clearAlert(); notifyStart();
try
{
if (running.get() == RUNNING)
{
processEvents();
}
}
finally
{
notifyShutdown();
running.set(IDLE);
}
}
else
{
// This is a little bit of guess work. The running state could of changed to HALTED by
// this point. However, Java does not have compareAndExchange which is the only way
// to get it exactly correct.
if (running.get() == RUNNING)
{
throw new IllegalStateException("Thread is already running");
}
else
{
earlyExit();
}
}
} private void processEvents()
{
T event = null;
long nextSequence = sequence.get() + 1L; while (true)
{
try
{
// 当前能够使用的最大值
// 使用给定的等待策略去等待下一个序列可用
final long availableSequence = sequenceBarrier.waitFor(nextSequence);
if (batchStartAware != null)
{
batchStartAware.onBatchStart(availableSequence - nextSequence + 1);
} // 批处理
// 消费的偏移量大于上次消费记录
while (nextSequence <= availableSequence)
{
event = dataProvider.get(nextSequence);
eventHandler.onEvent(event, nextSequence, nextSequence == availableSequence);
nextSequence++;
} // eventHandler处理完毕后,更新当前序号
sequence.set(availableSequence);
}
catch (final TimeoutException e)
{
notifyTimeout(sequence.get());
}
catch (final AlertException ex)
{
if (running.get() != RUNNING)
{
break;
}
}
catch (final Throwable ex)
{
exceptionHandler.handleEventException(ex, nextSequence, event);
sequence.set(nextSequence);
nextSequence++;
}
}
}
我们再来看看SequenceBarrier实现类ProcessingSequenceBarrier的代码是如何实现waitFor方法。
final class ProcessingSequenceBarrier implements SequenceBarrier
{
/**
* 等待可用消费时,指定的等待策略
*/
private final WaitStrategy waitStrategy;
/**
* 依赖的上组消费者的序号,如果当前为第一组则为cursorSequence(即生产者发布游标序列)
* 否则使用FixedSequenceGroup封装上组消费者序列
*/
private final Sequence dependentSequence;
/**
* 当触发halt时,将标记alerted为true
*/
private volatile boolean alerted = false;
/**
* AbstractSequencer中的cursor引用,记录当前发布者发布的最新位置
*/
private final Sequence cursorSequence;
/**
* MultiProducerSequencer 或 SingleProducerSequencer
*/
private final Sequencer sequencer; ProcessingSequenceBarrier(
final Sequencer sequencer,
final WaitStrategy waitStrategy,
final Sequence cursorSequence,
final Sequence[] dependentSequences)
{
this.sequencer = sequencer;
this.waitStrategy = waitStrategy;
this.cursorSequence = cursorSequence;
// 依赖的上一组序列长度,第一次是0
if (0 == dependentSequences.length)
{
dependentSequence = cursorSequence;
}
// 将上一组序列数组复制成新数组保存,引用不变
else
{
dependentSequence = new FixedSequenceGroup(dependentSequences);
}
} @Override
public long waitFor(final long sequence)
throws AlertException, InterruptedException, TimeoutException
{
// 检查是否停止服务
checkAlert();
// 获取最大可用序号 sequence为给定序号,一般为当前序号+1,cursorSequence记录生产者最新位置,
long availableSequence = waitStrategy.waitFor(sequence, cursorSequence, dependentSequence, this); if (availableSequence < sequence)
{
return availableSequence;
}
// 返回已发布最高的序列值,将对每个序号进行校验
return sequencer.getHighestPublishedSequence(sequence, availableSequence);
}
我们再来看看等待策略WaitStrategy#waitFor
//BlockingWaitStrategy.java
public final class BlockingWaitStrategy implements WaitStrategy
{
private final Object mutex = new Object(); @Override
public long waitFor(long sequence, Sequence cursorSequence, Sequence dependentSequence, SequenceBarrier barrier)
throws AlertException, InterruptedException
{
long availableSequence;
// 当前游标小于给定序号,也就是无可用事件
if (cursorSequence.get() < sequence)
{
