DB 分库分表的基本思想和切分策略
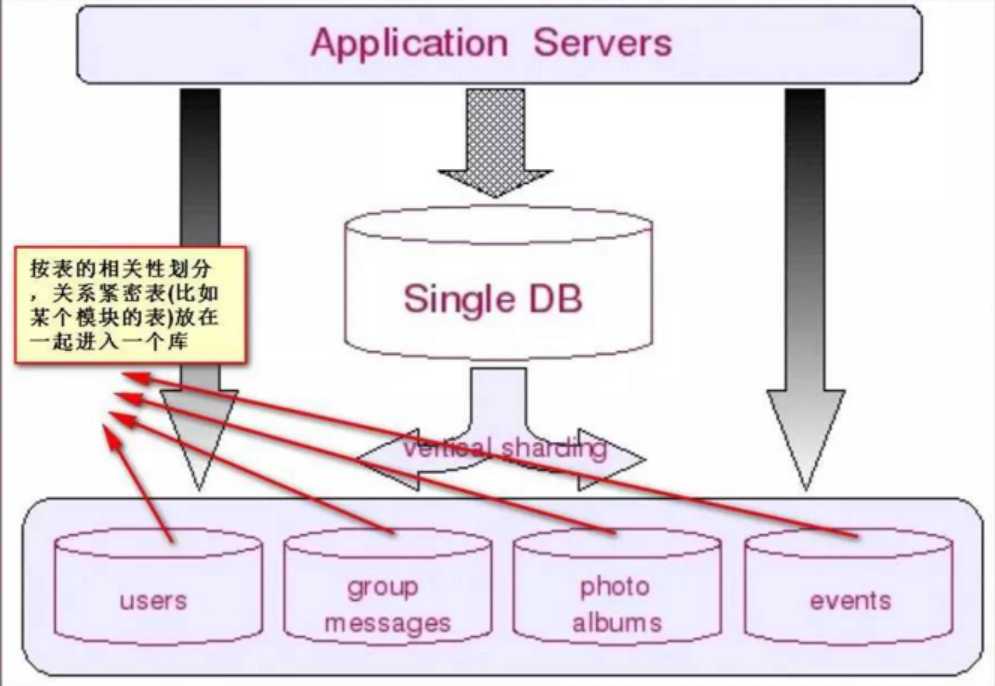

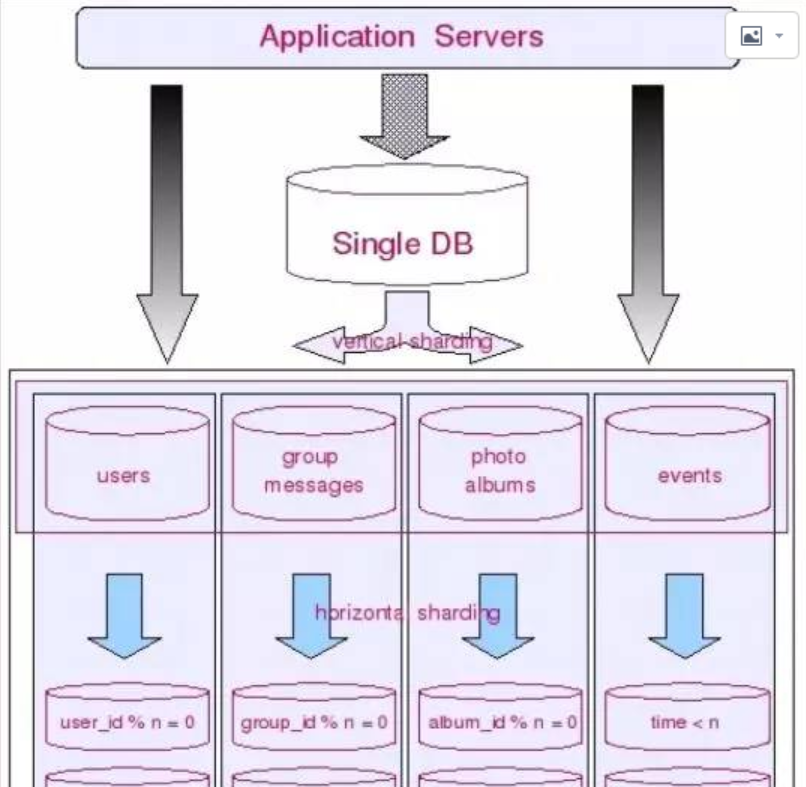

- 若划归到一起的表格关系紧密,且数据量并不大,增速也非常缓慢,则适宜放在一个shard里,不需要再进行水平切分;
- 若划归到一起的表格数据量巨大且增速迅猛,则势必要在垂直切分的基础上再进行水平切分,水平切分就意味着原单一shard会被细分成多个更小的shard,每一个shard存在一个主表(即会以该表ID进行散列的表)和多个相之相关的关联表。
DB 分库分表的基本思想和切分策略的更多相关文章
- DB 分库分表(5):一种支持自由规划无须数据迁移和修改路由代码的 Sharding 扩容方案
作为一种数据存储层面上的水平伸缩解决方案,数据库Sharding技术由来已久,很多海量数据系统在其发展演进的历程中都曾经历过分库分表的Sharding改造阶段.简单地说,Sharding就是将原来单一 ...
