关于Bevy中的原型Archetypes
认识Bevy中的原型
Bevy是基于ECS(Entity-Component-System)架构的游戏引擎,其中的Entity实体是游戏中的一个基本对象,但实体本身通常只是一个标识id,它不包含任何具体的数据或行为,只是组件(Component)的容器。
具体一点,要在Bevy(或是绝大多数基于ECS架构的游戏引擎)的游戏世界中去创建一个实体,其做法通常是创建一个包含一组组件的合集,该组件合集从概念上来表达某种游戏实体。
例如,创建一个包含生命值(Health)、位置(Position)的敌人角色,我们并不会定义一个名为Enemy的类型去继承某些对象,为其添加生命值数据和位置数据,而是定义3个组件:Enemy、Health以及Position,他们都是组件,当我们同时生成一个包含这3个组件的合集的时候,从概念上它就成为了一个包含生命值以及位置的敌人角色实体:

针对上述实体的表现形式,从底层存储的角度来看,我们可以先假设通过表格table的每一行记录来表达实体:

上图表示游戏世界中的两个敌人实体,每个实体包含独立的
Position和Health组件数据。
接下来让我们加入一个“玩家”角色,我们首先需要新增一个Player组件,然后在游戏世界中创建包含Player、Postion以及Health三个组件的合集,该实体从概念上就视为一个“玩家”角色,同时按照之前表格的数据表现形式,我们需要给对应的表格再增加一列Player,游戏世界对应的实体情况如下:

我们可以很显然想到上述table存在一个问题:随着后续实体增多,这些实体包含的组件千变万化,会造成这个table表格每一行记录是不连续的,且列会越来越多。
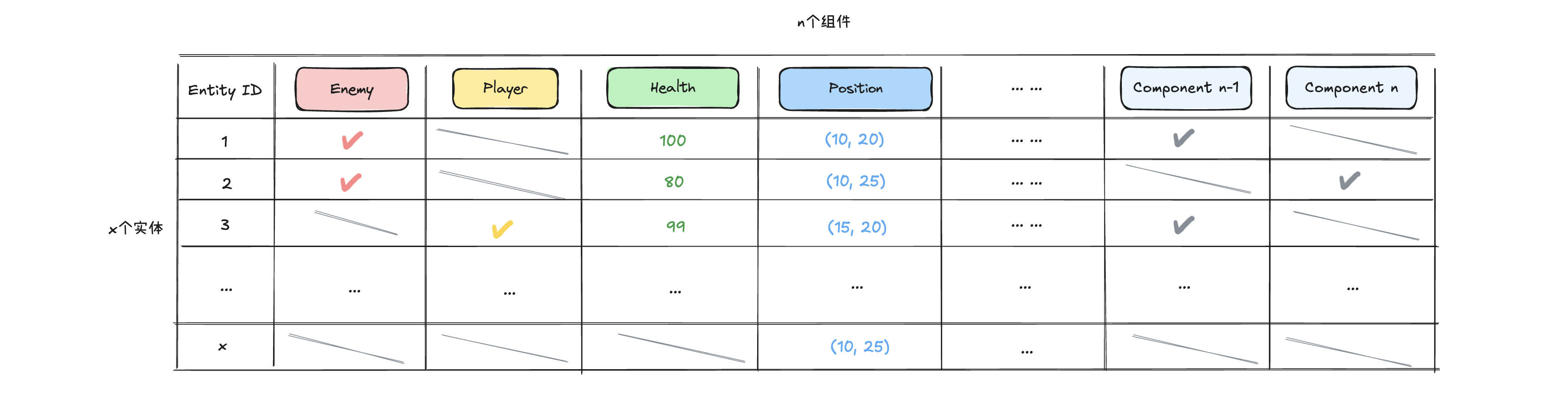
此时如果我们想写向量化的代码来算法优化处理这些数组记录,那么上述结构中不连续处的空值将会影响其效果。
向量化编程意味着一次对整个数组或数据矢量进行操作的代码,而不是顺序处理单个元素。
向量化操作可以使用像SIMD(单指令流多数据流)这样的硬件优化来有效地执行。这些指令允许在多个数据元素上同时执行相同的操作,通常会提高性能。
为了解决上述的数组元素不连续的问题,Bevy将包含不同组件的实体拆分到不同的记录表中:

可以看到,原本包含所有实体记录的单个table拆分为两种table,同时其每一行记录是连续的。在Bevy中,会将这两种表(组件类型构成)视为两种原型(Archetype)。
拆分为多个原型的优势
读者可能会好奇这样做拆分的目的是什么。实际上,拆分目的是能够充分利用并行计算,在Bevy内部同时处理不同的系统。假设现在有如下两个系统(system):
fn handle_player_position(
player_positions: Query<&mut Position, With<Player>>,
) {
// ...
}
fn handle_not_player_position(
not_player_positions: Query<&mut Position, Without<Player>>
) {
// ...
}
从系统1handle_player_position的query参数我们可以知道,运行该系统时,我们会处理具有Player组件的实体的位置数据,而从系统2handle_not_player_position的query我们知道在运行该系统时,会处理不具有Player组件的实体的位置数据。
对于拆分的table,我们可以很容易的完成并行计算,因为系统1只会查询table1的记录,而系统2则肯定只会查询table2的记录,而不会查询到table1中:

