Hadoop和Spark的Shuffer过程对比解析
Hadoop Shuffer
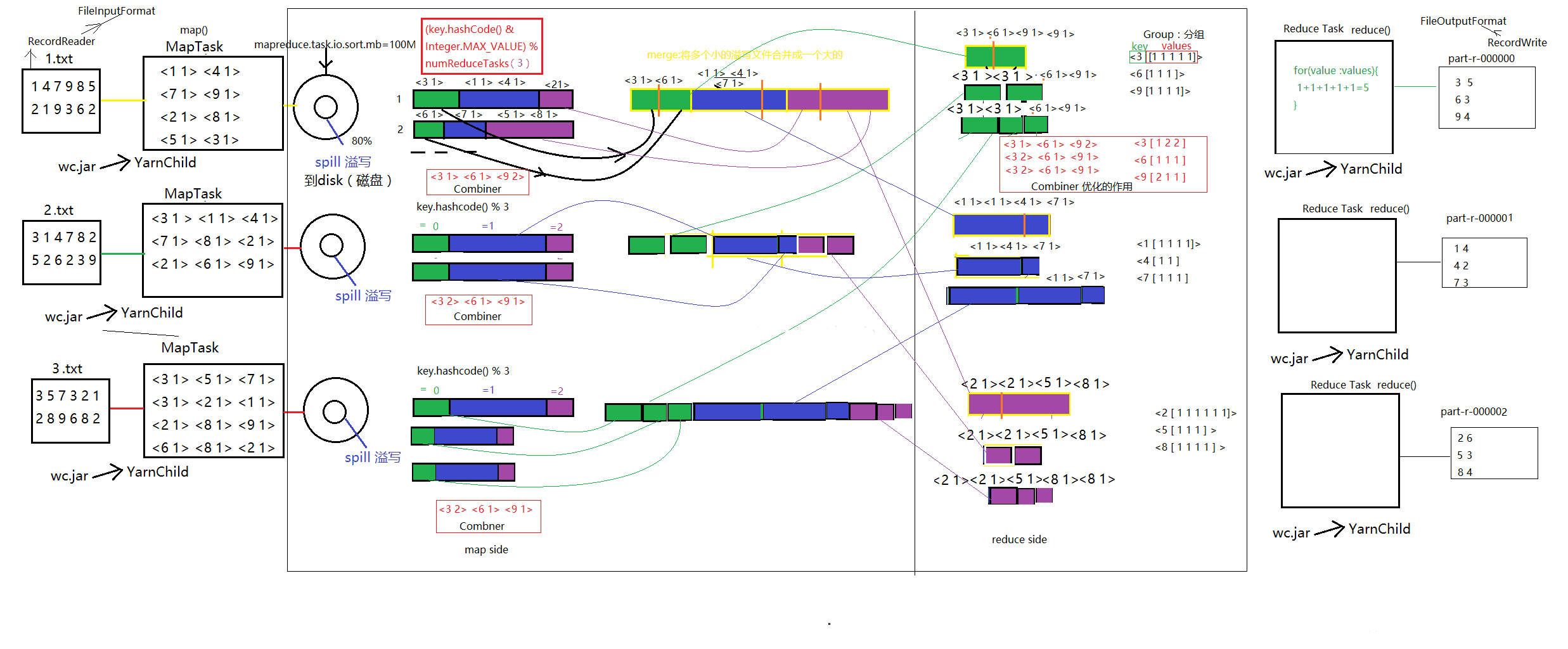
Hadoop 的shuffer主要分为两个阶段:Map、Reduce。
Map-Shuffer:
这个阶段发生在map阶段之后,数据写入内存之前,在数据写入内存的过程就已经开始shuffer,通过设置mapreduce.task.io.sort.mb的参数,可改变内存的大小,默认为100M。数据在写入内存大于80%时,会发生溢写spill)过程,将数据整体落地到磁盘,这个过程中默认调用快速排序算法进行排序,否则调用用户自定义的 combiner()方法,将数据按照排序的规则分布在分区。然后进入mapshuffer最后一个阶段merge,当磁盘中某一个分区的文件数量>=3个,自动触发文件合并合并程序,这个过程将一个分区的所有数据进行排序合并成一个文件目录(归并算法),以供reduce抓取。
(k,v,p) :一条数据,其中p是分区号。
Reduce-Shuffer:
通过拷贝线程copy merge中的数据到reduce端,调用归并算法,生成一个个Iterator,再通过分组程序,将同一个key的分组放在一起,聚合为一个Iterator。
Spark-Shuffer
Spark HashShuffle 是它以前的版本,现在1.6x 版本默应是 Sort-Based Shuffle。有分布式就一定会有 Shuffle,而且 HashShuffle 是 Spark以前的版本,亦即是 Sort-Based Shuffle 的前身,因为有 HashShuffle 的不足,才会有后续的 Sorted-Based Shuffle,以及现在的 Tungsten-Sort Shuffle。
Spark可以基于内存、也可以基于磁盘或者是第三方的储存空间进行计算:
第一、Spark框架的架构设计和设计模式上是倾向于在内存中计算数据的。
第二、这也表达了人们对数据处理的一种美好的愿望,就是希望计算数据的时候,数据就在内存中。
Shuffle 是分布式系统的天敌
Spark 运行分成两部分,第一部分是 Driver Program,里面的核心是 SparkContext,它驱动著一个程序的开始,负责指挥,另外一部分是 Worker 节点上的 Task,它是实际运行任务的,当程序运行时,不间断地由 Driver 与所在的进程进行交互,交互什么,有几点,第一、是让你去干什么,第二、是具体告诉 Task 数据在那里,例如说有三个 Stage,第二个 Task 要拿数据,它就会向 Driver 要数据,所以在整个工作的过程中,Executor 中的 Task 会不断地与 Driver 进行沟通,这是一个网络传输的过程。

