charts jupyter notebook 画简单的柱状图
数据库是mongdb
数据是58同城上发的转手记录
一 为了保证数据安全,对需要进行处理的数据进行拷贝。
> db.createCollection('test')
{ "ok" : }
> show collections
base_url
detail_info
detail_url
test
> db.detail_info.copyTo('test')
WARNING: db.eval is deprecated
二 对数据库中的数据进行处理
不要想着将数据拿出来,处理完后,在一一对应放到数据库中!
原本数据库中的地址存储的格式是:北京-昌平,北京-通州,需要拿到具体的某个区。
在jupyter notebook中进行操作。
这用到了update方法和$set 操作符。update方法的调用者是 col ,表。
for i in col.find():
zone_l = (i['zone'].split('-'))
if len(zone_l)>:
new_zone = zone_l[]
else:
new_zone = '不明'
col.update({'_id':i['_id']},{'$set':{'zone':new_zone}})
三 从数据库中读到 地址,对地址进行整理。
这里用到了set集合,和列表的count方法,内置函数zip()。很关键
zones = []
for i in col.find():
zone.append(i['zone'])
single_zone = list(set(zones))
num = [zones.count(i) for i in single_zone ]
构建charts要求格式的数据。
def foo():
l = []
for zone,n in zip(single_zone,num):
Data={
'name':zone,
'data':[n],
'type':'column',
}
l.append(Data)
return l
PS.
这里实际上可以用生成器,节省内存。
def foo():
for zone,n in zip(single_zone,num):
Data={
'name':zone,
'data':[n],
'type':'column',
}
yield Data
l = [ i for i in foo() ]
四 调用charts.plot方法。
依照固定格式传参
l = foo()
charts.plot(l,show='inline',options=dict(title=dict(text='Beijing')))
最终现实结果:
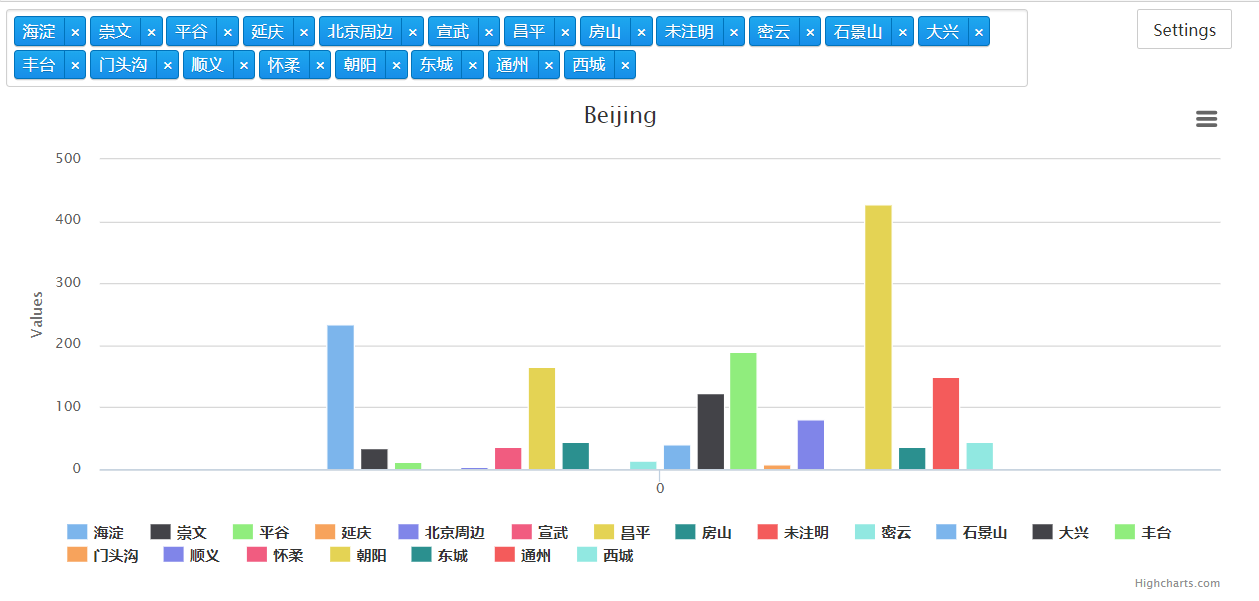
示例二: 使用aggregate(),管道函数比find()快很多。
import charts
import pymongo
client = pymongo.MongoClient('localhost',)
db = client['ganji']
col = db['test'] for i in col.find().limit():
print(i)