关于原型的创建
当我们调用Bevy提供的API来构建实体的时候,Bevy就会根据此时所传入的组件列表来查找并使用或新建的一个原型。即,如果找到了满足当前组件列表定义的原型时,就直接使用该已存在的原型,此时只需要把这一组组件的一些上下文(特别是id关系等)记录到原型中;如果没有找到满足的原型,则新建一个原型实例,同样把上述的相关上下文保存到该新建的原型中,并在后续使用。
Bevy通过惰性初始化边的映射关系,仅在首次遇到组件变更时创建新原型并记录边,后续直接复用。

关于原型的更新
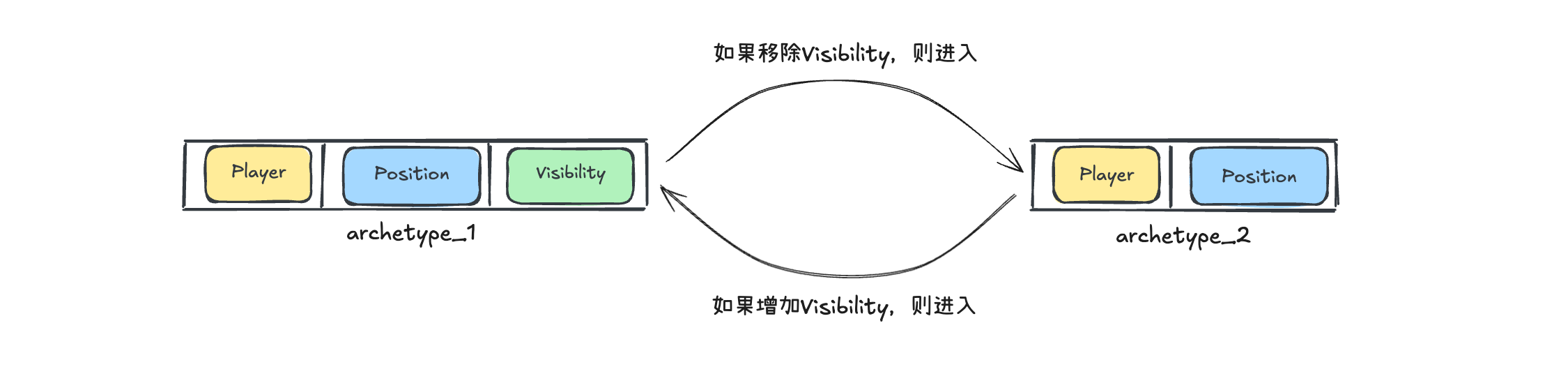
注意,这里说的是原型的更新,而非原型下面的某个组件数据的更新,所谓原型的更新发生在其对应实体内组件的增删。比如,对于某个实体具有一个名为Visibilty的组件来标记一个实体是否能被看到,我们想要隐藏该实体时,只需要将Visibility组件从这个实体中移除即可:

注意,此时该实体id并不会发生变化,只是该实体所包含的组件少了Visibility组件,进而导致该实体所对应的原型发生了变化:

