机器学习--DIY笔记与感悟--①K-临近算法(2)
上一篇博客我手动写了KNN算法,并且之后用手写的算法预测了约会的成功率。
而今天,我在大神博客的指导下调用sklearn这个库来预测图片的内容。
一、前期准备
由于我这里使用的是mac版本,而sklearn这个库很迷,装的时候老是给我报错,,所以我们装的时候不能单独的使用pip,要在后面加一行命令:
sudo pip install -U numpy scipy scikit-learn --ignore-installed six
要用我上面的写法,具体原因是因为系统保护,(吧啦吧啦)所以跟mac的版本有关。不仅是这个sklearn,装tensorflow的时候也可以在后面添加 --ignore-installed six 来达到直接pip的目的。
具体的blog参照: http://blog.csdn.net/id314846818/article/details/58624393
而当我们成功安装sklearn库后,我们可以在任意目录下编辑.py文件:
print(__doc__) # Author: Nelle Varoquaux <nelle.varoquaux@gmail.com>
# Alexandre Gramfort <alexandre.gramfort@inria.fr>
# Licence: BSD import numpy as np
import matplotlib.pyplot as plt
from matplotlib.collections import LineCollection from sklearn.linear_model import LinearRegression
from sklearn.isotonic import IsotonicRegression
from sklearn.utils import check_random_state n = 100
x = np.arange(n)
rs = check_random_state(0)
y = rs.randint(-50, 50, size=(n,)) + 50. * np.log(1 + np.arange(n)) ###############################################################################
# Fit IsotonicRegression and LinearRegression models ir = IsotonicRegression() y_ = ir.fit_transform(x, y) lr = LinearRegression()
lr.fit(x[:, np.newaxis], y) # x needs to be 2d for LinearRegression ###############################################################################
# plot result segments = [[[i, y[i]], [i, y_[i]]] for i in range(n)]
lc = LineCollection(segments, zorder=0)
lc.set_array(np.ones(len(y)))
lc.set_linewidths(0.5 * np.ones(n)) fig = plt.figure()
plt.plot(x, y, 'r.', markersize=12)
plt.plot(x, y_, 'g.-', markersize=12)
plt.plot(x, lr.predict(x[:, np.newaxis]), 'b-')
plt.gca().add_collection(lc)
plt.legend(('Data', 'Isotonic Fit', 'Linear Fit'), loc='lower right')
plt.title('Isotonic regression')
plt.show()
然后python 这个文件,如果看到结果:
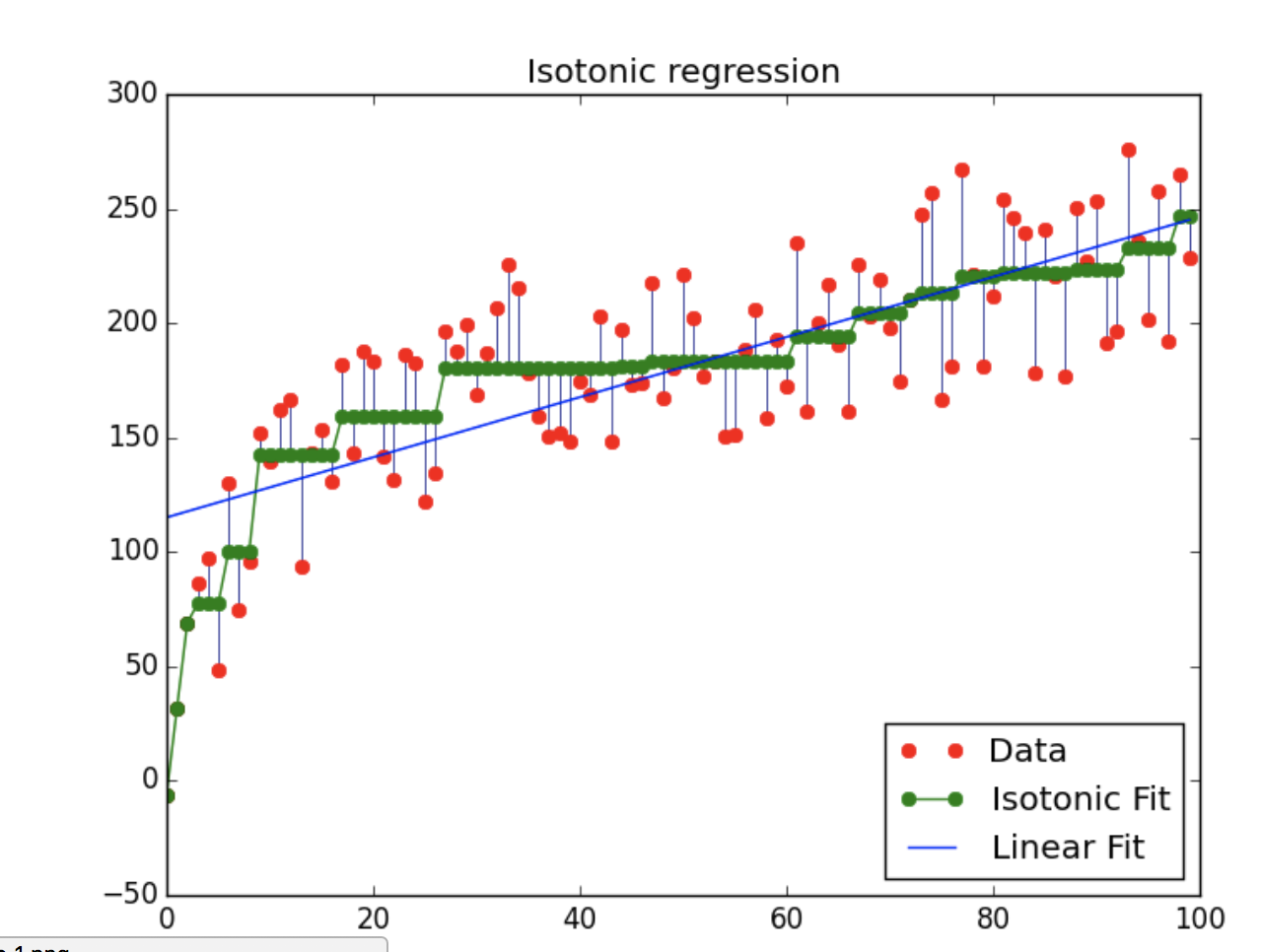
说明安装成功。
二、任务详情
之后我们就需要用这个库来写点真正的东西了。
这里我们要预测的内容为数字。
我们开始的时候会给出一堆文件:
文件下载地址为:https://github.com/Jack-Cherish/Machine-Learning/tree/master/kNN/3.%E6%95%B0%E5%AD%97%E8%AF%86%E5%88%AB
例如我打开其中的0_0.txt,得到
而1_40.txt对应 :
也就是说文件的名字0_0的‘_’前的那个数字对应了我们文本里的结果,而后面的那个数字是结果为0的文件的编号。
