Selenium(九)测试用例数据分离与从文件导入数据
一.测试用例数据与代码分离
1.从之前的脚本来看,我还是把数据写在了脚本中,这样脚本的通用性很差。全局的数据其实可以从数据库、文本文件、Excel中直接读取。
2.代码和用户数据分离:

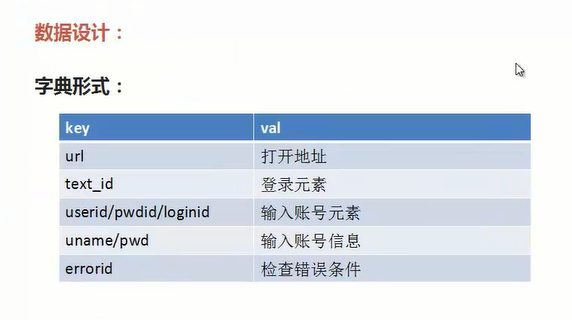
3.数据设计--以字典的形式
from selenium import webdriver
import time
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support.ui import WebDriverWait def openBrower(): #配置浏览器
webdriver_handle = webdriver.Firefox()
return webdriver_handle def openUrl(handle,url): #打开url
handle.get(url) def get_ele_times(driver,times,func):
return WebDriverWait(driver,times).until(func) #等待方法 def findElement(driver,arg):
'''
arg must be dict
1.login:登录入口
2.user_xpath:用户名
3.pwd_xpath:密码
4.login_xpath:登录按钮 return useEle,pwdEle,loginEle
'''
ele_login = get_ele_times(driver,10,lambda driver:driver.find_element_by_xpath(arg['login']))
ele_login.click()
useEle = driver.find_element_by_xpath(arg['user_xpath'])
pwdEle = driver.find_element_by_xpath(arg['pwd_xpath'])
loginEle = driver.find_element_by_xpath(arg['login_xpath'])
return useEle,pwdEle,loginEle def sendVals(eletuple,arg):
'''
ele tuple
account:uname,pwd
'''
listkey = ['uname','pwd']
i = 0
for key in listkey:
eletuple[i].send_keys('')
eletuple[i].clear()
eletuple[i].send_keys(arg[key])
i+=1
eletuple[2].click()
def checkResult(driver,text):
try:
driver.find_element_by_link_text(test)
print ("ACCOUNT AND PWD ERROR!")
except:
print ("ACCOUNT AND PWD RIGHT!") def login_test(ele_dict):
driver = openBrower()
openUrl(driver,ele_dict['url'])
driver.maximize_window() ele_tuple = findElement(driver,ele_dict) #接收字典的值 sendVals(ele_tuple,ele_dict)
checkResult(driver,ele_dict['errorid']) driver.find_element_by_link_text('退出').click() if __name__ == '__main__':
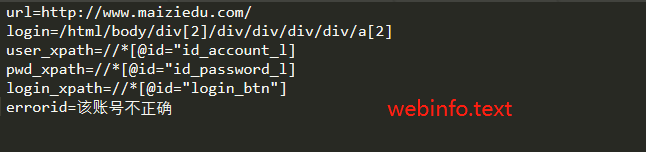
url = 'http://www.maiziedu.com/' #将数据都放入字典中
account = 'XXX'
pwd = 'maizi123456'
ele_dict = {'url':url,'login':'/html/body/div[2]/div/div/div/div/a[2]','user_xpath':'//*[@id="id_account_l"]',\
'pwd_xpath':'//*[@id="id_password_l"]','login_xpath':'//*[@id="login_btn"]',\
'errorid':'该账号不正确','uname':account,'pwd':pwd} login_test(ele_dict)
这样把用户名和密码也加入字典中是不合理的,所以要把用户名和密码抽出来单独用一个list存放:
def login_test(ele_dict,user_list):
driver = openBrower()
openUrl(driver,ele_dict['url'])
driver.maximize_window() ele_tuple = findElement(driver,ele_dict) #接收字典的值
for arg in user_list:
sendVals(ele_tuple,arg)
checkResult(driver,ele_dict['errorid']) if __name__ == '__main__':
url = 'http://www.maiziedu.com/'
account = 'XXX'
pwd = 'maizi123456'
ele_dict = {'url':url,'login':'/html/body/div[2]/div/div/div/div/a[2]','user_xpath':'//*[@id="id_account_l"]',\
'pwd_xpath':'//*[@id="id_password_l"]','login_xpath':'//*[@id="login_btn"]',\
'errorid':'该账号不正确'}
user_list = [{'uname':account,'pwd':pwd}]
login_test(ele_dict,user_list)
二.从文件导入数据

1.webinfo.py
#coding:UTF-8
import codecs def get_webinfo(path):
web_info={} #定义一个空的字典
#config=open(path)
config = codecs.open(path,'r','utf-8') #打开一个路径为path的txt文件 如果打印的话 会出现txt文件里的所有内容
for line in config: #一行一行的遍历txt文件中的内容
result = [ele.strip() for ele in line.split('=')]
