python协程gevent案例:爬取斗鱼美女图片
分析
分析网站寻找需要的网址
用谷歌浏览器摁F12打开开发者工具,然后打开斗鱼颜值分类的页面,如图:
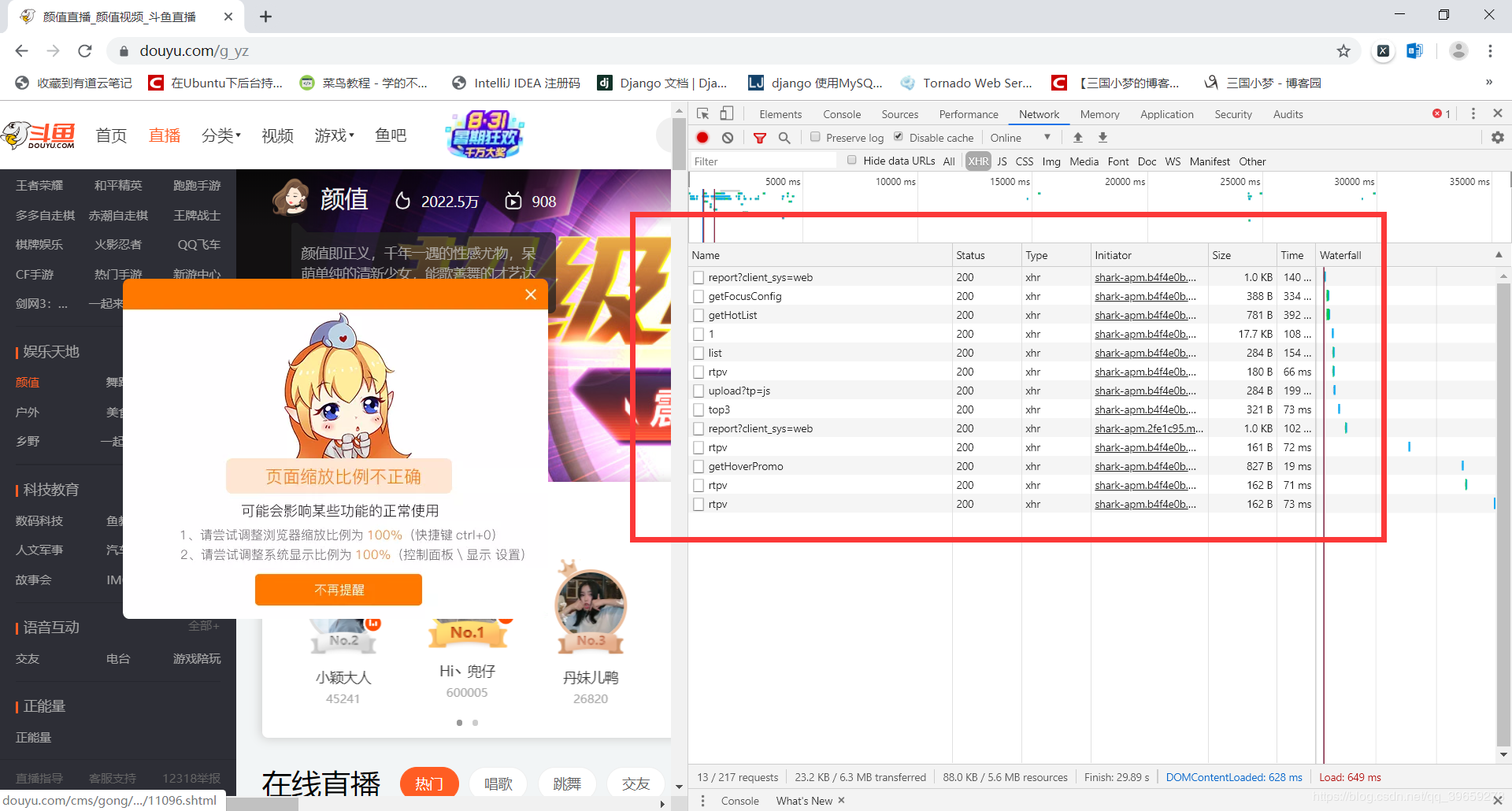
在里面的请求中,最后发现它是以ajax加载的数据,数据格式为json,如图:

圈住的部分是我们需要的数据,然后复制它的网址为https://www.douyu.com/gapi/rknc/directory/yzRec/1,出于学习目的只爬取第一页(减少服务器压力)。然后把网址放到浏览器中测试是否可以访问。如图:

结果正常。
分析json数据,提取图片链接
最后分析发现json中的data里面的rl是每个房间的信息,大概有200条左右,拿出其中的一条查询里面的图片链接。
{
"rid": 1282190,
"rn": "大家要开心啊~",
"uid": 77538371,
"nn": "鲸鱼欧尼",
"cid1": 8,
"cid2": 201,
"cid3": 581,
"iv": 1,
"av": "avatar_v3/201908/d62c503c603945098f2c22d0d95c3b2e",
"ol": 610574,
"url": "/1282190",
"c2url": "/directory/game/yz",
"c2name": "颜值",
"icdata": {
"217": {
"url": "https://sta-op.douyucdn.cn/dy-listicon/king-web.png-v3.png",
"w": 0,
"h": 0
}
},
"dot": 2103,
"subrt": 0,
"topid": 0,
"bid": 0,
"gldid": 0,
"rs1": "https://rpic.douyucdn.cn/live-cover/appCovers/2019/08/01/1282190_20190801002745_big.jpg/dy1",
"rs16": "https://rpic.douyucdn.cn/live-cover/appCovers/2019/08/01/1282190_20190801002745_small.jpg/dy1",