输出:
{'_id': ObjectId('5698f524a98063dbe9e91ca8'), 'pub_date': '2016-01-12', 'look': '-', 'area': '朝阳', 'title': '【图】95成新小冰柜转让 - 朝阳高碑店二手家电 - 北京58同城', 'url': 'http://bj.58.com/jiadian/24541664530488x.shtml', 'cates': ['北京58同城', '北京二手市场', '北京二手家电', '北京二手冰柜'], 'price': '450 元'}
{'_id': ObjectId('5698f525a98063dbe4e91ca8'), 'pub_date': '2016-01-14', 'look': '-', 'area': '朝阳', 'title': '【图】洗衣机,小冰箱,小冰柜,冷饮机 - 朝阳定福庄二手家电 - 北京58同城', 'url': 'http://bj.58.com/jiadian/24349380911041x.shtml', 'cates': ['北京58同城', '北京二手市场', '北京二手家电', '北京二手洗衣机'], 'price': '1500 元'}
aggregate()
pipeline = [
{'$match':{'area':'昌平'}},
{'$group':{'_id':{'$slice':['$cates',,]},'count':{'$sum':}}},
{'$sort':{'count':-}},
{'$limit':},
]
def get_one_area(area):
pipeline = [
{'$match':{'area':area}},
{'$group':{'_id':{'$slice':['$cates',,]},'count':{'$sum':}}},
{'$sort':{'count':-}},
{'$limit':},
]
for i in col.aggregate(pipeline):
Data = {
'name':i['_id'],
'data':[i['count']],
'type':'column'
}
yield Data
l = [i for i in get_one_area('昌平')]
import charts
options = {
'title':{
'text':'昌平'
},
'subtitle':{
'text':'前三名'
},
'yAxis':{
'title':{
'text':'数量'
}
}
}
charts.plot(l,show='inline',options=options)
输出:
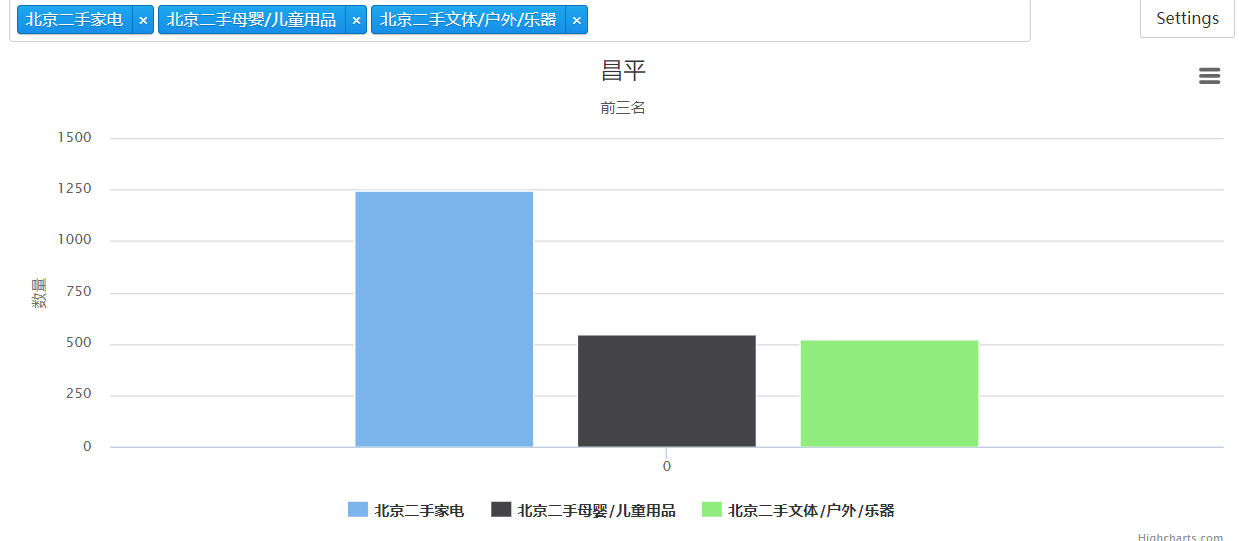
charts jupyter notebook 画简单的柱状图的更多相关文章
- 27个Jupyter Notebook使用技巧及快捷键(翻译版)
Jupyter Notebook Jupyter Notebook 以前被称为IPython notebook.Jupyter Notebook是一款能集各种分析包括代码.图片.注释.公式及自己画的图 ...
