# 深圳杯D题爬取电视收视率排行榜
深圳杯D题爬取电视收视率排行榜
站点分析
http://www.tvtv.hk/archives/category/tv
每天的排行版通过静态页面发布,先获取每天的排行榜链接,再进一步从链接里面获取数据
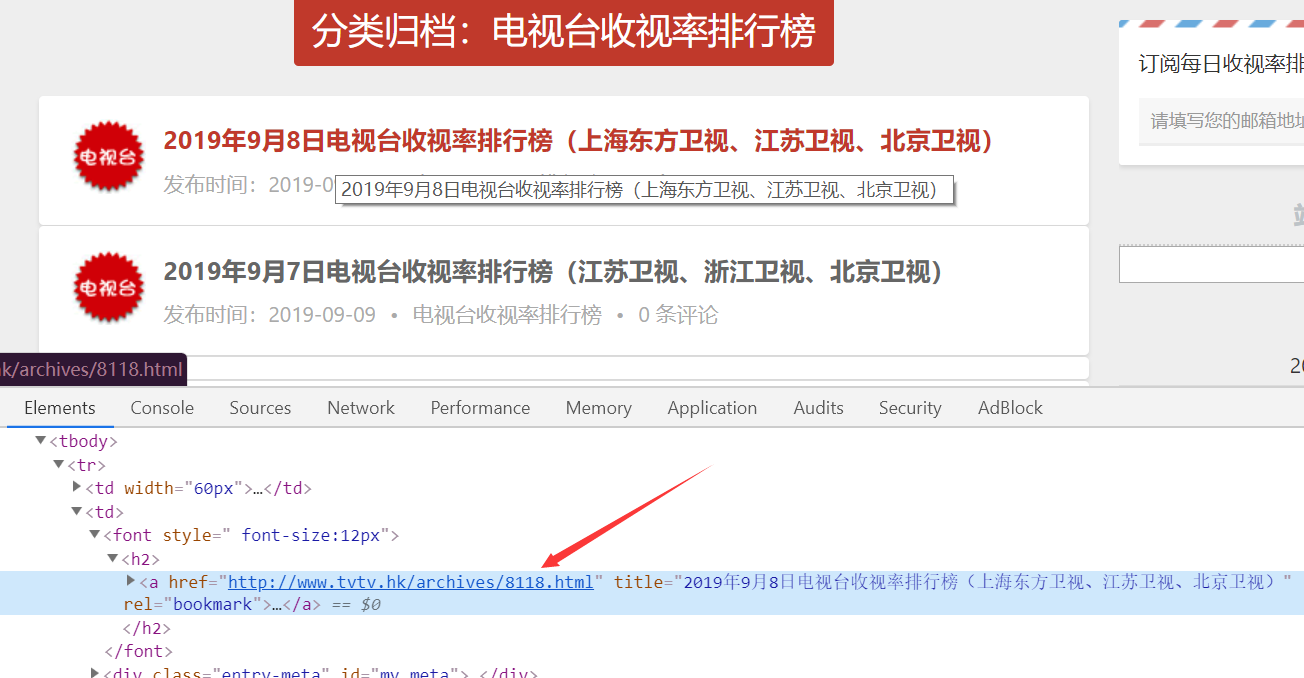
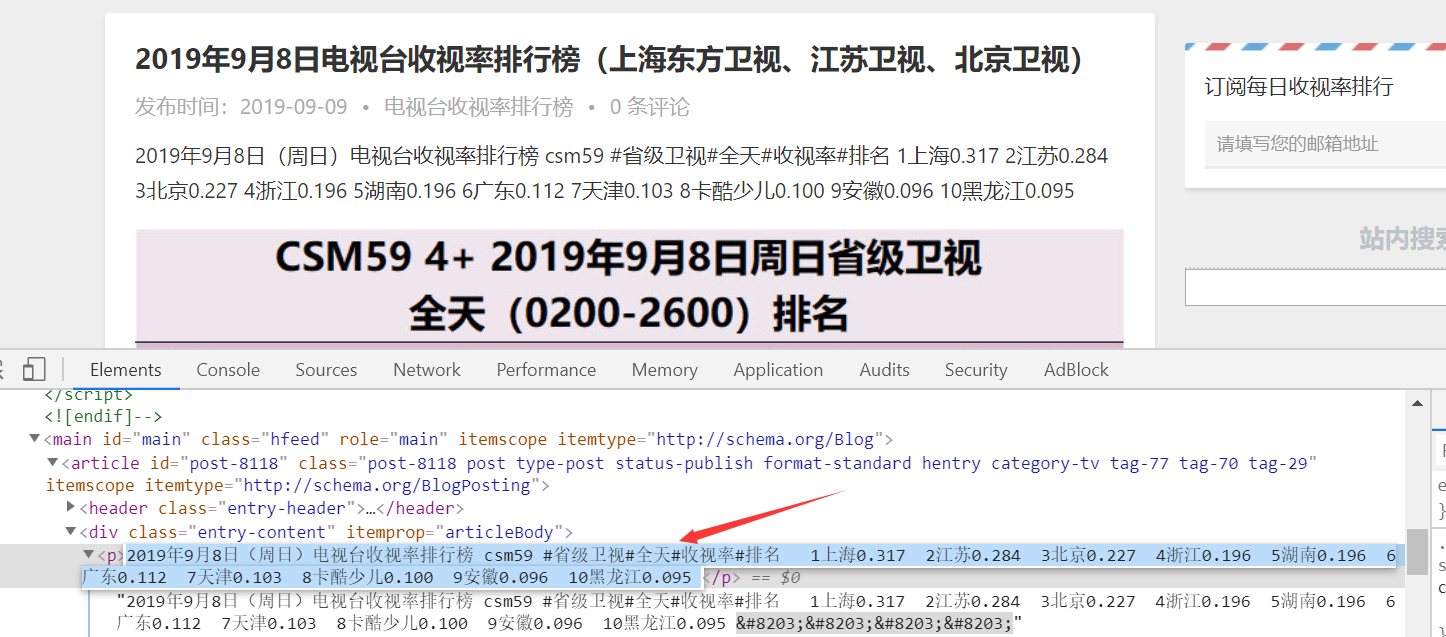
每天前10的信息发布在p标签内,存储的时候空格拆分一下
代码实现
获取每一页的静态链接
url = 'http://www.tvtv.hk/archives/category/tv/page/'
# 获取每一个网页的静态页面
for i in range(1, 100):
href = {}
print('正在爬取第' + str(i) + '页')
print(url + str(i))
doc = pq(url + str(i))
sp = doc('.status-publish')
for s in sp.items():
ha = s.find('h2 a')