'''
列表解析以'='符号为分隔,将遍历的一行的内容放在一个数组里,每一个result的形式都是[ , ]
可用来调试查看是否通过“=”分离开数据 print(result)
'''
web_info.update(dict([result])) return web_info def get_userinfo(path):
user_info = []
config = codecs.open(path,'r','utf-8')
for line in config:
user_dict = {}
result = [ele.strip() for ele in line.split(' ')]
for r in result:
account = [ele.strip() for ele in r.split('=')]
user_dict.update(dict([account]))
user_info.append(user_dict)
return user_info if __name__ == '__main__':
webinfo = get_webinfo(r'C:\Users\胡廷祥\Desktop\webinfo.txt')
for key in info:
print(key,info[key])
userinfo = get_userinfo(r'C:\Users\胡廷祥\Desktop\userinfo.txt')
for l in userinfo:
print(l)
print(userinfo)
2.login.py
from selenium import webdriver
import time
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support.ui import WebDriverWait
from webinfo import get_webinfo
from webinfo import get_userinfo def openBrower(): #配置浏览器
webdriver_handle = webdriver.Firefox()
return webdriver_handle def openUrl(handle,url): #打开url
handle.get(url) def get_ele_times(driver,times,func):
return WebDriverWait(driver,times).until(func) #等待方法 def findElement(driver,arg):
'''
arg must be dict
1.login:登录入口
2.user_xpath:用户名
3.pwd_xpath:密码
4.login_xpath:登录按钮 return useEle,pwdEle,loginEle
'''
ele_login = get_ele_times(driver,10,lambda driver:driver.find_element_by_xpath(arg['login']))
ele_login.click()
useEle = driver.find_element_by_xpath(arg['user_xpath'])
pwdEle = driver.find_element_by_xpath(arg['pwd_xpath'])
loginEle = driver.find_element_by_xpath(arg['login_xpath'])
return useEle,pwdEle,loginEle def sendVals(eletuple,arg):
'''
ele tuple
account:uname,pwd
'''
listkey = ['uname','pwd']
i = 0
for key in listkey:
eletuple[i].send_keys('')
eletuple[i].clear()
eletuple[i].send_keys(arg[key])
i+=1
eletuple[2].click()
def checkResult(driver,text):
try:
driver.find_element_by_link_text(test)
print ("ACCOUNT AND PWD ERROR!")
except:
print ("ACCOUNT AND PWD RIGHT!") def login_test(ele_dict,user_list):
driver = openBrower()
openUrl(driver,ele_dict['url'])
driver.maximize_window() ele_tuple = findElement(driver,ele_dict) #接收字典的值
for arg in user_list:
sendVals(ele_tuple,arg)
checkResult(driver,ele_dict['errorid']) if __name__ == '__main__':
url = 'http://www.maiziedu.com/'
account = 'XXX'
pwd = 'maizi123456'
'''
ele_dict = {'url':url,'login':'/html/body/div[2]/div/div/div/div/a[2]','user_xpath':'//*[@id="id_account_l"]',\
'pwd_xpath':'//*[@id="id_password_l"]','login_xpath':'//*[@id="login_btn"]',\
'errorid':'该账号不正确'}
user_list = [{'uname':account,'pwd':pwd}]
'''
ele_dict = get_webinfo(r'C:\Users\XXX\Desktop\webinfo.txt')
user_list = get_userinfo(r'C:\Users\XXX\Desktop\userinfo.txt')
#file webinfo/userinfo ele_dict = get_webinfo(path) user_list = get_userinfo(path)
login_test(ele_dict,user_list)
Selenium(九)测试用例数据分离与从文件导入数据的更多相关文章
- 用SQLSERVER里的bcp命令或者bulkinsert命令也可以把dat文件导入数据表
用SQLSERVER里的bcp命令或者bulkinsert命令也可以把dat文件导入数据表 下面的内容的实验环境我是在SQLSERVER2005上面做的 之前在园子里看到两篇文章<C# 读取纯真 ...