- 如何在Python中快速画图——使用Jupyter notebook的魔法函数(magic function)matplotlib inline
如何在Python中快速画图--使用Jupyter notebook的魔法函数(magic function)matplotlib inline 先展示一段相关的代码: #we test the ac ...
- jupyter notebook + pyspark 环境搭建
安装并启动jupyter 安装 Anaconda 后, 再安装 jupyter pip install jupyter 设置环境 ipython --ipython-dir= # override t ...
- pyspark 中启动 jupyter notebook
还是打算选择python学习spark编程 因为java写函数式比较复杂,scala学习曲线比较陡峭,而且sbt和eclipse和maven的结合实在是让人崩溃,经常找不到主类去执行 python以前 ...
- Jupyter notebook入门
Jupyter notebook入门 [TOC] Jupyter notebook 是一种 Web 应用,能让用户将说明文本.数学方程.代码和可视化内容全部组合到一个易于共享的文档中. Jupyter ...
- python︱Anaconda安装、简介(安装报错问题解决、Jupyter Notebook)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 安装完anaconda,就相当于安装了Pyth ...
- jupyter notebook的架构
最近项目需要改写jupyter notebook的内核,由于内功不够,英语过差,读文档真的是心痛,然后各种搜索找到了一篇不错的讲解. 转自:http://blog.just4fun.site/jupy ...
- Jupyter Notebook中的快捷键
1.快捷键 Jupyter Notebook 有两种键盘输入模式.编辑模式,允许你往单元中键入代码或文本:这时的单元框线是绿色的.命令模式,键盘输入运行程序命令:这时的单元框线是灰色. 命令模式 (按 ...
- Jupyter NoteBook功能介绍
一.Jupyter Notebook 介绍 文学编程 在介绍 Jupyter Notebook 之前,让我们先来看一个概念:文学编程 ( Literate programming ),这是由 Dona ...
随机推荐
- win10搭建Java环境
一.下载地址 jdk和jre官方网址:http://www.oracle.com/technetwork/java/javase/downloads/index.html 根据你的系统选择你需要 ...
- 使用prelu
一个使用方式:http://blog.csdn.net/xg123321123/article/details/52610919 还有一种是像relu那样写,我就是采用的这种方式,直接把名字从relu ...
- nodeJS进程管理器pm2
pm2是一个带有负载均衡功能的Node应用的进程管理器.当你要把你的独立代码利用全部的服务器上的所有CPU,并保证进程永远都活着,0秒的重载, PM2是完美的. PM2是开源的基于Nodejs的进程管 ...
- MySQL插入SQL语句后在phpmyadmin中注释显示乱码
自己写一个建一个简单的数据表,中间加了个注释,但是用PHPmyadmin打开后发现注释不对. 就先查询了一下sql 语句 发现SQL 语句并没有问题,感觉像是显示编码的问题,就先用set names ...
- please upgrade your plan to create a new private reposiory
请升级你的计划来创建一个新的私人仓库 提交仓库到github,要公开,除非买他们服务,所以把勾去掉就好了keep this code private
- ios多线程之NSOperation
使用 NSOperation的方式有两种, 一种是用定义好的两个子类: NSInvocationOperation 和 NSBlockOperation. 另一种是继承NSOperation 如果你也 ...
- 文件读写FILE类
1. 新建一个文件: FILE *f = fopen("a.txt","w+"); (1)fopen()函数介绍fopen的原型是:FILE *fopen(co ...
- Ubuntu创建应用快捷方式
Ubuntu创建应用快捷方式 新建一个.desktop文件 vi eclipse.desktop 然后又进行编辑 [Desktop Entry] Encoding=UTF-8 Name=eclipse ...
- MYSQL中批量替换某个字段的部分数据
1.修改字段里的所有含有指定字符串的文字 UPDATE 表A SET 字段B = replace(字段B, 'aaa', 'bbb') example: update table set url= ...
- python:json
json是用来传输数据的字符串,{"key1":"values1","key2":{"key3":"value ...