JuiceFS v1.3-Beta1:一亿文件备份分钟级完成,性能优化全解析
在最新发布的 JuiceFS v1.3 Beta1 版本中,我们引入了一种全新的二进制备份机制,旨在更高效地应对亿级文件规模下的备份与迁移场景。相比现有的 JSON 备份方式,该机制在导入导出元数据时不仅大幅提升了处理速度,还显著降低了内存占用。
01 JSON 备份机制回顾
JuiceFS 自 v0.15 版本支持通过 JSON 格式进行元数据的导入与导出。该功能不仅可用于日常容灾备份,还支持在不同元数据引擎间做迁移,适配因业务规模或数据要求变化所带来的引擎切换场景. 如因数据可靠性要求,用户需要从 Redis 迁移到 SQL DB,或者因数据量级增长,从 Redis 等切换到 TiKV 等。
JSON 格式的一大优势在于其良好的可读性, 其在备份过程中保持了完整的目录树结构, 将文件对象的属性、拓展属性、chunks 等都一起展示,一目了然。然而,在导入与导出时,为了保持这种结构和输出顺序,系统需要处理上下文信息,带来了额外的计算与内存开销。尽管此前版本已针对性地做了多项优化,但在处理大量级的备份时,耗时和占用内存仍然比较大。此外,随着系统规模的持续扩大,可读性的重要性逐渐下降,用户更关注的是整体备份的统计信息和数据校验机制。
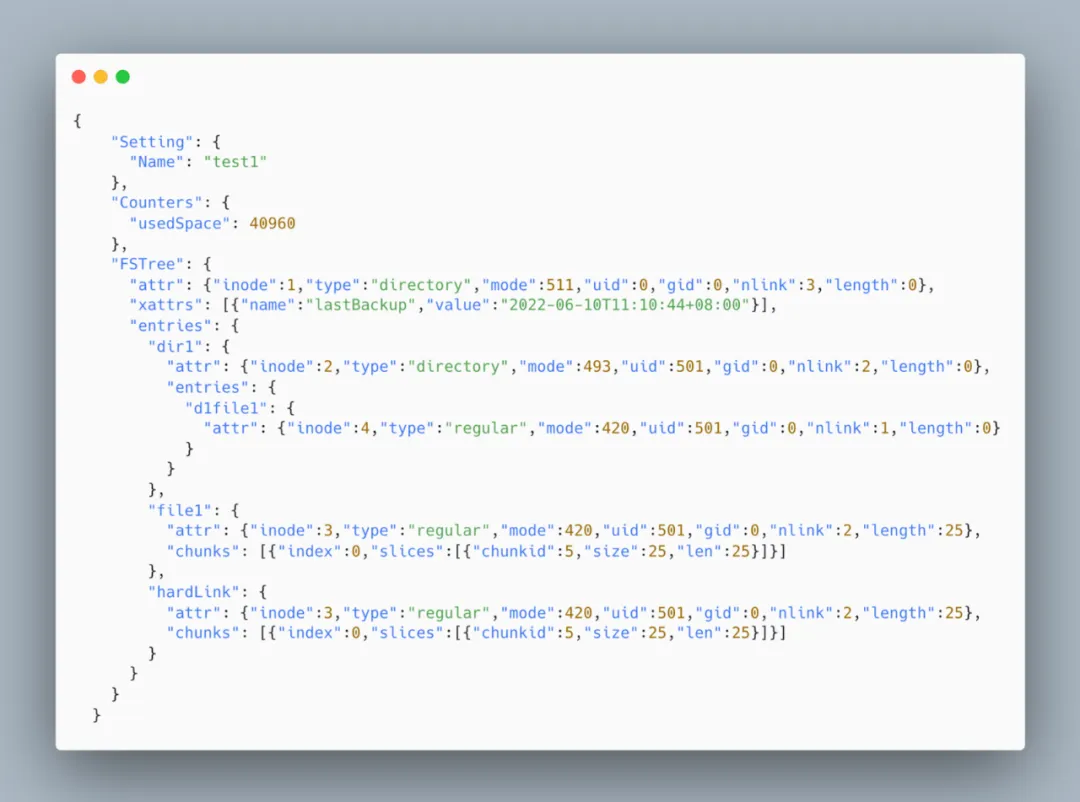