关于这种架构有几点有用的注意事项:
- 每个应用程序都有自己的执行程序进程,这些进程在整个应用程序的持续时间内保持不变并在多个线程中运行任务。这样可以在调度方(每个驱动程序调度自己的任务)和执行方(在不同JVM中运行的不同应用程序中的任务)之间隔离应用程序。但是,这也意味着无法在不将Spark应用程序(SparkContext实例)写入外部存储系统的情况下共享数据。
- Spark与底层集群管理器无关。只要它可以获取执行程序进程,并且这些进程相互通信,即使在也支持其他应用程序的集群管理器(例如Mesos / YARN)上运行它也相对容易。
- 驱动程序必须在其生命周期内监听并接受来自其执行程序的传入连接(例如,请参阅网络配置部分中的spark.driver.port)。因此,驱动程序必须是来自工作节点的网络可寻址的。
- 因为驱动程序在集群上调度任务,所以它应该靠近工作节点运行,最好是在同一局域网上运行。如果您想远程向群集发送请求,最好向驱动程序打开RPC并让它从附近提交操作,而不是远离工作节点运行驱动程序。
在这个过程中一方面是 Driver 跟 Executor 进行网络传输,另一方面是Task要从 Driver 抓取其他上游的 Task 的数据结果,所以有这个过程中就不断的产生网络结果。其中,下一个 Stage 向上一个 Stage 要数据这个过程,我们就称之为 Shuffle。
每一个节点计算一部份数据,如果不对各个节点上独立的部份进行汇聚的话,我们是计算不到最终的结果。这就是因为我们需要利用分布式来发挥它本身并行计算的能力,而后续又需要计算各节点上最终的结果,所以需要把数据汇聚集中,这就会导致 Shuffle,这也是说为什么 Shuffle 是分布式不可避免的命运。
原始的 HashShuffle 机制
基于 Mapper 和 Reducer 理解的基础上,当 Reducer 去抓取数据时,它的 Key 到底是怎么分配的,核心思考点是:作为上游数据是怎么去分配给下游数据的。在这张图中你可以看到有4个 Task 在2个 Executors 上面,它们是并行运行的,Hash 本身有一套 Hash算法,可以把数据的 Key 进行重新分类,每个 Task 对数据进行分类然后把它们不同类别的数据先写到本地磁盘,然后再经过网络传输 Shuffle,把数据传到下一个 Stage 进行汇聚。