- DB 分库分表(1):拆分实施策略和示例演示
DB 分库分表(1):拆分实施策略和示例演示 第一部分:实施策略 1.准备阶段 对数据库进行分库分表(Sharding化)前,需要开发人员充分了解系统业务逻辑和数据库schema.一个好的建议是绘制一 ...
- DB 分库分表(2):全局主键生成策略
DB 分库分表(2):全局主键生成策略 本文将主要介绍一些常见的全局主键生成策略,然后重点介绍flickr使用的一种非常优秀的全局主键生成方案.关于分库分表(sharding)的拆分策略和实施细则,请 ...
- 转数据库分库分表(sharding)系列(一) 拆分实施策略和示例演示
本文原文连接: http://blog.csdn.net/bluishglc/article/details/7696085 ,转载请注明出处!本文着重介绍sharding切分策略,如果你对数据库sh ...
- 数据库分库分表(sharding)系列(一)拆分实施策略和示例演示
本文原文连接: http://blog.csdn.net/bluishglc/article/details/7696085 ,转载请注明出处!本文着重介绍sharding切分策略,如果你对数据库sh ...
- 据库分库分表(sharding)系列(一) 拆分实施策略和示例演示
本文原文连接: http://blog.csdn.net/bluishglc/article/details/7696085 ,转载请注明出处!本文着重介绍sharding切分策略,如果你对数据库sh ...
- DB 分库分表(3):关于使用框架还是自主开发以及 sharding 实现层面的考量
当团队对系统业务和数据库进行了细致的梳理,确定了切分方案后,接下来的问题就是如何去实现切分方案了,目前在sharding方面有不少的开源框架和产品可供参考,同时很多团队也会选择自主开发实现,而不管是选 ...
- DB 分库分表(4):多数据源的事务处理
系统经sharding改造之后,原来单一的数据库会演变成多个数据库,如何确保多数据源同时操作的原子性和一致性是不得不考虑的一个问题.总体上看,目前对于一个分布式系统的事务处理有三种方式:分布式事务.基 ...
- Mysql系列四:数据库分库分表基础理论
一.数据处理分类 1. 海量数据处理,按照使用场景主要分为两种类型: 联机事务处理(OLTP) 面向交易的处理系统,其基本特征是原始数据可以立即传送到计算机中心进行处理,并在很短的时间内给出处理结果. ...
随机推荐
- Excel学习笔记:行列转换
目录 offset函数 行列转换的三种方式 1.右键转置 2.转置公式TRANSPOSE 3.引用函数OFFSET+ROWS/COLUMN(支持随时更新数据) 一行(列)转多行多列 offset函数 ...
- vue中使用qrcode,遇到两次渲染的问题
1.安装 qrcodejs2: npm install qrcodejs2 --save 2.页面中引入: import QRCode from "qrcodejs2"; co ...
- JavaScript使用纯函数避免bug
纯函数 一.纯函数 定义:纯函数是指不依赖并且不修改其作用域之外的函数.通过以下几个示例来认识纯函数: var a = 10; //纯函数 function foo(num){ return num ...
- vue项目打包文件配置(vue-clli3)
练手项目完结打包的时候遇到一些问题,特此记录 先贴我的vue.config.js文件的代码(vue-cli3构建的项目默认是没有此文件的,需手动添加)更多详细配置参考官方配置文档,我的项目不大不小,这 ...
- springBoot2.x 支持跨域请求配置
提供三种配置方式: 1.配置过滤器,实现 WebMvcConfigurer接口(springboot2.x的方式) @Configuration public class GlobalCorsConf ...
- EBS常用表_Dictionary
EBS常用表:转载于 https://blog.csdn.net/xiariqingcao/article/details/8775827 . OU.库存组织 SELECT hou.organizat ...
- Android-分享多图到微信好友
/** * 微信分享(多图片) */ private static void shareWeChatByImgList(String kDescription, List<File> im ...
- nginx 配置简单的静态页面
nginx 文件服务配置,MIME和 default_type https://blog.csdn.net/qq_26711103/article/details/81116900 nginx 静态页 ...
- lumen时区
今天用 Lumen 框架写代码时, 也是初次体验 Lumen, 遇到了一个问题, 从数据库里查出的时间比数据库里保存的 TIMESTAMP 时间慢了8个小时, 很明显这是一个时区设置的问题, 本以为可 ...
- python3 之configparser 模块
configparser 简介 configparser 是 Pyhton 标准库中用来解析配置文件的模块,并且内置方法和字典非常接近[db]db_count = 31 = passwd2 = dat ...