原社区版本提供两种导出 JSON 备份方式:
- 普通导出,占用内存少但性能低;
- Fast 模式,通过快照缓存上下文信息,减少随机查询,性能高但是占用内存太高。
当前社区许多文件系统规模已经过亿,性能与内存就凸显得更加重要。在这类大规模场景下,现有的两种 JSON 备份方式均显现出明显的性能瓶颈和资源限制。
此外,虽然不同元数据引擎提供了原生的备份工具,能够高效的对元数据进行备份,比如 Redis 的 RDB,MySQL 的 mysqldump 工具,TiKV 的 BR 工具等。但是这些工具都需要额外处理JuiceFS 元数据的一致性问题,也不支持跨引擎间迁移。
02 二进制备份实现机制
为了提升导入导出的性能与可扩展性,JuiceFS v1.3 引入了基于 Google Protocol Buffer(Protobuf) 的二进制备份格式。该格式以性能优先为核心设计原则,同时综合兼顾了兼容性、备份体积控制与跨场景的通用性,该格式性能可参考此链接。
与传统的 JSON 格式不同,二进制格式采用了扁平化的存储结构,不再依赖树状目录所需的上下文信息。这样在导出时,既可以避免普通模式中频繁的随机查询,也无需像 Fast 模式那样依赖大量内存缓存,从而同时提
升了性能并降低了资源消耗。
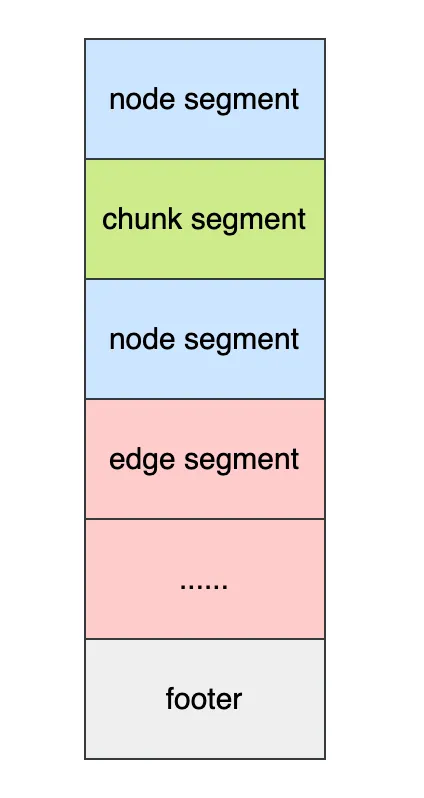
存储结构设计
