如何入门Pytorch之三:如何优化神经网络
在上一节中,我们介绍了如何使用Pytorch来搭建一个经典的分类神经网络。一般情况下,搭建完模型后训练不会一次就能达到比较好的效果,这样,就需要不断的调整和优化模型的各个部分。从而引出了本文的主旨:如何优化模型。
在本节中,我们将介绍从数据集到模型各个部分的调整,从而可以有一个完整的解决思路。
1、数据集部分
1.1 数据集划分
一般情况下,我们会把数据集分成三个部分:训练集,验证集和测试集。依据数据集的大小,如果数据集比较大,数万或数十万个,可以将数据集采用7:2:1或8:1:1的比例来划分。而如果数据集比较小,只有几百条,就不能简单的使用这个方法了。这时,需要使用K折验证法(具体方法可自行百度)。
当然,还有一些需要考虑的问题:数据表征,时间敏感性和数据冗余。在数据表征中,随机打乱(shuffle)是一个不错的选择;时间敏感性主要是针对回归问题象预测股票,不同的月份对回归结果有一个不同的贡献;数据冗余指的是,在数据集中,存在着一些相同的数据会对训练和测试结果产生影响,所以,需要事先过滤掉。
1.2数据预处理
数据向量化:数据源形式各异,需要提前把它转换成框架可以识别的形式,Pytorch统一使用向量(Vector)来表示数据。
正则化:数据的范围大小不一,如果直接使用,训练的收敛会很慢,甚至会出现异常。所以,需要统一数据的范围大小,也就是去除纲量,使用【0,1】区间来统一度量。
缺失数据的处理:如果没有对缺失数据进行处理,训练过程中会直接导致数据的权重分配异常,进而直接影响训练效果。
特征工程:对数据集的特征进行有效提取,是保证模型正常训练的前提。
1.3过拟合与欠拟合
过拟合:训练效果好而验证效果不好。
欠拟合:训练效果不好。
欠拟合的处理相对容易些,针对欠拟合,我们一般采用加大训练周期,降低训练损失,提高训练精度。
过拟合策略:
1、获取更多数据
2、减小网络规模
原始模型:
class Architecture1(nn.Module):
def __init__(self, input_size, hidden_size, num_classes):
super(Architecture1, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, num_classes)
self.relu = nn.ReLU()
self.fc3 = nn.Linear(hidden_size, num_classes)
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
out = self.relu(out)
out = self.fc3(out)
return out
减小规模后的模型:
class Architecture2(nn.Module):
def __init__(self, input_size, hidden_size, num_classes):
super(Architecture2, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, num_classes)
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
return out
3、使用权重正则化
正则化分为1阶正则化和2阶正则化
1阶正则化是将权重协相关系数的相差绝对值加入权重。
2阶正则化是将权重协相关系数的相差平方和加入权重。示例如下:
model = Architecture1(10,20,2)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4, weight_decay=1e-5)
4、使用DROPOUT
在隐藏层中去除某些节点,以达到防止过拟合的问题。
dropout的比率为0.2:
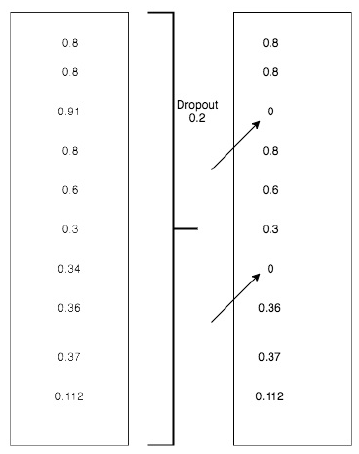
dropout的比率为0.5

nn.dropout(x, training=True)
1.4问题定义与数据集获取
首先需要明确两个事情:问题的类别与数据的输入,确定是分类问题还是回归问题。
不同类别的问题有着不同的处理方法,对数据集的获取也是必须面对的一大难题。
1.5模型评估
对于分类问题,一般采用精度,ROC,AUC等方法来进行评估。
而对于排名问题,一般采用mAp。
2、模型部分
2.1 搭建完基础模型后,为了使该模型能够正常工作,我们需要做以下三部分工作:
1、选择网络输出的最后一层
不同的任务,输出最后一层也不尽相同。一般的回归问题只要输出一个标量就可以;向量回归问题则需要输出相同层的向量;对于BBOX问题,则需要输出四个值;对于
二分类,我们需要使用Sigmoid,对于多分类则使用softmax。
2、选择损失函数
对于分类问题,一般采用交叉熵损失;而对于回归问题,则采用均方差。
3、优化器
如何选择一个优化器及配置相关参数是一件非常有艺术性的事。有时需要通过实验来得到。很多时候:Adam和RMSProp是个不错的选择。
Problem type Activation function Loss function
Binary classification Sigmoid activation nn.CrossEntropyLoss()
Multi-class classification Softmax activation nn.CrossEntropyLoss()
Multi-label classification Sigmoid activation nn.CrossEntropyLoss()
Regression None MSE
Vector regression None MSE
2.2 提高模型规模
对于一个已搭建好的模型,如何提高模型的推理能力。可以从这三方面来提高:
1、增加更多的层
2、加入更多的权重系数
3、提高训练周期
2.3 加入泛化策略
1、加入dropout
2、使用不同的架构,不同的参数,不同的网络层数,权重。
3、使用L1或L2正则化
4、尝试不同的学习率
5、增加更多的数据或特征
2.4学习率的设置
学习率对于模型来说,是一个非常重要的超参数。它的设置很多时候直接决定着模型训练效果的好坏。所以,如何设置该参数就变得非常重要。有大量的研究就是针对于该参数进行的。
在Pytorch中,有一系列的方法:
1、stepLR:
scheduler = StepLR(optimizer, step_size=30, gamma=0.1) #step_size:多少个周期后学习率发生改变 gamma:学习率如何你改变
for epoch in range(100):
scheduler.step()
train(...)
validate(...)