HashShuffle 缺点:
- Shuffle前在磁盘上会产生海量的小文件,此时会产生大量耗时低效的 IO 操作 (因為产生过多的小文件)
- 内存不够用,由于内存中需要保存海量文件操作句柄和临时信息,如果数据处理的规模比较庞大的话,内存不可承受,会出现 OOM 等问题。
优化后的 HashShuffle 机制
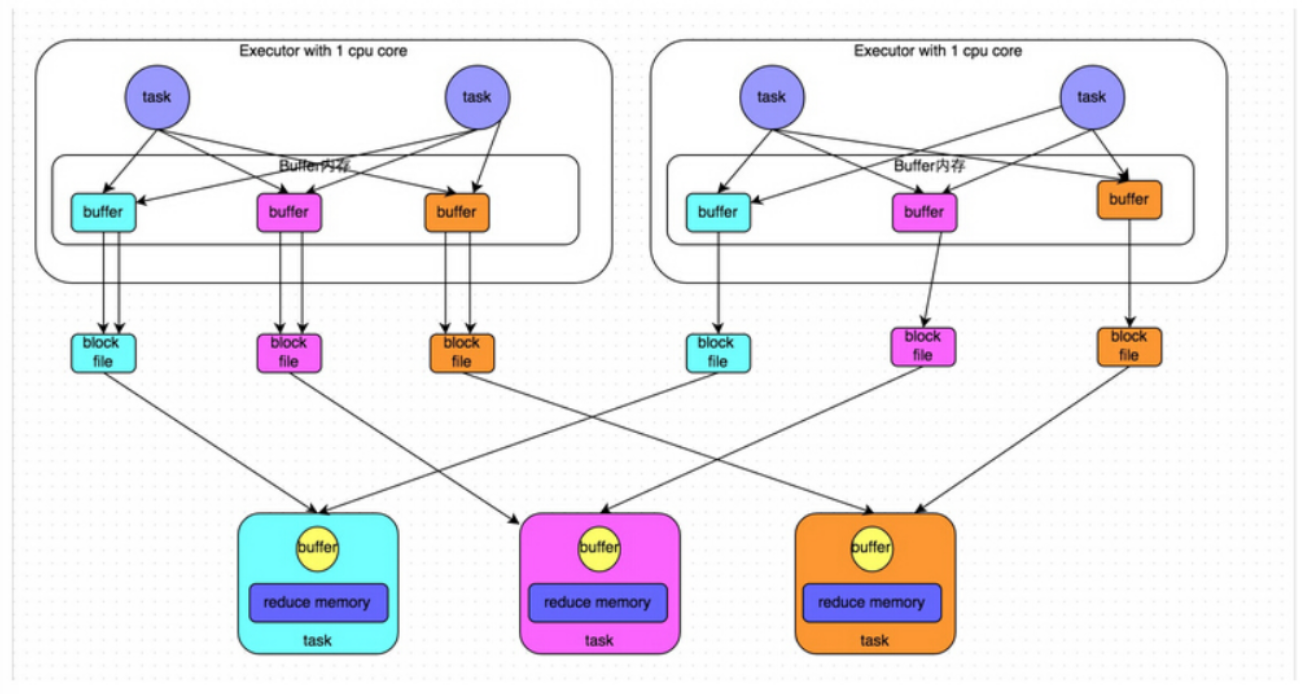
有4个Tasks,数据类别还是分成3种类型,因为Hash算法会根据你的 Key 进行分类,在同一个进程中,无论是有多少过Task,都会把同样的Key放在同一个Buffer里,然后把Buffer中的数据写入以Core数量为单位的本地文件中,(一个Core只有一种类型的Key的数据),每1个Task所在的进程中,分别写入共同进程中的3份本地文件,这里有4个Mapper Tasks,总共输出是 2个Cores x 3个分类文件 = 6个本地小文件。Consoldiated Hash-Shuffle的优化有一个很大的好处就是假设现在有200个Mapper Tasks在同一个进程中,也只会产生3个本地小文件; 如果用原始的 Hash-Based Shuffle 的话,200个Mapper Tasks 会各自产生3个本地小文件,在一个进程已经产生了600个本地小文件。
这个优化后的 HashShuffle 叫 ConsolidatedShuffle,在实际生产环境下可以调以下参数:
spark.shuffle.consolidateFiles=true
Consolidated HashShuffle 缺点:
- 如果 Reducer 端的并行任务或者是数据分片过多的话则 Core * Reducer Task 依旧过大,也会产生很多小文件。
Shuffle影响Spark性能及调优点
Shuffle 不可以避免是因为在分布式系统中的基本点就是把一个很大的的任务/作业分成一百份或者是一千份,这一百份和一千份文件在不同的机器上独自完成各自不同的部份,我们是针对整个作业要结果,所以在后面会进行汇聚,这个汇聚的过程的前一阶段到后一阶段以至网络传输的过程就叫 Shuffle。
在 Spark 中为了完成 Shuffle 的过程会把真正的一个作业划分为不同的 Stage,这个Stage 的划分是跟据依赖关系去决定的,Shuffle 是整个 Spark 中最消耗性能的一个地方。试试想想如果没有 Shuffle 的话,Spark可以完成一个纯内存式的操作。