之后我们可以利用KNN进行预测。
三、代码详情
开始的时候我们要对这个32*32的01矩阵进行处理,将其放入一个一维矩阵中。
#coding:utf-8
import numpy as np
import operator
from os import listdir
from sklearn.neighbors import KNeighborsClassifier as KNN def image_vector(filename):
zeroVector = np.zeros((1,1024))
f = open(filename)
for i in range(32):
listRead = f.readline()
for j in range(32):
zeroVector[0,32*i+j] = int(listRead[j])
#zeroVector里面的[0,n]:0代表第0行,n代表第n列个数字(因为zeros可以有m行n列)
return zeroVector
#将32*32的矩阵转移到一个一维矩阵中
之后调用函数进行预测,这里重点要关注fit函数、predict函数,
def KNN_Process():
trainNameClass = []
trainingFileList = listdir('trainingDigits')
fileCount = len(trainingFileList)
#返回目录下的训练文件个数
trainMat = np.zeros((fileCount,1024),int)
#创建fileCount行,1024列的二维矩阵(用来保存所有训练集)
for i in range(fileCount):
currentFileName = trainingFileList[i]
#当前文件的文件名称
trainNameNumber = int(trainingFileList[i].split('_')[0])
#取名称的'-'前面的内容
trainNameClass.append(trainNameNumber)
#将数字append到数组中
url = 'trainingDigits/' + currentFileName
#print url
trainMat[i,:] = image_vector(url)
#将每个图片的1024个数据均存在trainMat中,构成一个大小为fileCount*1024的矩阵
KnnContain = KNN(n_neighbors = 3, algorithm = 'auto')
#创建knn模型容器 KnnContain.fit(trainMat,trainNameClass)
#用fit函数将train的矩阵与label对应起来 testFileList = listdir('testDigits')
#返回testDigits目录下的文件
errorCount = 0.0
#错误量
testCount = len(testFileList)
#test数据的个数
for i in range(testCount):
currentTestName = testFileList[i]
#当前第i个test文件的名字
testClassNumber = int(currentTestName.split('_')[0])
#获取当前文件的对应数字
testVector = image_vector('testDigits/%s' %(currentTestName))
#将当前test的1024个数据存入testVector中
KnnResult = KnnContain.predict(testVector)
print "分类结果为:%d\t真实结果为:%d\t" % (KnnResult,testClassNumber)
if KnnResult != testClassNumber:
errorCount += 1.0
print "本次model的成功率为: %",(float(testCount) - errorCount)/float(testCount)*100
这里是利用了
KnnContain = KNN(n_neighbors = 3, algorithm = 'auto')
将model抽象到KnnContain中,然后调用fit将training data的内容和value对应起来。而这个n_neighbors为knn中的k值。
详细的官方解释见:http://scikit-learn.org/stable/auto_examples/neighbors/plot_classification.html#sphx-glr-auto-examples-neighbors-plot-classification-py
源代码见:https://github.com/scikit-learn/scikit-learn/blob/a24c8b46/sklearn/neighbors/base.py#L751