"utag": [
{
"name": "呆萌鲸鱼",
"id": 111405
},
{
"name": "美美美",
"id": 41
},
{
"name": "萌萌哒",
"id": 520
},
{
"name": "刀神老婆",
"id": 132367
}
],
"rpos": 0,
"rgrpt": 1,
"rkic": "",
"rt": 2103,
"ot": 0,
"clis": 1,
"chanid": 0,
"icv1": [
[
{
"id": 217,
"url": "https://sta-op.douyucdn.cn/dy-listicon/web-king-1-10-v3.png",
"score": 994,
"w": 0,
"h": 0
}
],
[
],
[
],
[
]
],
"ioa": 0,
"od": ""
}
测试发现rs16是房间的图片,如果把链接最后的/dy1去掉的话,图片就成大图了,心里美滋滋。
代码实现
import gevent
import json
from urllib import request
from gevent import monkey
# 使用gevent打补丁,耗时操作自动替换成gevent提供的模块
monkey.patch_all()
# 图片存放的目录
ROOT = "./images/"
# 设置请求头,防止被反爬虫的第一步
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36 "
}
def download(img_src):
# 把每个链接最后的/dy1去掉
img_src: str = img_src.replace("/dy1", "")
# 提取图片名
file_name: str = img_src.split("/")[-1]
response = request.urlopen(request.Request(img_src, headers=header))
# 保存到本地
with open(ROOT + file_name, "wb") as f:
f.write(response.read())
print(file_name, "下载完成!")