- MySQL笔记(三)由txt文件导入数据
改编自学校实验,涉及一些字符集相关的问题. 索引 建库 导入数据 最终脚本 下载数据 点击这里 建库 create.sql DROP DATABASE IF EXISTS orderdb; CREAT ...
- JPA hibernate spring repository pgsql java 工程(二):sql文件导入数据,测试数据
使用jpa保存查询数据都很方便,除了在代码中加入数据外,可以使用sql进行导入.目前我只会一种方法,把数据集中在一个sql文件中. 而且数据在导入中常常具有先后关系,需要用串行的方式导入. 第一步:配 ...
- 从Excel(CSV)文件导入数据到Oracle
步骤: 1.准备数据:在excel中构造出需要的数据2.将excel中的数据另存为文本文件(有制表符分隔的)3.将新保存到文本文件中的数据导入到pl*sql中在pl*sql中选择tools--text ...
- PHP Excel文件导入数据到数据库
1.php部分(本例thinkphp5.1): 下载PHPExcel了扩展http://phpexcel.codeplex.com/ <?phpnamespace app\admin\contr ...
- Linux下通过txt文件导入数据到MySQL数据库
1.修改配置文件 在 /etc/my.conf 中添加 local_infile=1 2.重启MySQL >service mysqld restart 3.登录数据库 登录时添加参数 --lo ...
- [django]l利用xlrd实现xls文件导入数据
代码: #coding:utf-8 import os os.environ.setdefault("DJANGO_SETTINGS_MODULE", "www.sett ...
- mysql通过sql文件导入数据时出现乱码的解决办法
首先在新建数据库时一定要注意生成原数据库相同的编码形式,如果已经生成可以用phpmyadmin等工具再整理一次,防止数据库编码和表的编码不统一造成乱码. 方法一: 通过增加参数 –default-ch ...
- Jmeter—6 CSV Data Set Config 通过文件导入数据
线程组循环次数大于1的时候,请求里每次提交的数据都相同.有的系统限制了不能提交相同数据,我们通过 CSV Data Set Config 加载csv文件数据. 1 创建一个文本文件,输入参数值保存为. ...
随机推荐
- Windows服务操作帮助类
/// <summary> /// 打开系统服务 /// </summary> /// <param name="serviceName">系统 ...
- idea查看一个接口的子接口或实现类的快捷键
ctrl+h 先选中类或接口,再按ctrl+h
- Linux基础重点习题讲解
第一章 一个EXT4的文件分区,当时使用touch test.file命令创建一个新文件时报错,报错的信息是提示磁盘已满,但是采用df-h命令查看磁盘大小时,只使用了60%的磁盘空间,为什么会出现这 ...
- CCF201403 无线网络【限制型最短路】
问题描述 目前在一个很大的平面房间里有 n 个无线路由器,每个无线路由器都固定在某个点上.任何两个无线路由器只要距离不超过 r 就能互相建立网络连接. 除此以外,另有 m 个可以摆放无线路由器的位置. ...
- ORA-12514错误分析
ORA-12514 TNS 监听程序当前无法识别连接描述符中请求服务 的解决方法 ORA-12514 TNS 监听程序当前无法识别连接描述符中请求服务 有同事遇到这个问题,现总结一下,原因如下: ...
- jenkins sonarqube 代码检测部署
install pgsql and sonarqube docker run --name postgresqldb -e POSTGRES_USER=sonar -e POSTGRES_PASSWO ...
- 【计算几何】The Queen’s Super-circular Patio
The Queen’s Super-circular Patio 题目描述 The queen wishes to build a patio paved with of a circular cen ...
- MogileFS表说明
MogileFS大致的表说明如下 checksum:用来存放文件的校验和class:文件分类定义device:主机上的可用设备定义,包括设备可用空间,使用的权重等信息domain:域定义信息file: ...
- (八)Redis之持久化之AOF方式
一.概念 AOF方式:将以日志,记录每一个操作 优势:安全性相对RDB方式高很多: 劣势:效率相对RDB方式低很多: 二.案例 appendonly no默认关闭aof方式 我们修改成yes 就开启 ...
- (十)shiro之自定义Realm以及自定义Realm在web的应用demo
数据库设计 pom.xml <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http:/ ...