href[ha.attr('title')] = ha.attr('href')
with open('TV链接列表.csv', 'a') as f:
for key in href.keys():
if key.find('榜') > 0:
f.write(key + ',' + href[key] + '\n')
从每天的静态页面中获取前十的数据
# 从每一个静态页面中获取数据
out = open('TV收视率.csv', 'w', encoding='utf-8')
with open('TV链接列表.csv', 'r') as f:
for line in f:
print(line)
strs = line.split(',')
out.write(strs[0])
doc = pq(strs[1])
p = doc.find('p:nth-child(1)').text().strip()
ps = p.split(' ')
count = 0
for item in ps:
count = count + 1
if count <= 3:
continue
j = 0
while '0' <= item[j] <= '9':
j = j + 1
out.write(',' + item[j:])
out.write('\n')
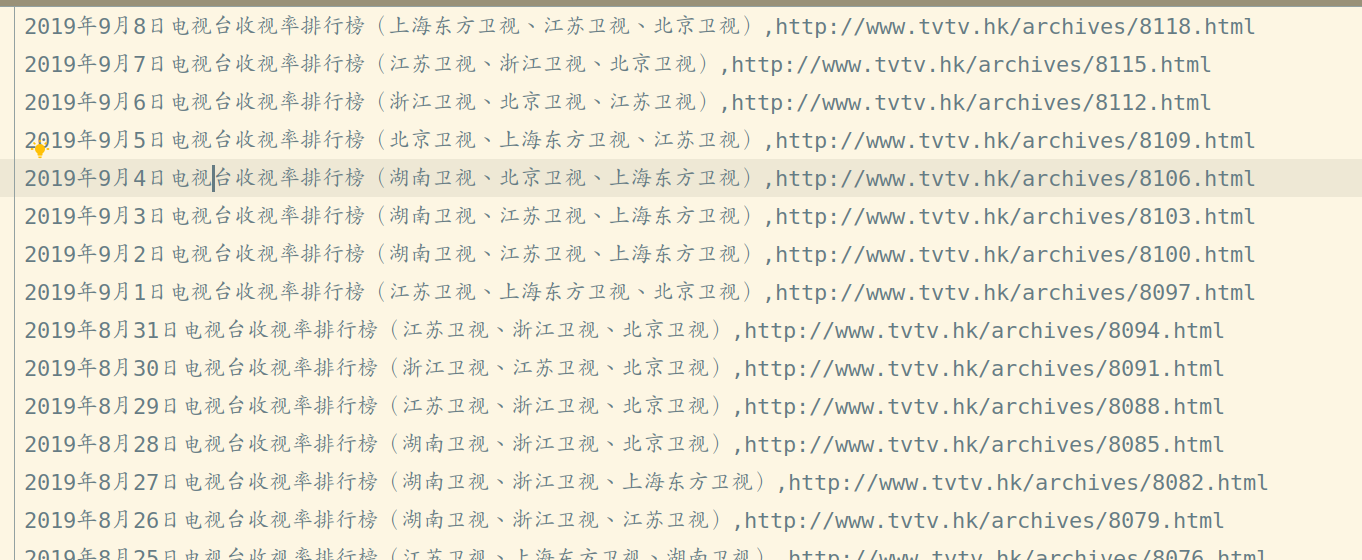
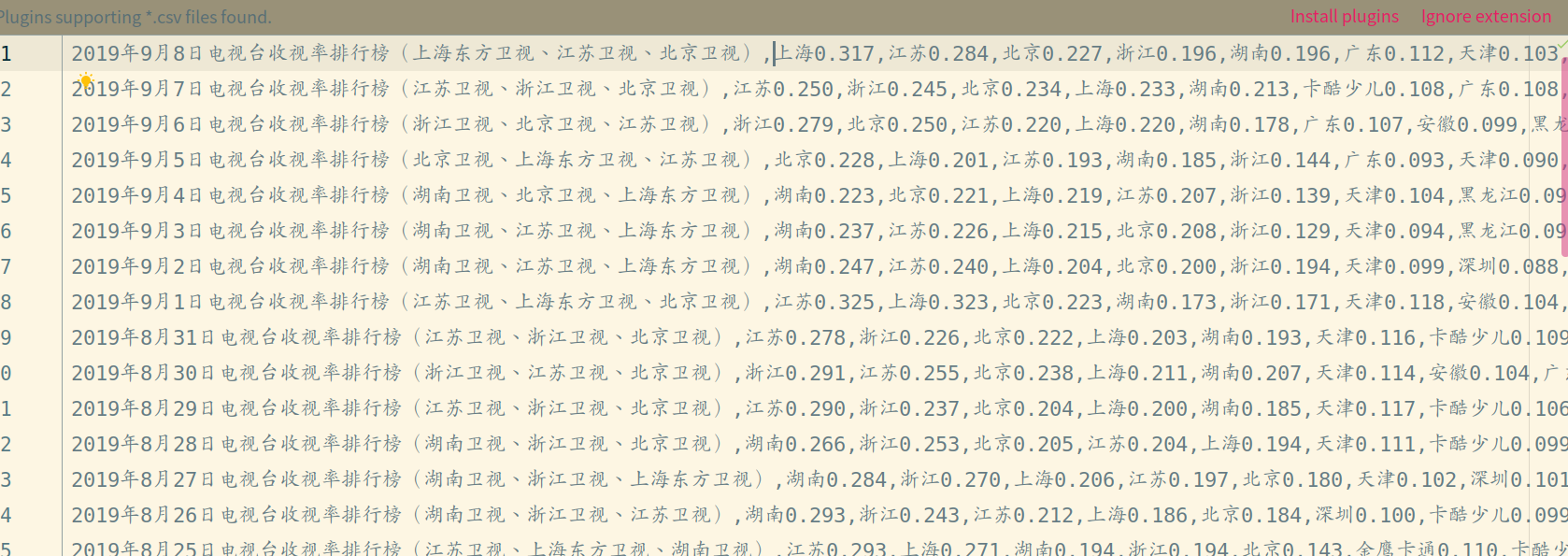
运行结果
完整代码获取:https://github.com/sstealer/WebSpider/tree/master。 感觉有帮助的话可以GitHub点个赞哦
# 深圳杯D题爬取电视收视率排行榜的更多相关文章
- 【个人】爬虫实践,利用xpath方式爬取数据之爬取虾米音乐排行榜
实验网站:虾米音乐排行榜 网站地址:http://www.xiami.com/chart 难度系数:★☆☆☆☆ 依赖库:request.lxml的etree (安装lxml:pip install ...
- python爬取b站排行榜
爬取b站排行榜并存到mysql中 目的 b站是我平时看得最多的一个网站,最近接到了一个爬虫的课设.首先要选择一个网站,并对其进行爬取,最后将该网站的数据存储并使其可视化. 网站的结构 目标网站:bil ...