if __name__ == '__main__':
req = request.Request("https://www.douyu.com/gapi/rknc/directory/yzRec/1", headers=header)
# 把json数据转换成python中的字典
json_obj = json.loads(request.urlopen(req).read().decode("utf-8"))
tasks = []
for src in json_obj["data"]["rl"]:
tasks.append(gevent.spawn(download, src["rs16"]))
# 开始下载图片
gevent.joinall(tasks)
结果
由于使用的是协程,比线程效率更高,不到1秒就把第一页的图片全部爬取下来了。效果如图:
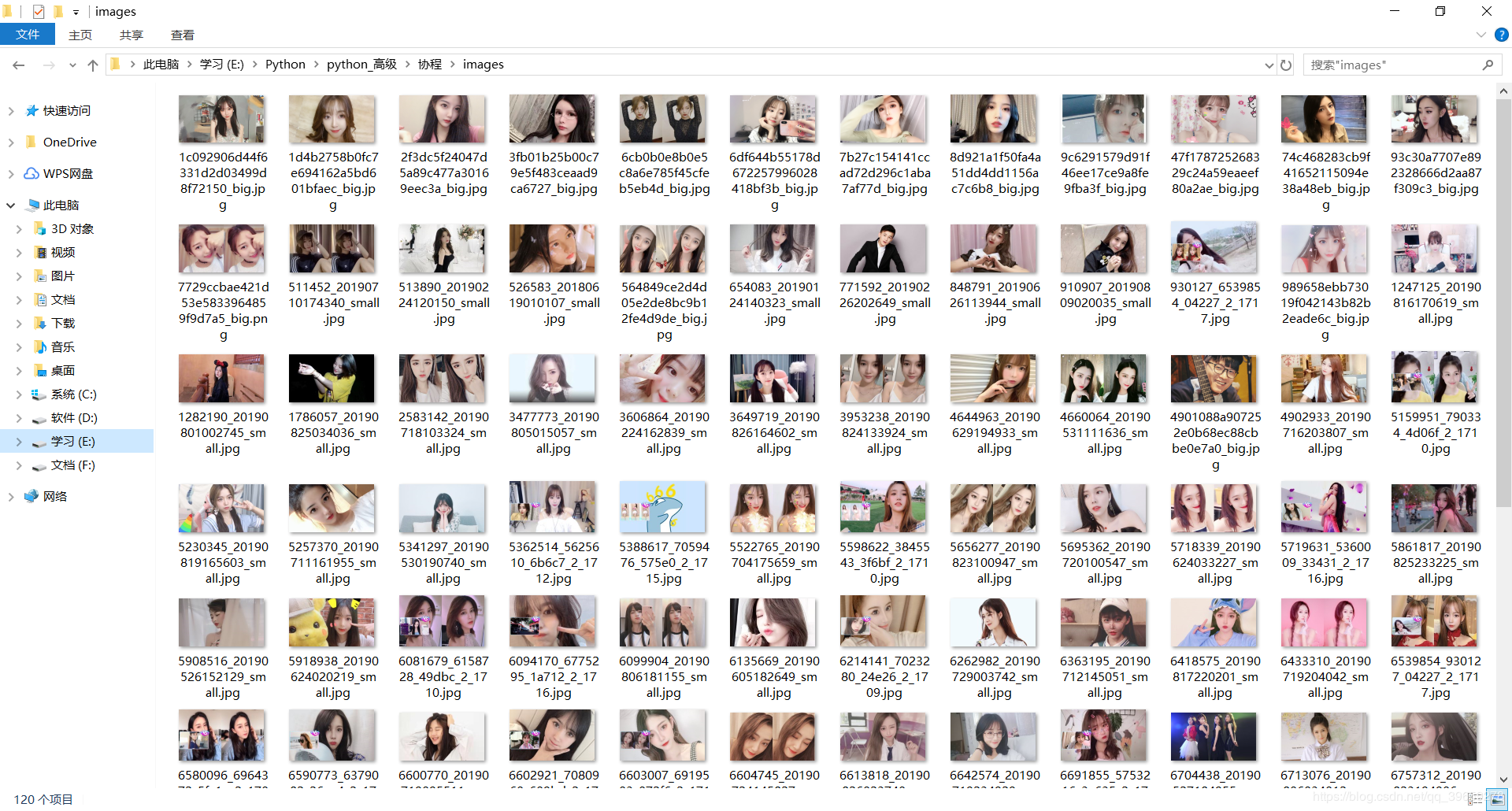
此案例仅用于学习gevent的使用。
python协程gevent案例:爬取斗鱼美女图片的更多相关文章
- 单线程多任务协程vip电影爬取
单线程多任务协程vip电影爬取 --仅供学习使用勿作商用如有违规后果自负!!! 这几天一直在使用python爬取电影,主要目的也是为了巩固前段时间强化学习的网络爬虫,也算是一个不错的检验吧,面对众 ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- python 多协程异步IO爬取网页加速3倍。
from urllib import request import gevent,time from gevent import monkey#该模块让当前程序所有io操作单独标记,进行异步操作. m ...