之后附上全部代码:
#coding:utf-8
import numpy as np
import operator
from os import listdir
from sklearn.neighbors import KNeighborsClassifier as KNN def image_vector(filename):
zeroVector = np.zeros((1,1024))
f = open(filename)
for i in range(32):
listRead = f.readline()
for j in range(32):
zeroVector[0,32*i+j] = int(listRead[j])
#zeroVector里面的[0,n]:0代表第0行,n代表第n列个数字(因为zeros可以有m行n列)
return zeroVector
#将32*32的矩阵转移到一个一维矩阵中 def KNN_Process():
trainNameClass = []
trainingFileList = listdir('trainingDigits')
fileCount = len(trainingFileList)
#返回目录下的训练文件个数
trainMat = np.zeros((fileCount,1024),int)
#创建fileCount行,1024列的二维矩阵(用来保存所有训练集)
for i in range(fileCount):
currentFileName = trainingFileList[i]
#当前文件的文件名称
trainNameNumber = int(trainingFileList[i].split('_')[0])
#取名称的'-'前面的内容
trainNameClass.append(trainNameNumber)
#将数字append到数组中
url = 'trainingDigits/' + currentFileName
#print url
trainMat[i,:] = image_vector(url)
#将每个图片的1024个数据均存在trainMat中,构成一个大小为fileCount*1024的矩阵
KnnContain = KNN(n_neighbors = 3, algorithm = 'auto')
#创建knn模型容器 KnnContain.fit(trainMat,trainNameClass)
#用fit函数将train的矩阵与label对应起来 testFileList = listdir('testDigits')
#返回testDigits目录下的文件
errorCount = 0.0
#错误量
testCount = len(testFileList)
#test数据的个数
for i in range(testCount):
currentTestName = testFileList[i]
#当前第i个test文件的名字
testClassNumber = int(currentTestName.split('_')[0])
#获取当前文件的对应数字
testVector = image_vector('testDigits/%s' %(currentTestName))
#将当前test的1024个数据存入testVector中
KnnResult = KnnContain.predict(testVector)
print "分类结果为:%d\t真实结果为:%d\t" % (KnnResult,testClassNumber)
if KnnResult != testClassNumber:
errorCount += 1.0
print "本次model的成功率为: %",(float(testCount) - errorCount)/float(testCount)*100 if __name__ == '__main__': KNN_Process()
还是老样子,我这里使用了python2.7.10的版本。
得到结果为
可以看到预测的成功率达到了98.7,说明效果还是很好的。
而这个sklearn里面的内容还是博大精深的,等我更深入学习后再把体会更新到这里。
在此感谢大神的blog,参考自http://blog.csdn.net/c406495762/article/details/75172850
机器学习--DIY笔记与感悟--①K-临近算法(2)的更多相关文章
- 机器学习--DIY笔记与感悟--①K-临近算法
##“计算机出身要紧跟潮流” 机器学习作为如今发展的趋势需要被我们所掌握.而今我也需要开始learn机器学习,并将之后的所作所想记录在此. 今天我开始第一课--K临近算法. 一.k-临近的基础概念理解 ...