reduceByKey,它会把每个 Key 对应的 Value 聚合成一个 value 然后生成新的 RDD。
因为在不同节点上我们要进行数据传输,数据在通过网络发送之前,要先存储在内存中,内存达到一定的程度,它会写到本地磁盘,(在以前 Spark 的版本它没有Buffer 的限制,会不断地写入 Buffer 然后等内存满了就写入本地,现在的版本对 Buffer 多少设定了限制,以防止出现 OOM,减少了 IO)。Mapper 端会写入内存 Buffer,这个便关乎到 GC 的问题,然后 Mapper端的 Block 要写入本地,大量的磁盘与IO的操作和磁盘与网络IO的操作,这就构成了分布式的性能杀手。
如果要对最终计算结果进行排序的话,一般会都会进行 sortByKey,如果以最终结果来思考的话,可以认为是产生了一个很大很大的 partition,可以用 reduceByKey 的时候指定它的并行度,例如把 reduceByKey 的并行度变成为1,新 RDD 的数据切片就变成1,排序一般都会在很多节点上,如果把很多节点变成一个节点然后进行排序,有时候会取得更好的效果,因为数据就在一个节点上,技术层面来讲就只需要在一个进程里进行排序。
可以在调用 reduceByKey()接著调用 mapPartition( );
也可以用 repartitionAndSortWithPartitions( );
还有一个地方就是数据倾斜,Shuffle 时会导政数据分布不均衡。数据倾斜的问题会引申很多其他问题,比如,网络带宽、各重硬件故障、内存过度消耗、文件掉失。因为 Shuffle 的过程中会产生大量的磁盘 IO、网络 IO、以及压缩、解压缩、序列化和反序列化等等。
Shuffle可能面临的问题,运行 Task 的时候才会产生 Shuffle (Shuffle 已经融化在 Spark 的算子中)
- 几千台或者是上万台的机器进行汇聚计算,数据量会非常大,网络传输会很大
- 数据如何分类其实就是 partition,即如何 Partition、Hash 、Sort 、计算
- 负载均衡 (数据倾斜)
- 网络传输效率,需要压缩或解压缩之间做出权衡,序列化 和 反序列化也是要考虑的问题
具体的 Task 进行计算的时候尽一切最大可能使得数据具备 Process Locality 的特性,退而求其次是增加数据分片,减少每个 Task 处理的数据量**,基于Shuffle 和数据倾斜所导致的一系列问题,可以延伸出很多不同的调优点,比如说:
- Mapper端的 Buffer 应该设置为多大呢?