- 整体结构类似于 SQL DB 中的存储结构,每种元数据(ex. node, edge, chunk…)独立存储,与其他元数据没有关联, 保证导入导出过程可以独立处理;
- 主体由多个段(segment)构成,同一类型的元数据可以拆分成多个段,不同类型的元数据段可交叉,便于在导入导出时做并发分批处理。
- 文件尾部有一个 footer 段,包含版本号,以及其他元数据段的索引信息,包括位移、数量信息。这使得备份文件支持随机访问,便于按类型或特定数据段进行处理、分析或校验。
1.3 版本 load 工具新增了对二进制备份的解析功能,支持用户快速查看备份信息。由于备份格式采用的是 Protocol Buffer (PB) 格式,用户也可以方便的实现一些备份处理分析工具。
以下是 load 工具的一些示例,展示新版二进制的备份内容:
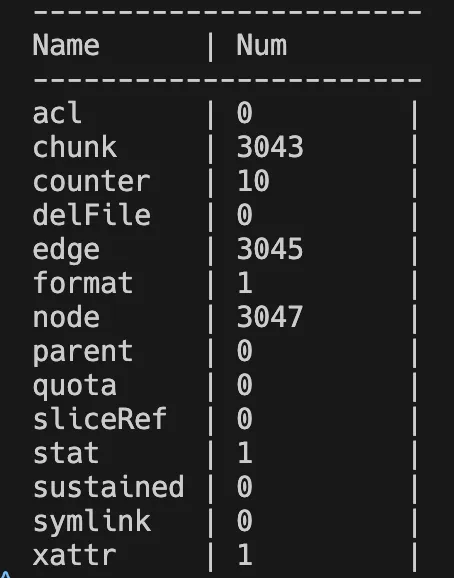
# 查看备份元数据类型统计信息
$ juicefs load redis.bak --binary --stat
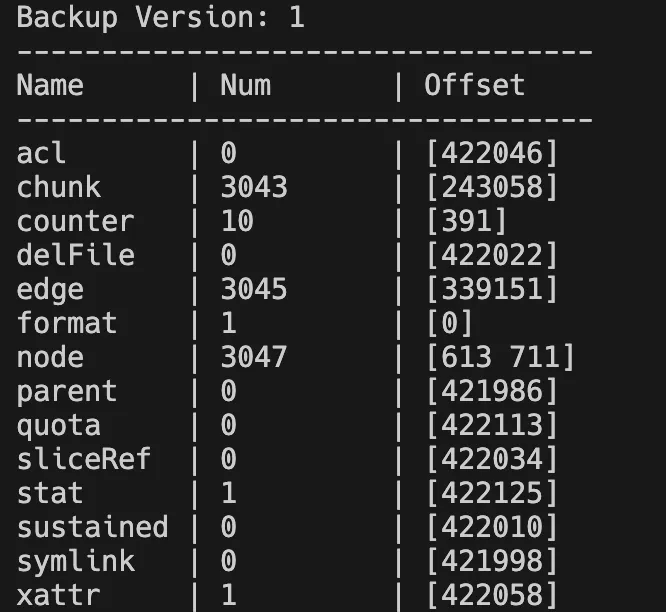
# 查看备份元数据段信息(获取offset)
$ juicefs load redis.bak --binary --stat --offset=-1