- python 爬虫入门----案例爬取上海租房图片
前言 对于一个net开发这爬虫真真的以前没有写过.这段时间学习python爬虫,今天周末无聊写了一段代码爬取上海租房图片,其实很简短就是利用爬虫的第三方库Requests与BeautifulSoup. ...
- Python协程 Gevent Eventlet Greenlet
https://zh.wikipedia.org/zh-cn/%E5%8D%8F%E7%A8%8B 协程可以理解为线程中的微线程,通过手动挂起函数的执行状态,在合适的时机再次激活继续运行,而不需要上下 ...
- python 协程 gevent 简单测试
串行测试 from gevent import monkey; monkey.patch_all()#有IO才做时需要这一句 import gevent import requests,time st ...
- python进程池爬取下载美女图片(xpath)--lowbiprogrammer
# -*- coding: utf-8 -*-import requests,osfrom lxml import etreeimport multiprocessingfrom retrying i ...
- 用Python爬取斗鱼网站的一个小案例
思路解析: 1.我们需要明确爬取数据的目的:为了按热度查看主播的在线观看人数 2.浏览网页源代码,查看我们需要的数据的定位标签 3.在代码中发送一个http请求,获取到网页返回的html(需要注意的是 ...
- python协程详解,gevent asyncio
python协程详解,gevent asyncio 新建模板小书匠 #协程的概念 #模块操作协程 # gevent 扩展模块 # asyncio 内置模块 # 基础的语法 1.生成器实现切换 [1] ...
随机推荐
- jmeter下载安装
jmeter运行依靠java环境 一.根据jmeter版本不同要求java环境则不同 jmeter官网下载地址:http://jmeter.apache.org/download_jmeter.cgi ...
- 在Spring Boot快捷地读取文件内容的若干种方式
引言: 在Spring Boot构建的项目中,在某些情况下,需要自行去读取项目中的某些文件内容,那该如何以一种轻快简单的方式读取文件内容呢? 基于ApplicationContext读取 在Spri ...
- C++中 关于操作符的重载
C++实现了类的定义,也可以对类之间的操作符进行定义,又叫重载. 例如同类之间的 加.减法,赋值等等操作. 具体看http://blog.csdn.net/zhy_cheng/article/deta ...
- 使用MyBatis的动态SQL表达式时遇到的“坑”(integer)
现有一项目,ORM框架使用的MyBatis,在进行列表查询时,选择一状态(值为0)通过动态SQL拼接其中条件但无法返回正常的查询结果,随后进行排查. POJO private Integer stat ...
- Angular引入第三方库
原文已经写的很好了.原文链接: https://blog.csdn.net/yuzhiqiang_1993/article/details/71215232 加上2点给自己用,引入bootstrap样 ...
- linux常用命令(11)less命令
less 工具也是对文件或其它输出进行分页显示的工具,应该说是linux正统查看文件内容的工具,功能极其强大.less 的用法比起 more 更加的有弹性.在 more 的时候,我们并没有办法向前面翻 ...
- centos 7安装python3及相关模块
一.python3安装 1.cd /usr/bin 2.mv python python.bak 3.https://www.python.org/ftp/python/网站选择合适的版本 4.wge ...
- Python列表排序
1.冒泡排序 冒泡排序(Bubble Sort)是一种简单的排序算法.它重复地遍历要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来.遍历数列的工作是重复地进行直到没有再需要交换,也就 ...
- ubuntu install themes && use it
one step: I am going to show you the installation of a theme with Numix theme and Unity Tweak Tool. ...
- 微擎-T
微擎菜单栏对应的数据库表 ims_modules_bindings 小程序前端uniacid的配置,微擎后台进入小程序应用时鼠标移动至管理查看链接即可(不点击) ims_account_wxapp微擎 ...