- 机器学习--DIY笔记与感悟--②决策树(1)
在完成了K临近之后,今天我们开始下一个算法--->决策树算法. 一.决策树基础知识 如果突然问你"有一个陌生人叫X,Ta今天需要带伞吗?", 你一定会觉得这个问题就像告诉你& ...
- 机器学习学习笔记之一:K最近邻算法(KNN)
算法 假定数据有M个特征,则这些数据相当于在M维空间内的点 \[X = \begin{pmatrix} x_{11} & x_{12} & ... & x_{1M} \\ x_ ...
- 秒懂机器学习---k临近算法(KNN)
秒懂机器学习---k临近算法(KNN) 一.总结 一句话总结: 弄懂原理,然后要运行实例,然后多解决问题,然后想出优化,分析优缺点,才算真的懂 1.KNN(K-Nearest Neighbor)算法的 ...
- 机器学习(Machine Learning)算法总结-K临近算法
一.算法详解 1.什么是K临近算法 Cover 和 Hart在1968年提出了最初的临近算法 属于分类(classification)算法 邻近算法,或者说K最近邻(kNN,k-NearestNeig ...
- [Machine-Learning] K临近算法-简单例子
k-临近算法 算法步骤 k 临近算法的伪代码,对位置类别属性的数据集中的每个点依次执行以下操作: 计算已知类别数据集中的每个点与当前点之间的距离: 按照距离递增次序排序: 选取与当前点距离最小的k个点 ...
- K临近算法
K临近算法原理 K临近算法(K-Nearest Neighbor, KNN)是最简单的监督学习分类算法之一.(有之一吗?) 对于一个应用样本点,K临近算法寻找距它最近的k个训练样本点即K个Neares ...
- 机器学习实战笔记(Python实现)-01-K近邻算法(KNN)
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- 机器学习简要笔记(三)-KNN算法
#coding:utf-8 import numpy as np import operator def classify(intX,dataSet,labels,k): ''' KNN算法 ''' ...
随机推荐
- MapReduce编程实战之“调试”和"调优"
本篇内容 在上一篇的"初识"环节,我们已经在本地和Hadoop集群中,成功的执行了几个MapReduce程序,对MapReduce编程,已经有了最初的理解. 在本篇文章中,我们对M ...
- Thinking in React(翻译)
下面是React官方文档中的Thinking inReact文章的翻译,第一次翻译英文的文章,肯定有非常多不对的地方,还望多多包涵. 原文地址:https://facebook.github.io/r ...
- 微信小程序 - 提取字体图标与其优化
微信小程序,无论是字体图标还是图标,都差不多,只不过是为了以后字体图标修改方便,或者加效果方便而使用它而已! 1. 下载font-awesome http://fontawesome.dashgame ...
- 深入JVM系列(二)之GC机制、收集器与GC调优(转)
一.回顾JVM内存分配 需要了解更多内存模式与内存分配的,请看 深入JVM系列(一)之内存模型与内存分配 1.1.内存分配: 1.对象优先在EDEN分配2.大对象直接进入老年代 3.长期存活的对象 ...
- v-bind指令
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Storm项目:流数据监控1《设计文档…
博客公告: (1)本博客全部博客文章搬迁至<博客虫>http://blogchong.com/ (2)文章相应的源代码下载链接參考博客虫站点首页的"代码GIT". (3 ...
- ERROR 1366 (HY000): Incorrect string value: '\xD6\xD0\xCE\xC4' for column XXX at row 1
本错误为:该列的插入格式有误 修改该表中该列的字符集为utf-8 网上办法: )不能插入中文解决办法: 向表中插入中文然后有错误. mysql> insert into users values ...
- intellij IDEA 更新java后不用重启tomcat
最近项目大了,每次修改后重启都要等和很久,那个煎熬…… 为了解决这个问题,万能的Google 装了这个 JREBEL 5.63最新的 安装步骤: 一.IDEA在线搜索 jrebel 安装 二.破 ...
- Studio 3T for MongoDB连接51.212复制集
Studio 3T for MongoDB连接51.212复制集 [ #DirectConection Authentication Mode - Basic(MONGODB-CR or SCEAM- ...
- poj 2228 Naptime(DP的后效性处理)
\(Naptime\) \(solution:\) 这道题不做多讲,它和很多区间DP的套路一致,但是这一道题它不允许断环成链,会超时.但是我们发现如果这只奶牛跨夜休息那么它在不跨夜的二十四个小时里一定 ...