# 查看备份指定段(指定offset)信息
$ juicefs load redis.bak --binary --stat --offset=0
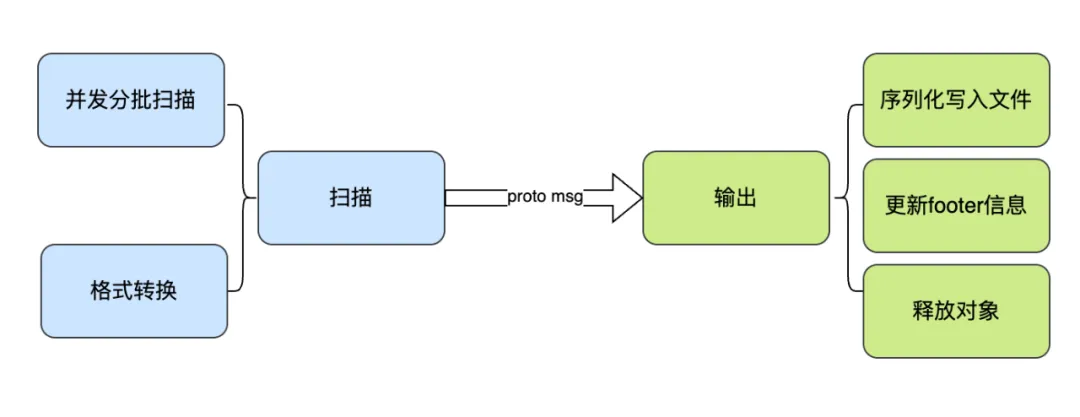
导入导出流程解析
导出过程分为两个阶段:扫描和输出。其中,输出阶段主要负责备份文件相关的处理操作;扫描阶段根据不同元数据引擎, 实现方式略有差异。
例如,对于 SQL DB,不同类型的元数据存储于不同表,因此导出时只需分别扫描这些表,并按格式转换保存。对于超大体量的表(ex. node, edge, chunk),系统会采用分批并发查询的方式提升处理效率。
而 Redis 和 TiKV 是 kv 格式,并且部分类型的 key 以 inode 作为前缀,这样的设计是为了访问同一个 inode 的元数据时更高效。为避免重复访问底层引擎,在导出过程中会对这些类型的元数据统一一次扫描,然后在内部做区分处理。
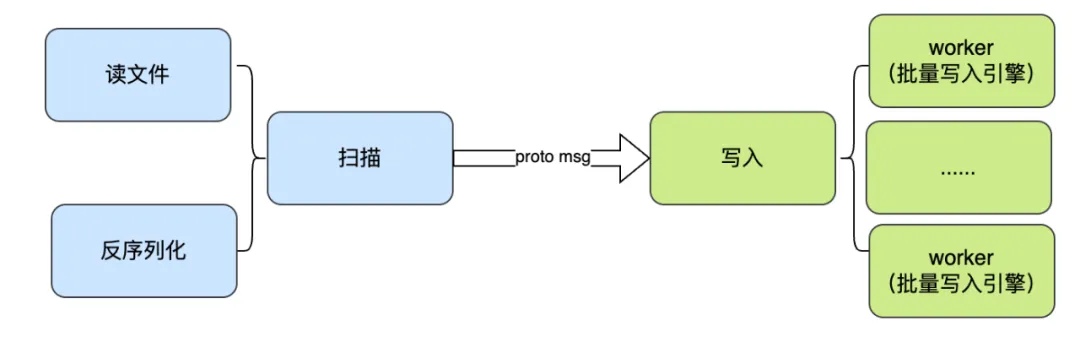
导入过程也分扫描和写入两部分,扫描是对备份文件的读取和格式处理;写入通过多并发批量写入元数据引擎。对于 KV 引擎,比如 TiKV 底层是 LSM 存储结构,为了减少覆盖冲突,会将数据先做排序后再并发写入。
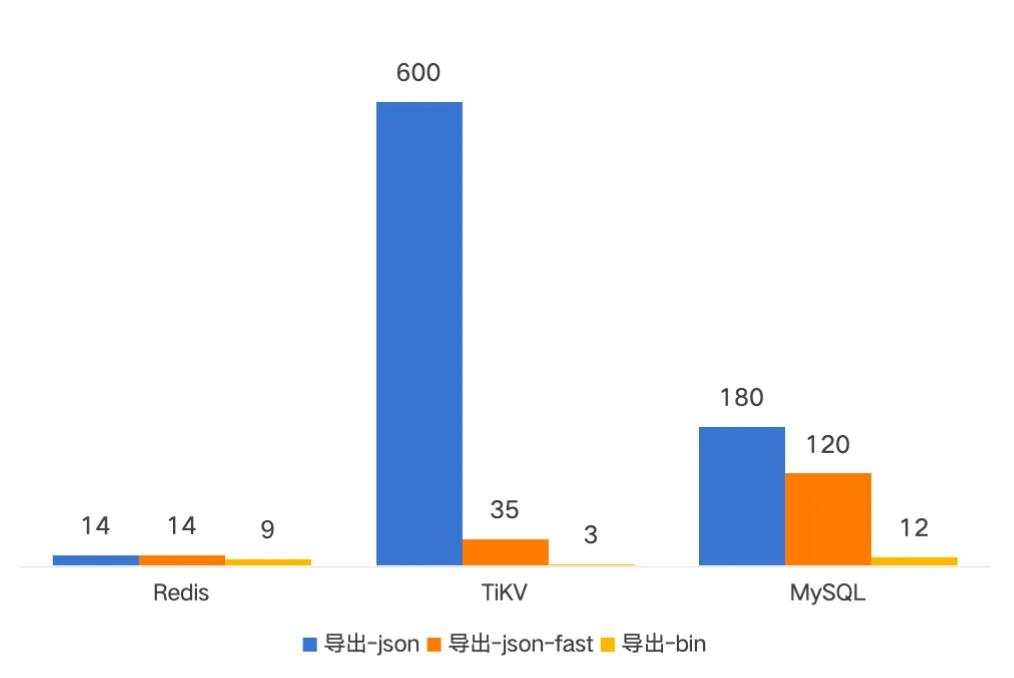
03 性能优化测试
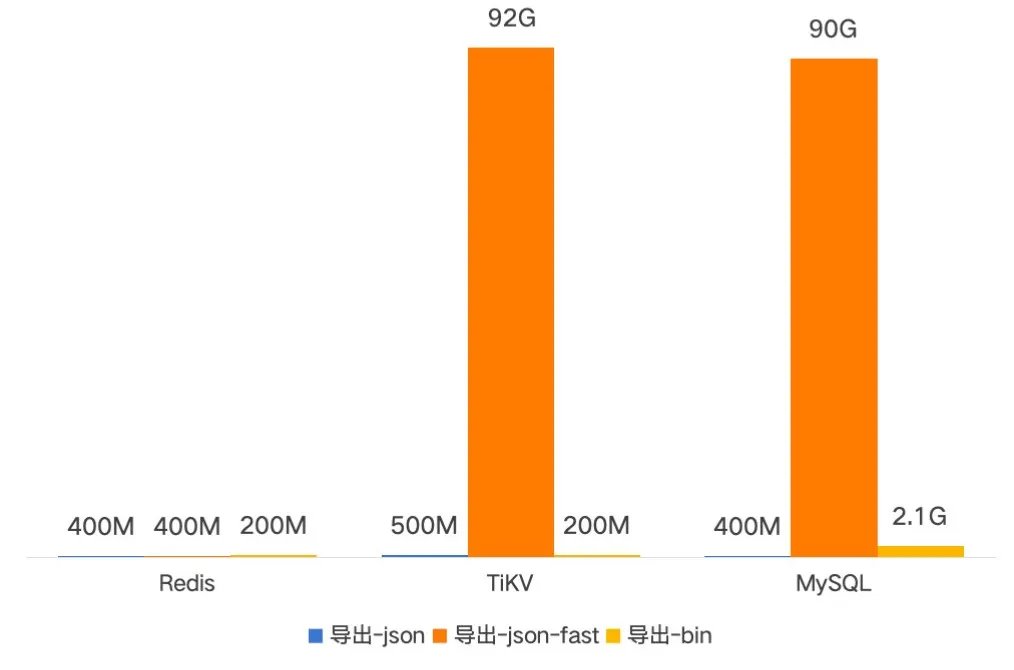