2、MultiStepLR
scheduler = MultiStepLR(optimizer, milestones=[30,80], gamma=0.1)
#milestones:多少个周期后学习率发生改变 gamma:学习率如何你改变
for epoch in range(100): scheduler.step() train(...) validate(...)
3、ExponentialLR
4、ReduceLROnPlateau
optimizer = torch.optim.SGD(model.parameters(), lr=0.1,
momentum=0.9)
scheduler = ReduceLROnPlateau(optimizer, 'min')
for epoch in range(10):
train(...)
val_loss = validate(...)
# Note that step should be called after validate()
scheduler.step(val_loss)
上一篇:
下一篇:
待更新。。。
如何入门Pytorch之三:如何优化神经网络的更多相关文章
- 如何入门Pytorch之四:搭建神经网络训练MNIST
上一节我们学习了Pytorch优化网络的基本方法,本节我们将以MNIST数据集为例,通过搭建一个完整的神经网络,来加深对Pytorch的理解. 一.数据集 MNIST是一个非常经典的数据集,下载链接: ...
- 如何入门Pytorch之二:如何搭建实用神经网络
上一节中,我们介绍了Pytorch的基本知识,如数据格式,梯度,损失等内容. 在本节中,我们将介绍如何使用Pytorch来搭建一个经典的分类神经网络. 搭建一个神经网络并训练,大致有这么四个部分: 1 ...
- 60 分钟极速入门 PyTorch
2017 年初,Facebook 在机器学习和科学计算工具 Torch 的基础上,针对 Python 语言发布了一个全新的机器学习工具包 PyTorch. 因其在灵活性.易用性.速度方面的优秀表现,经 ...
- 如何入门Pytorch之一:Pytorch基本知识介绍
前言 PyTorch和Tensorflow是目前最为火热的两大深度学习框架,Tensorflow主要用户群在于工业界,而PyTorch主要用户分布在学术界.目前视觉三大顶会的论文大多都是基于PyTor ...
- 新手如何入门pytorch?
我最近的文章中,专门为想学Pytorch的新手推荐了一些学习资源,包括教程.视频.项目.论文和书籍.希望能对你有帮助:一.PyTorch学习教程.手册 (1)PyTorch英文版官方手册:https: ...
- 【OpenCV入门教程之三】 图像的载入,显示和输出 一站式完全解析(转)
本系列文章由@浅墨_毛星云 出品,转载请注明出处. 文章链接:http://blog.csdn.net/poem_qianmo/article/details/20537737 作者:毛星云(浅墨) ...
- Asp.Net MVC4.0 官方教程 入门指南之三--添加一个视图
Asp.Net MVC4.0 官方教程 入门指南之三--添加一个视图 在本节中,您需要修改HelloWorldController类,从而使用视图模板文件,干净优雅的封装生成返回到客户端浏览器HTML ...
- PyTorch-Adam优化算法原理,公式,应用
概念:Adam 是一种可以替代传统随机梯度下降过程的一阶优化算法,它能基于训练数据迭代地更新神经网络权重.Adam 最开始是由 OpenAI 的 Diederik Kingma 和多伦多大学的 Jim ...
- 深度学习之入门Pytorch(1)------基础
目录: Pytorch数据类型:Tensor与Storage 创建张量 tensor与numpy数组之间的转换 索引.连接.切片等 Tensor操作[add,数学运算,转置等] GPU加速 自动求导: ...
随机推荐
- MLE & MAP
MLE & MAP : data / model parameter MLE: (1) keep the data fixed(i.e., it has been observed) and ...
- unicode 字符范围
根据最新的Unicode 5.0版整理如下: 1)标准CJK文字 http://www.unicode.org/Public/UNIDATA/Unihan.html Code point range ...
- Jmeter 逻辑控制器 之 Switch Controller
一.认识 Switch Controller Switch Controller:开关控制器,通过其下样例顺序数值或名称 控制执行某一个样例 二.通过样例顺序数值控制执行样例 三.通过样例名称控制 ...
- Java程序员壁纸-Java开发
- flask上下文管理相关 - threading.local 以及原理剖析
threading.local 面向对象相关: setattr/getattr class Foo(object): pass obj = Foo() obj.x1 = 123 # object.__ ...
- 大周末的不休息,继续学习pandas吧,pandas你该这么学,No.7
其实,写文章真的挺难的 每天抽点时间,写写文采飘逸的文章 坚持个几年,成为称霸一方的大佬 坚持就会成功吧~ 最近碰到瓶颈了, 一直找不到好的运营公众号的方式(好想有人指导唉~,对了,橡皮擦有个100多 ...
- 2019icpc-徐州网络赛
B. hxc写的 AC code: #pragma GCC optimize(2) #include <cstdio> #include <queue> #include &l ...
- 【转帖】Linux上搭建Samba,实现windows与Linux文件数据同步
Linux上搭建Samba,实现windows与Linux文件数据同步 2018年06月09日 :: m_nanle_xiaobudiu 阅读数 15812更多 分类专栏: Linux Samba 版 ...
- 【51nod】2589 快速讨伐
51nod 2589 快速讨伐 又是一道倒着推改变世界的题... 从后往前考虑,设\(dp[i][j]\)表示还有\(i\)个1和\(j\)个\(2\)没有填,那么填一个1的话直接转移过来 \(dp[ ...
- Eureka【故障演练分析】
1.应用服务启动前不可用 假设eureka server服务在client应用服务启动之前挂掉,或者没有启动,这时应用服务依然可以正常启动,但是会有报错信息: 2019-10-13 14:40:41. ...