- Python爬虫使用lxml模块爬取豆瓣读书排行榜并分析
上次使用了BeautifulSoup库爬取电影排行榜,爬取相对来说有点麻烦,爬取的速度也较慢.本次使用的lxml库,我个人是最喜欢的,爬取的语法很简单,爬取速度也快. 本次爬取的豆瓣书籍排行榜的首页地 ...
- Python爬取猫眼top100排行榜数据【含多线程】
# -*- coding: utf-8 -*- import requests from multiprocessing import Pool from requests.exceptions im ...
- 爬虫--requests爬取猫眼电影排行榜
'''目标:使用requests分页爬取猫眼电影中榜单栏目中TOP100榜的所有电影信息,并将信息写入文件URL地址:http://maoyan.com/board/4 其中参数offset表示其实条 ...
- scrapy爬取猫眼电影排行榜
做爬虫的人,一定离不开的一个框架就是scrapy框架,写小项目的时候可以用requests模块就能得到结果,但是当爬取的数据量大的时候,就一定要用到框架. 下面先练练手,用scrapy写一个爬取猫眼电 ...
- 使用xpath爬取猫眼电影排行榜
最近在学习xpath,在网上找资料的时候,发现一个新手经常拿来练手的项目,爬取猫眼电影前一百名排行的信息,很多都是跟崔庆才的很雷同,基本照抄.这里就用xpath自己写了一个程序,同样也是爬取猫眼电影, ...
- 记录python爬取猫眼票房排行榜(带stonefont字体网页),保存到text文件,csv文件和MongoDB数据库中
猫眼票房排行榜页面显示如下: 注意右边的票房数据显示,爬下来的数据是这样显示的: 网页源代码中是这样显示的: 这是因为网页中使用了某种字体的缘故,分析源代码可知: 亲测可行: 代码中获取的是国内票房榜 ...
- python3爬虫-爬取B站排行榜信息
import requests, re, time, os category_dic = { "all": "全站榜", "origin": ...
随机推荐
- cmd中实现代码雨的命令。。。
颜色修改时不能使用十六进制数 @echo off title digitalrain color 0b setlocal ENABLEDELAYEDEXPANSION for /l %%i in (0 ...
- 【黑马JavaWeb】.1.2反射机制
文章目录 反射:框架设计的灵魂 获取Class类对象的方式 学习视频:https://www.bilibili.com/video/av47886776?p=10 本来一万行的代码,使用框架以后简化到 ...
- *CodeIgniter框架集成支付宝即时到账SDK
客户的网站需要支付功能,我们选择了业界用的最多的支付宝即时到账支付.申请了两次将近两周的时间终于下来了,于是我开始着手测试SDK整合支付流程. SDK中的代码并不复杂,就是构造请求发送,接收并验证签名 ...
- H264编码原理以及I帧、B和P帧详解, H264码流结构分析
H264码流结构分析 http://blog.csdn.net/chenchong_219/article/details/37990541 1.码流总体结构: h264的功能分为两层,视频编码层(V ...
- [论文理解] Acquisition of Localization Confidence for Accurate Object Detection
Acquisition of Localization Confidence for Accurate Object Detection Intro 目标检测领域的问题有很多,本文的作者捕捉到了这样一 ...
- 提问(prompt)
prompt弹出消息对话框,通常用于询问一些需要与用户交互的信息.弹出消息对话框(包含一个确定按钮.取消按钮与一个文本输入框). 语法: prompt(str1, str2); 参数说明: str1: ...
- 只需体验三分钟,你就会跟我一样,爱上这款Toast
只需体验三分钟,你就会跟我一样,爱上这款Toast https://www.jianshu.com/p/9b174ee2c571
- css中的border-collapse属性如何设置表格边框线?(代码示例)
css中的border-collapse属性如何设置表格边框线?本篇文章就给大家介绍css中的border-collapse属性是什么? border-collapse属性设置表格边框线的方法.有一定 ...
- JavaScript日常学习3
JavaScript函数 函数就是包裹在花括号中的代码块,前面使用了关键词 function: function functionname() {执行代码} function myFunct ...
- 绝对好用Flash多文件大文件上传控件
本实例采用的是Uploadify上传插件,.NET程序,源程序是从网上找的,但是有Bug,已经修改好,并标有部分注释.绝对好用,支持单文件.多文件上传,支持大文件上传,已经过多方面测试,保证好用. 以 ...