大小
新版本 PB 格式备份在未压缩前只需要原先 JSON 格式的三分之一大小
性能
下面是一亿文件的备份导入导出的耗时对比,新版备份耗时基本在分钟级别。导入时间是原先的二分之一到十分之一;导出时间是原先的四分之一左右。
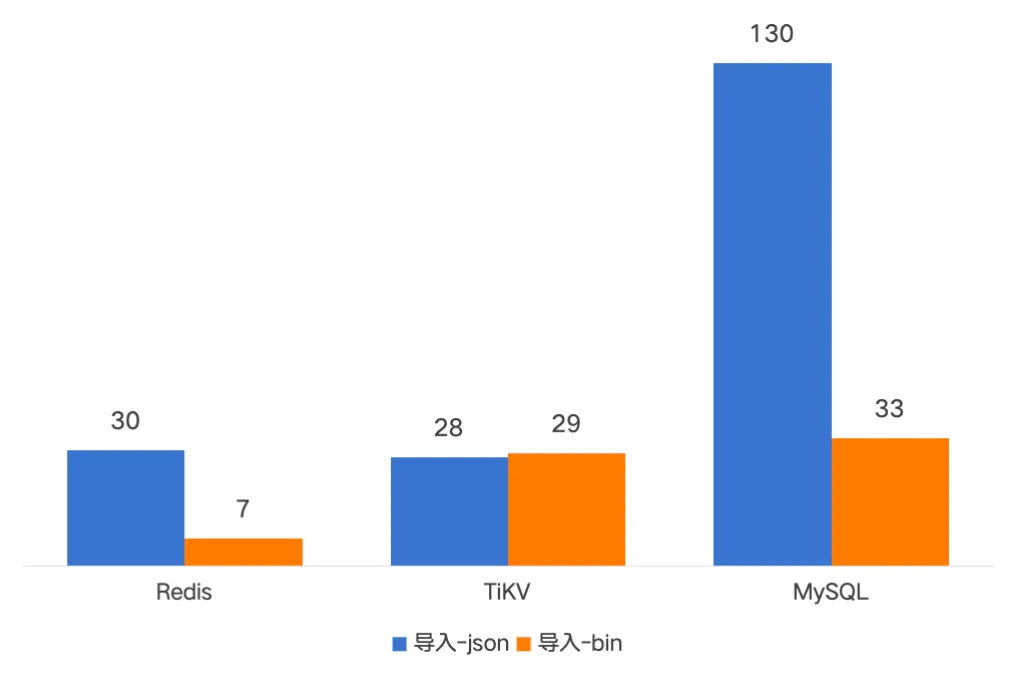
内存
新版本备份内存占用小于1GiB,并且与并发相关,可以通过调整并发大小和批次大小控制。
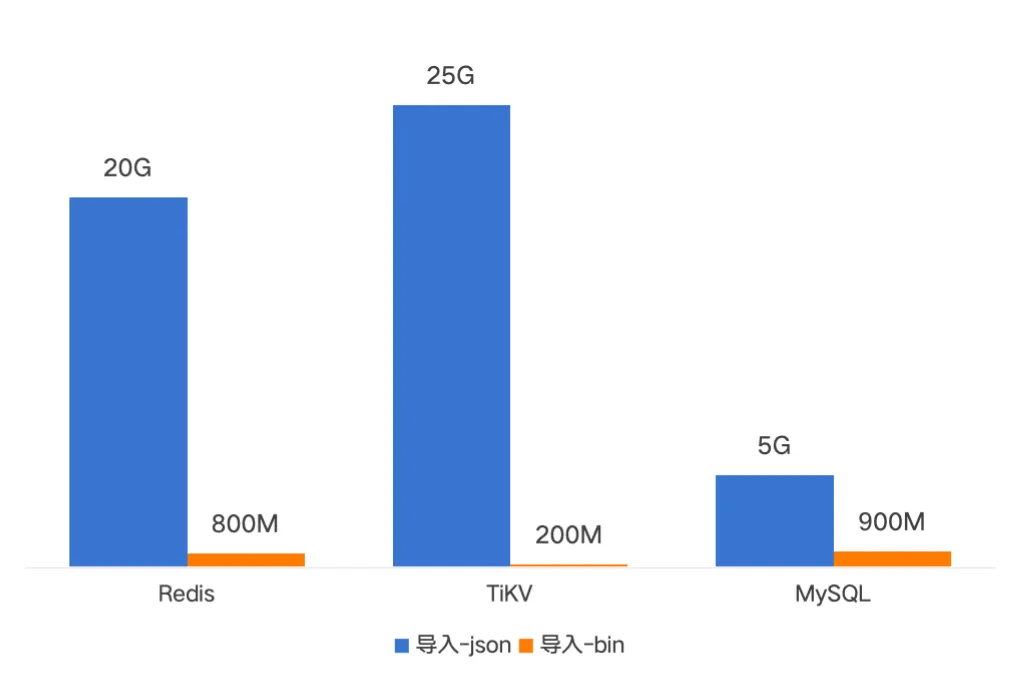
04 小结
随着社区中越来越多用户面对亿级规模的文件系统的挑战,备份机制的性能、内存占用和跨引擎适配能力变得尤为关键。JuiceFS 在 v1.3 版本中引入的二进制备份格式:通过采用 Protocol Buffer 和扁平化设计,显著提升导入导出效率,降低资源消耗,并提升备份结构的灵活性与可操作性。未来,我们将继续围绕数据保护、容灾迁移、工具链完善等方面进行优化,欢迎社区用户反馈更多实际场景中的需求。
希望这篇内容能够对你有一些帮助,如果有其他疑问欢迎加入 JuiceFS 社区与大家共同交流。
JuiceFS v1.3-Beta1:一亿文件备份分钟级完成,性能优化全解析的更多相关文章
- 亿级 Elasticsearch 性能优化