上图中,实体原本属于原型(Enemy, Position, Health, Visibility),移除Visibility组件后,会被迁移到原型(Enemy, Position, Health),这个过程会引发上述原型创建的流程,选择已有的原型或建立新的原型。
当然,读者可能会有这样的疑惑,当我们频繁的添加或移除某个实体内的组件时,原型会被频繁的创建,实体信息会被频繁地移动到各个原型中,这其中的性能如何保证呢。对于这个问题,Bevy采取了操作“图”化的设计,即每一个原型实例在其内部会存储一组信息,该信息包含用来记录这个原型一旦发生相关的改变,能够通向的下一个原型的id。
以上面移除Visibility组件为例,改变前的原型(Enemy, Position, Health, Visibility)我们假设称其为AT1,当我们首次将某个实体的Visibility组件移除时,由于此刻运行时内部没有其他的原型,所以Bevy会创建一个新的原型(Enemy, Position, Health)(我们假设称其为AT2);之后,Bevy会生成这样一条上下文信息:“移除Visibility时,指向AT2”,将其存储到AT1中,这条上下文信息在Bevy内部实现被定义为一条边(Edge)。如此一来,在后续再次出现同样原型的“敌人角色”实体移除Visibility的时候,可以通过AT1中的存储的“移除Visibility时,指向AT2”来快速索引到AT2中。
类似状态机的设计
写在最后
本文是近期阅读Bevy相关的资料和源码时候的一些所想所感,思来想去最终整理并写下了这篇文章,当然这其中可能有些错误或者不准确的地方,还望读者见谅。
关于Bevy中的原型Archetypes的更多相关文章
- 【转】JavaScript中的原型和继承
请在此暂时忘记之前学到的面向对象的一切知识.这里只需要考虑赛车的情况.是的,就是赛车. 最近我正在观看 24 Hours of Le Mans ,这是法国流行的一项赛事.最快的车被称为 Le Mans ...
- jacascript中的原型链以原型
今地铁上看慕课网js课程,又学习到关于原型的一些知识,记录如下.如有偏差欢迎指正: 三张图要连起来看哦~ 图解: 1.创建一个函数foo. 2.运用函数的prototype属性(这个属性就是实例对象的 ...
- 【转载】 C++多继承中重写不同基类中相同原型的虚函数
本篇随笔为转载,原文地址:C++多继承中重写不同基类中相同原型的虚函数. 在C++多继承体系当中,在派生类中可以重写不同基类中的虚函数.下面就是一个例子: class CBaseA { public: ...
- JS中的原型继承机制
转载 http://blog.csdn.net/niuyongjie/article/details/4810835 在学习JS的面向对象过程中,一直对constructor与prototype感到很 ...
- js中的原型、继承的一些想法
最近看到一个别人写的js类库,突然对js中的原型及继承产生了一些想法,之前也看过其中的一些内容,但是总不是很清晰,这几天利用空闲时间,对这块理解了一下,感觉还是有不通之处,思路上没那么条理,仅作为分享 ...
- 理解JavaScript中的原型继承(2)
两年前在我学习JavaScript的时候我就写过两篇关于原型继承的博客: 理解JavaScript中原型继承 JavaScript中的原型继承 这两篇博客讲的都是原型的使用,其中一篇还有我学习时的错误 ...
- 理解javascript中的原型模式
一.为什么要用原型模式. 早期采用工厂模式或构造函数模式的缺点: 1.工厂模式:函数creatPerson根据接受的参数来构建一个包含所有必要信息的person对象,这个函数可以被无数次的调用,工厂 ...
- javaScript中的原型
最近在学习javaScript,学习到js面向对象中的原型时,感悟颇多.若有不对的地方,希望可以指正. js作为一门面向对象的语言,自然也拥有了继承这一概念,但js中没有类的概念,也就没有了类似于ja ...
- (转载)JavaScript中的原型和对象机制
(转载)http://www.cnblogs.com/FlyingCat/archive/2009/09/21/1570656.html 1 对象相关的一些语言特性 1.1 一切皆为对象JavaScr ...
- 基类中定义的虚函数在派生类中重新定义时,其函数原型,包括返回类型、函数名、参数个数、参数类型及参数的先后顺序,都必须与基类中的原型完全相同 but------> 可以返回派生类对象的引用或指针
您查询的关键词是:c++primer习题15.25 以下是该网页在北京时间 2016年07月15日 02:57:08 的快照: 如果打开速度慢,可以尝试快速版:如果想更新或删除快照,可以投诉快照. ...
随机推荐
- LeetCode 第2题:两数相加
LeetCode 第2题:两数相加 题目描述 给你两个 非空 的链表,表示两个非负的整数.它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字. 请你将两个数相加,并以相同形式返 ...
- P10353 [PA2024] Grupa permutacji 题解
神秘!在这些排列生成的置换群 \(G\) 里,若 \(\exists \pi \in G\) 使得 \(\pi_i=k,\pi_j=l\),则所有这些 \((k,l)\) 被同样数量的 \(\pi\i ...
- RocketMQ实战—8.营销系统业务和方案介绍
大纲 1.电商核心交易场景的业务流程 2.电商支付后履约场景的业务流程 3.电商营销场景的业务说明 4.电商促销活动的Push推送 5.会员与推送的数据库表结构 6.营销系统的数据库表结构 7.营销系 ...
- Typecho添加一个当前页面加载完成速度时间
判断当前页面加载是否快速,通常是直接在浏览器中访问网站,看自己的直观感受是否快速.而客观的方法则是计算具体的页面加载时间并显示出来给看. 1.在当前主题的functions.php文件添加下面的代码: ...
- DW001 - 数据仓库理论知识
数据仓库概念 数据仓库基本架构 数据集市概念 数据湖概念 数据仓库概念 数据仓库(Data Warehouse,DW)是一个面向主题的.集成的.非易失的.反映历史变化的.用来支持企业管理决策的数据集合 ...
- Hadoop - 两个Namenode都是standby状态怎么处理
在任意一个standby的NN节点执行 再次访问 ctos01:9870页面
- php框架里面数组合并的方法
php框架里面用call_user_func_array(array($dispatch, $actionName), $param);传参的时候,接收的$actionName方法不能接收数组参数. ...
- mySql跳过行数获取多少行
LIMIT :需要获取多少条记录 OFFSET :跳过前面的多少行记录从后面开始获取 SELECT * FROM USER LIMIT 32 OFFSET 1 只获取12行记录 跳过第一条记录 SEL ...
- 如何使用ISqlSugarClient进行数据访问,并实现了统一的批量依赖注入
仓储层当前有接口 IRepository<T> 抽象类 BaseRepository<T> 业务逻辑层有抽象类 BaseBusiness<M, E> 接口 IBu ...
- Easyexcel(1-注解使用)
版本依赖 <dependency> <groupId>com.alibaba</groupId> <artifactId>easyexcel</a ...