//也就是只有等待策略才会用锁,其他使用CAS,这就是前文提到的高效原因
synchronized (mutex)
{
// 当给定的序号大于生产者游标序号时,进行等待
while (cursorSequence.get() < sequence)
// 循环等待,在Sequencer中publish进行唤醒;等待消费时也会在循环中定时唤醒。
{
barrier.checkAlert();
mutex.wait();
}
}
}
while ((availableSequence = dependentSequence.get()) < sequence)
{
barrier.checkAlert();
ThreadHints.onSpinWait();
} return availableSequence;
}
WorkProcessor多线程处理事件(理解为集群消费)
WorkProcessor的原理和BatchEventProcessor类似,只是多了workSequence用来保存同组共用的处理序列。在更新workSequence时,涉及多线程操作,所以使用CAS进行更新。
//WorkProcessor.java
@Override
public void run()
{
if (!running.compareAndSet(false, true))
{
throw new IllegalStateException("Thread is already running");
}
sequenceBarrier.clearAlert(); notifyStart(); boolean processedSequence = true;
long cachedAvailableSequence = Long.MIN_VALUE;
long nextSequence = sequence.get();
T event = null;
while (true)
{
try
{
// if previous sequence was processed - fetch the next sequence and set
// that we have successfully processed the previous sequence
// typically, this will be true
// this prevents the sequence getting too far forward if an exception
// is thrown from the WorkHandler
// 表示nextSequence序号的处理情况(不区分正常或是异常处理)。只有处理过,才能申请下一个序号。
if (processedSequence)
{
processedSequence = false;
do
{
// 同组中多个消费线程有可能会争抢一个序号,使用CAS避免使用锁。
// 同一组使用一个workSequence,WorkProcessor不断申请下一个可用序号,对workSequence设置成功才会实际消费。
nextSequence = workSequence.get() + 1L;
sequence.set(nextSequence - 1L);
}
while (!workSequence.compareAndSet(nextSequence - 1L, nextSequence));
}
// 缓存的可用序号比要处理的序号大,才能进行处理
if (cachedAvailableSequence >= nextSequence)
{
event = ringBuffer.get(nextSequence);
workHandler.onEvent(event);
processedSequence = true;
}
// 更新缓存的可用序列。这个cachedAvailableSequence只用在WorkProcessor实例内,不同实例的缓存可能是不一样
else
{
// 和单线程模式类似,返回的也是最大可用序号
cachedAvailableSequence = sequenceBarrier.waitFor(nextSequence);
}
}
catch (final TimeoutException e)
{
notifyTimeout(sequence.get());
}
catch (final AlertException ex)
{
if (!running.get())
{
break;
}
}
catch (final Throwable ex)
{
// handle, mark as processed, unless the exception handler threw an exception
exceptionHandler.handleEventException(ex, nextSequence, event);
processedSequence = true;
}
} notifyShutdown(); running.set(false);
}
总结一波:
BatchEventProcessor主要用于处理单线程并行任务,同一消费者组的不同消费者会接收相同的事件,并在所有事件处理完毕后进入下一消费者组进行处理(是不是类似JUC里的Phaser、CyclicBarrier或CountDownLatch呢)。WorkProcessor通过WorkerPool管理多个WorkProcessor,达到多线程处理事件的目的,同一消费者组的多个WorkProcessor不会处理同一个事件。通过选择不同的WaitStragegy实现,可以控制消费者在没有可用事件处理时的等待策略。
应用场景总结
BatchEventProcessor
- 对Event的处理顺序有需求
- 单个Event的处理非常快(因为单线程)
WorkProcessor
- 对Event的处理顺序没有要求,虽然是顺序的消费,但是最终的消费先后取决于线程的调度,没有办法保证
- 单个Event的处理速度相对较慢(因为多线程)
具体的核心类分析,可以参考 https://github.com/Sonion/disroptor 里面有分析和注释,写个demo,打个断点,再看看核心类和方法,Disruptor 源码还是简单的,主要是环形队列,循环写入,不用GC回收,还有一些缓存行优化,无锁等处理是值得学习和思考的。
参考资料:
1、参考demo可以看这里
https://www.cnblogs.com/xiangnanl/p/9955714.html#4114850
2、简单资料
https://blog.csdn.net/changong28/article/details/43637679
http://brokendreams.iteye.com/category/349033
Disruptor源码解读的更多相关文章
- SDWebImage源码解读之SDWebImageDownloaderOperation
第七篇 前言 本篇文章主要讲解下载操作的相关知识,SDWebImageDownloaderOperation的主要任务是把一张图片从服务器下载到内存中.下载数据并不难,如何对下载这一系列的任务进行设计 ...
- SDWebImage源码解读 之 NSData+ImageContentType
第一篇 前言 从今天开始,我将开启一段源码解读的旅途了.在这里先暂时不透露具体解读的源码到底是哪些?因为也可能随着解读的进行会更改计划.但能够肯定的是,这一系列之中肯定会有Swift版本的代码. 说说 ...