前言 最近一年使用 Elasticsearch 完成亿级别日志搜索平台「ELK」,亿级别的分布式跟踪系统.在设计这些系统的过程中,底层都是采用 Elasticsearch 来做数据的存储,并且数据量都 ...
- 【HBase调优】Hbase万亿级存储性能优化总结
背景:HBase主集群在生产环境已稳定运行有1年半时间,最大的单表region数已达7200多个,每天新增入库量就有百亿条,对HBase的认识经历了懵懂到熟的过程.为了应对业务数据的压力,HBase入 ...
- Hbase万亿级存储性能优化总结
背景 hbase主集群在生产环境已稳定运行有1年半时间,最大的单表region数已达7200多个,每天新增入库量就有百亿条,对hbase的认识经历了懵懂到熟的过程.为了应对业务数据的压力,hbase入 ...
- 腾讯正式开源图计算框架Plato,十亿级节点图计算进入分钟级时代
腾讯开源再次迎来重磅项目,14日,腾讯正式宣布开源高性能图计算框架Plato,这是在短短一周之内,开源的第五个重大项目. 相对于目前全球范围内其它的图计算框架,Plato可满足十亿级节点的超大规模图计 ...
- 腾讯开源进入爆发期,Plato助推十亿级节点图计算进入分钟级时代
腾讯开源再次迎来重磅项目,14日,腾讯正式宣布开源高性能图计算框架Plato,这是在短短一周之内,开源的第五个重大项目. 相对于目前全球范围内其它的图计算框架,Plato可满足十亿级节点的超大规模图计 ...