- Reducer端的 Buffer 应该设置为多大呢?如果 Reducer 太少的话,这会限制了抓取多少数据
- 在数据传输的过程中是否有压缩以及该用什么方式去压缩,默应是用 snappy 的压缩方式。
- 网络传输失败重试的次数,每次重试之间间隔多少时间。
总结
因为想利用分布式的计算能力,所以要把数据分散到不同节点上运行,上游阶段数据是并行运行的,下游阶段要进行汇聚,所以出现Shuffle,如果下游分成三类,上游也需要每个Task把数据分成三类,虽然有可能有一类是没有数据,这无所谓,只要在实际运行时按照这套规则就可以了,这就是最原始的 Shuffle 过程。
Hash-based Shuffle 默认Mapper 阶段会为Reducer 阶段的每一个Task单独创建一个文件来保存该Task中要使用的数据,但是在一些情况下(例如说数据量非常庞大的情况) 会造成大量文件的随机磁盘IO操作且会性成大量的Memory消耗(极易造成OOM)。
- 原始的 Hash-Shuffle 所产生的小文件: Mapper 端 Task 的个数 x Reduce 端 Task 的数量
- Consolidated Hash-Shuffle 所产生的小文件: CPU Cores 的个数 x Reduce 端 Task 的数量
Spark Shuffle 说到底都是离不开读文件、写文件、为了高效我们需要缓存,由于有很多不同的进程,就需要一个管理者。HashShuffle 适合的埸景是小数据的埸景,对小规模数据的处理效率会比排序后的 Shuffle 高。
区别在于HadoopShuffer是sort-based,spill内存大小是100M,Saprk是hash-based(hash-based故名思义也就是在Shuffle的过程中写数据时不做排序操作,只是将数据根据Hash的结果,将各个Reduce分区的数据写到各自的磁盘文件中),内存大小是32K,Hadoop的Shuffle过程是明显的几个阶段:map(),spill,merge,shuffle,sort,reduce()等,是按照流程顺次执行的,属于push类型;但是,Spark不一样,因为Spark的Shuffle过程是算子驱动的,具有懒执行的特点,属于pull类型。
参考
Spark性能调优- 第二章:彻底解密Spark的HashShuffle
Hadoop shuffer 和 Spark shuffer区别
Hadoop和Spark的Shuffer过程对比解析的更多相关文章
- 剖析Hadoop和Spark的Shuffle过程差异
一.前言 对于基于MapReduce编程范式的分布式计算来说,本质上而言,就是在计算数据的交.并.差.聚合.排序等过程.而分布式计算分而治之的思想,让每个节点只计算部分数据,也就是只处理一个分片,那么 ...
- 剖析Hadoop和Spark的Shuffle过程差异(一)
一.前言 对于基于MapReduce编程范式的分布式计算来说,本质上而言,就是在计算数据的交.并.差.聚合.排序等过程.而分布式计算分而治之的思想,让每个节点只计算部分数据,也就是只处理一个分片,那么 ...
- hadoop的mapReduce和Spark的shuffle过程的详解与对比及优化
https://blog.csdn.net/u010697988/article/details/70173104 大数据的分布式计算框架目前使用的最多的就是hadoop的mapReduce和Spar ...
- Spark 的 Shuffle过程介绍`
Spark的Shuffle过程介绍 Shuffle Writer Spark丰富了任务类型,有些任务之间数据流转不需要通过Shuffle,但是有些任务之间还是需要通过Shuffle来传递数据,比如wi ...