- SDWebImage源码解读 之 UIImage+GIF
第二篇 前言 本篇是和GIF相关的一个UIImage的分类.主要提供了三个方法: + (UIImage *)sd_animatedGIFNamed:(NSString *)name ----- 根据名 ...
- SDWebImage源码解读 之 SDWebImageCompat
第三篇 前言 本篇主要解读SDWebImage的配置文件.正如compat的定义,该配置文件主要是兼容Apple的其他设备.也许我们真实的开发平台只有一个,但考虑各个平台的兼容性,对于框架有着很重要的 ...
- SDWebImage源码解读_之SDWebImageDecoder
第四篇 前言 首先,我们要弄明白一个问题? 为什么要对UIImage进行解码呢?难道不能直接使用吗? 其实不解码也是可以使用的,假如说我们通过imageNamed:来加载image,系统默认会在主线程 ...
- SDWebImage源码解读之SDWebImageCache(上)
第五篇 前言 本篇主要讲解图片缓存类的知识,虽然只涉及了图片方面的缓存的设计,但思想同样适用于别的方面的设计.在架构上来说,缓存算是存储设计的一部分.我们把各种不同的存储内容按照功能进行切割后,图片缓 ...
- SDWebImage源码解读之SDWebImageCache(下)
第六篇 前言 我们在SDWebImageCache(上)中了解了这个缓存类大概的功能是什么?那么接下来就要看看这些功能是如何实现的? 再次强调,不管是图片的缓存还是其他各种不同形式的缓存,在原理上都极 ...
- AFNetworking 3.0 源码解读 总结(干货)(下)
承接上一篇AFNetworking 3.0 源码解读 总结(干货)(上) 21.网络服务类型NSURLRequestNetworkServiceType 示例代码: typedef NS_ENUM(N ...
- AFNetworking 3.0 源码解读 总结(干货)(上)
养成记笔记的习惯,对于一个软件工程师来说,我觉得很重要.记得在知乎上看到过一个问题,说是人类最大的缺点是什么?我个人觉得记忆算是一个缺点.它就像时间一样,会自己消散. 前言 终于写完了 AFNetwo ...
随机推荐
- Centos7 samba 匿名共享 简单config
安装Samba yum install samba samba-client samba-common -y 备份原始的Samba配置文件: mv /etc/samba/smb.conf /etc/s ...
- Office 佳能MP259打印EXCEL线条歪曲,字迹模糊怎么办
这大概是墨盒的缘故,判断方法很简单,随便找一个文档,点击打印,属性 在维护选项卡中把清洗和打印头对齐做一遍(一般字迹模糊可以通过清洗解决,线条歪曲可以通过打印头对齐解决),如果你打印的结果是纸张边 ...
- Angularjs1.x 项目结构
大部分的项目结构是以 directives , service, controller 为基础来搭建的项目架构的,但这里更偏向于以应用场景来进行项目架构,因此这里的文件夹结构可能与您之前遇到的结构不同 ...
- 怎样在win8系统下建立wifi热点
2012年10月26日,微软正式推出Windows 8操作系统,不少用户也都升级到了最新的Win8.大家知道.在Win7系统下,我们非常方便的就在命令提示符下建立了WIFI热点.那么Win8上是 ...
- Lint工具去除Android工程里不再需要的资源
摘要: 在项目开发过程中常常会不断改UI设计,于是在定稿要发布的前夕,发现有好多不再需要的资源文件存在,发布的包会把这些无用的资源都包含在里面,造成APK的下载包过大.可以通过Android SDK自 ...
- Scala界面事件处理
演示样例代码: import scala.swing.SimpleSwingApplication import scala.swing.MainFrame import scala.swing.Bu ...
- C++获取时间的方法
//方案- 长处:仅使用C标准库:缺点:仅仅能精确到秒级 #include <time.h> #include <stdio.h> int main( void ) { ...
- 编译android framework的例子【转】
本文转载自:http://blog.csdn.net/brucexu1978/article/details/7610358 在开发过程中,尤其是Framework相关开发时,有时候需要重新编译资源文 ...
- YTU 2635: P4 游戏中的Human角色
2635: P4 游戏中的Human角色 时间限制: 1 Sec 内存限制: 128 MB 提交: 524 解决: 328 题目描述 在一个平面打斗游戏中,任何的角色(Role)都有血量(bloo ...
- Ubuntu14.04 x64 zabbix 3.0 安装
U buntu14.04 x64 zabbix 3.0 安装 苦于网上的文档很多,但是对初学者来说,很多都搭建不成功,我重新安装一下.记录一下. 下载deb wget http://repo.za ...