- JuiceFS v1.0.0 Beta1 发布,加强数据安全能力
在 JuiceFS 开源一周年之际,我们迎来了首个里程碑版本 JuiceFS v1.0.0 Beta1,并将开源许可从 AGPL v3 修改为 Apache License 2.0. JuiceFS ...
- JuiceFS v1.0 beta3 发布,支持 etcd、Amazon MemoryDB、Redis Cluster
JuiceFS v1.0 beta3 在元数据引擎方面继续增强,新增 etcd 支持小于 200 万文件的使用场景,相比 Redis 可以提供更好的可用性和安全性.同时支持了 Amazon Memor ...
- JuiceFS V1.0 RC1 发布,大幅优化 dump/load 命令性能, 深度用户不容错过
各位社区的伙伴, JuiceFS v1.0 RC1 今天正式发布了!这个版本中,最值得关注的是对元数据迁移备份工具 dump/load 的优化. 这个优化需求来自于某个社区重度用户,这个用户在将亿级数 ...
- 40+倍提升,详解 JuiceFS 元数据备份恢复性能优化之路
JuiceFS 支持多种元数据存储引擎,且各引擎内部的数据管理格式各有不同.为了便于管理,JuiceFS 自 0.15.2 版本提供了 dump 命令允许将所有元数据以统一格式写入到 JSON 文件进 ...
- 财务平台亿级数据量毫秒级查询优化之elasticsearch原理解析
财务平台进行分录分表以后,随着数据量的日渐递增,业务人员对账务数据的实时分析响应时间越来越长,体验性慢慢下降,之前我们基于mysql的性能优化做了一遍,可以说基于mysql该做的优化已经基本上都做了, ...
随机推荐
- Python文档字符串设置--在PyCharm中
引言 在PyCharm中,只要我们在一个函数下面输入一个三引号"""并回车,PyCharm会自动帮我们补全文档字符串,如下图所示: 然而,有些小伙伴的pycharm却无法 ...
- C# WebClient调用WebService
WebClient调用WebService (文末下载完整代码) 先上代码: object[] inObjects = new[] { "14630, 14631" }; Http ...
- Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!
在众多开源项目中,高颜值.功能强大且部署简单的项目往往更能俘获开发者的心.然而,实际部署 Web 应用时,面对数据库.缓存.消息队列等复杂的依赖关系,常常令人头疼.Docker 的开源为我们普及了容器 ...
- WSL2 - Ubuntu 22.04使用记录
1 安装 搭配Windows Terminal使用为佳,在微软商店可下载: 然后依照官网描述即可. 命令行中运行wsl --install即可.不过由于想自行指定发行版,于是: wsl --list ...
- DBeaver连接mysql时,报错Public Key Retrieval is not allowed
解决 在新建连接的时候,驱动属性里设置 allowPublicKeyRetrieval 的值为 true.
- mysql frm、MYD、MYI数据文件恢复,导入MySQL中
前言 .frm..MYI..MYD 文件分别是 MySQL 的 MyISAM存储引擎存储的表结构.索引.数据文件. 简单方法恢复数据 .frm..MYI..MYD文件如果直接以文本打开,全部会以二进制 ...
- HashMap-线程不安全的原因
前言 HashMap线程安全的问题,在各大面试中都会被问到,属于常考热点题目.虽然大部分读者都了解它不是线程安全的,但是再深入一些,问它为什么不是线程安全的,仔细说说原理,用图画出一种非线程安全的情况 ...
- 2021年扩展DevOps的6种方法
2021年扩展DevOps的6种方法 加强devops流程的自动化 为了满足快速.高质量应用程序交付的需求,现代软件团队需要一种超越常规性能测试的方法.在这里,以devops为中心的方法可以提供更快. ...
- 9. RabbitMQ 消息队列幂等性,优先级队列,惰性队列的详细说明
9. RabbitMQ 消息队列幂等性,优先级队列,惰性队列的详细说明 @ 目录 9. RabbitMQ 消息队列幂等性,优先级队列,惰性队列的详细说明 1. RabbitMQ 消息队列的 " ...
- Springboot连接Greenplum,分页查询
1.springboot分页查询greenplum数据报错: org.mybatis.spring.MyBatisSystemException: nested exception is org.ap ...