- Spark的Shuffle过程介绍
Spark的Shuffle过程介绍 Shuffle Writer Spark丰富了任务类型,有些任务之间数据流转不需要通过Shuffle,但是有些任务之间还是需要通过Shuffle来传递数据,比如wi ...
- hadoop之Spark强有力竞争者Flink,Spark与Flink:对比与分析
hadoop之Spark强有力竞争者Flink,Spark与Flink:对比与分析 Spark是一种快速.通用的计算集群系统,Spark提出的最主要抽象概念是弹性分布式数据集(RDD),它是一个元素集 ...
- PageRank在Hadoop和spark下的实现以及对比
关于PageRank的地位,不必多说. 主要思想:对于每个网页,用户都有可能点击网页上的某个链接,例如 A:B,C,D B:A,D C:AD:B,C 由这个我们可以得到网页的转移矩阵 A ...
- Hadoop vs Spark性能对比
http://www.cnblogs.com/jerrylead/archive/2012/08/13/2636149.html Hadoop vs Spark性能对比 基于Spark-0.4和Had ...
- Ubuntu安装Hadoop与Spark
更新apt 用 hadoop 用户登录后,我们先更新一下 apt,后续我们使用 apt 安装软件,如果没更新可能有一些软件安装不了.按 ctrl+alt+t 打开终端窗口,执行如下命令: sudo a ...
随机推荐
- C/C++语言之由数字26引起的文件的数据保存与读取调试。
首先在VS2010中遇到的问题是,建立了一个结构体 struct position{ int x; int y; }: 然后用此结构体声明一个数组rout[8]; for(int i=0;i<8 ...
- 沙雕题目 来自luogu
P5316 恋恋的数学题 题目描述 现在恋恋正在处理的题目十分简单:现在有k (2≤k≤4)k \space (2\leq k\leq 4)k (2≤k≤4)个数,恋恋不知道它们分别是几,只知道它们两 ...
- static关键字的用法小结
static:是一个修饰符,用于修饰成员(成员变量,成员函数). 当成员被静态修饰后,就多了一个调用方式,除了可以被对象调用外,还可以直接被类名调用,写法:类名.静态成员 static特点: 1.随着 ...
- Windows Server 2008 R2 服务器内存使用率过高几乎耗光
系统环境: Windows Server 2008 R2 Enterprise 搭建有 web服务器(iis) 和 文件服务 问题描述: Windows Server 2008 R2系统内存耗光 ...
- 【C/C++】Linux的gcc和g++的区别
Windows中我们常用vs来编译编写好的C和C++代码:vs把编辑器,编译器和调试器等工具都集成在这一款工具中,在Linux下我们能用什么工具来编译所编写好的代码呢,其实Linux下这样的工具有很多 ...
- ubuntu18.04 systemctl
systemd 是 Linux 下的一款系统和服务管理器,兼容 SysV 和 LSB 的启动脚本.systemd 的特性有:支持并行化任务:同一时候採用 socket 式与 D-Bus 总线式激活服务 ...
- Flume-自定义 Sink
Sink 不断地轮询 Channel 中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统.或者被发送到另一个 Flume Agent. Sink 是完全事务性的. 在从 Channel 批 ...
- ThinkPHP6.0学习之安装及问题解决
ThinkPHP6.0学习之安装及问题解决 ThinkPHP6.0开发版已经上线了,我已经等了他很久了,现在写一个系列来记录Thinkphp6.0的使用,我们现在从安装开始学习吧. 首先我们要确定Th ...
- mySQL 插入,更新和删除数据
插入数据: 语法: INSERT INTO table_name ( field1, field2,...fieldN ) VALUES ( value1, value2,...valueN ); 如 ...
- Kotlin 中类函数
在kotlin中函数可以在类外部定义也可以在类内部定义,前者即为全局函数,后者,是类成员函数,语法一样 package loaderman.demo class Person { fun demo(n ...