Flume 学习笔记之 Flume NG高可用集群搭建
Flume NG高可用集群搭建:
架构总图:
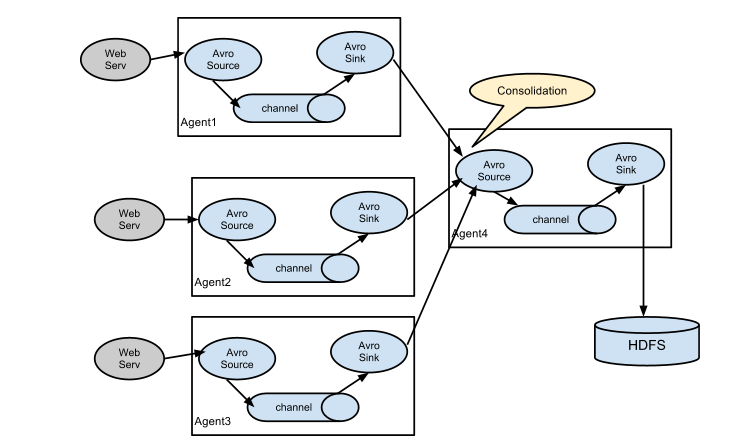
架构分配:
|
角色 |
Host |
端口 |
|
agent1 |
hadoop3 |
52020 |
|
collector1 |
hadoop1 |
52020 |
|
collector2 |
hadoop2 |
52020 |
agent1配置(flume-client.conf):
#agent1 name
agent1.channels = c1
agent1.sources = r1
agent1.sinks = k1 k2
#set gruop
agent1.sinkgroups = g1
#set channel
agent1.channels.c1.type = memory
agent1.channels.c1.capacity = 1000
agent1.channels.c1.transactionCapacity = 100
agent1.sources.r1.channels = c1
agent1.sources.r1.type = exec
agent1.sources.r1.command = tail -F /home/sky/flume/log_exec_tail
agent1.sources.r1.interceptors = i1 i2
agent1.sources.r1.interceptors.i1.type = static
agent1.sources.r1.interceptors.i1.key = Type
agent1.sources.r1.interceptors.i1.value = LOGIN
agent1.sources.r1.interceptors.i2.type = timestamp
# set sink1
agent1.sinks.k1.channel = c1
agent1.sinks.k1.type = avro
agent1.sinks.k1.hostname = hadoop1
agent1.sinks.k1.port = 52020
# set sink2
agent1.sinks.k2.channel = c1
agent1.sinks.k2.type = avro
agent1.sinks.k2.hostname = hadoop2
agent1.sinks.k2.port = 52020
#set sink group
agent1.sinkgroups.g1.sinks = k1 k2
#set failover
agent1.sinkgroups.g1.processor.type = failover
agent1.sinkgroups.g1.processor.priority.k1 = 10
agent1.sinkgroups.g1.processor.priority.k2 = 1
agent1.sinkgroups.g1.processor.maxpenalty = 10000
collector1配置(flume-server.conf):
#set Agent name
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#set channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# other node,nna to nns
a1.sources.r1.type = avro
a1.sources.r1.bind = hadoop1
a1.sources.r1.port = 52020
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
a1.sources.r1.interceptors.i1.key = Collector
a1.sources.r1.interceptors.i1.value = hadoop1
a1.sources.r1.channels = c1
#set sink to hdfs
a1.sinks.k1.type=logger
a1.sinks.k1.channel=c1
collector2配置(flume-server.conf):
#set Agent name
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#set channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# other node,nna to nns
a1.sources.r1.type = avro
a1.sources.r1.bind = hadoop2
a1.sources.r1.port = 52020
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
a1.sources.r1.interceptors.i1.key = Collector
a1.sources.r1.interceptors.i1.value = hadoop2
a1.sources.r1.channels = c1
#set sink to hdfs
a1.sinks.k1.type=logger
a1.sinks.k1.channel=c1
先启动server,在启动client:
flume-ng agent --conf conf --conf-file /usr/local/flume/conf/flume-server.conf --name a1 -Dflume.root.logger=INFO,console
flume-ng agent --conf conf --conf-file /usr/local/flume/conf/flume-client.conf --name agent1 -Dflume.root.logger=INFO,console
测试验证:
hadoop1收到了hadoop3的消息了,哈哈。hadoop2没有收到消息,那是因为hadoop1的priority高。
hadoop3:

hadoop1:

hadoop2:

再次测试Failover:
停掉hadoop1的Flume,再次在hadoop3发送数据。可见hadoop3的Flume报错重连了,并且hadoop2收到了数据。如果再次启动hadoop1的Flume,一切又会恢复到hadoop1接收。
hadoop3:


hadoop2:

这样测试就完毕了。Flume高可用集群就搭建好了!
Flume 学习笔记之 Flume NG高可用集群搭建的更多相关文章
- Flume NG高可用集群搭建详解
.Flume NG简述 Flume NG是一个分布式,高可用,可靠的系统,它能将不同的海量数据收集,移动并存储到一个数据存储系统中.轻量,配置简单,适用于各种日志收集,并支持 Failover和负载均 ...
- SpringCloud全家桶学习之服务注册与发现及Eureka高可用集群搭建(二)
一.Eureka服务注册与发现 (1)Eureka是什么? Eureka是NetFlix的一个子模块,也是核心模块之一.Eureka是一个基于REST的服务,用于定位服务,以实现云端中间层服务发现和故 ...
- Hadoop 3.1.2(HA)+Zookeeper3.4.13+Hbase1.4.9(HA)+Hive2.3.4+Spark2.4.0(HA)高可用集群搭建
目录 目录 1.前言 1.1.什么是 Hadoop? 1.1.1.什么是 YARN? 1.2.什么是 Zookeeper? 1.3.什么是 Hbase? 1.4.什么是 Hive 1.5.什么是 Sp ...
- .Net Core2.1 秒杀项目一步步实现CI/CD(Centos7.2)系列一:k8s高可用集群搭建总结以及部署API到k8s
前言:本系列博客又更新了,是博主研究很长时间,亲自动手实践过后的心得,k8s集群是购买了5台阿里云服务器部署的,这个集群差不多搞了一周时间,关于k8s的知识点,我也是刚入门,这方面的知识建议参考博客园 ...
- 实现CI/CDk8s高可用集群搭建总结以及部署API到k8s
实现CI/CD(Centos7.2)系列二:k8s高可用集群搭建总结以及部署API到k8s 前言:本系列博客又更新了,是博主研究很长时间,亲自动手实践过后的心得,k8s集群是购买了5台阿里云服务器部署 ...
- hadoop高可用集群搭建小结
hadoop高可用集群搭建小结1.Zookeeper集群搭建2.格式化Zookeeper集群 (注:在Zookeeper集群建立hadoop-ha,amenode的元数据)3.开启Journalmno ...
- Spark高可用集群搭建
Spark高可用集群搭建 node1 node2 node3 1.node1修改spark-env.sh,注释掉hadoop(就不用开启Hadoop集群了),添加如下语句 export ...
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- MongoDB高可用集群搭建(主从、分片、路由、安全验证)
目录 一.环境准备 1.部署图 2.模块介绍 3.服务器准备 二.环境变量 1.准备三台集群 2.安装解压 3.配置环境变量 三.集群搭建 1.新建配置目录 2.修改配置文件 3.分发其他节点 4.批 ...
随机推荐
- hdu 5887 Herbs Gathering (dfs+剪枝 or 超大01背包)
题目链接:http://acm.split.hdu.edu.cn/showproblem.php?pid=5887 题解:这题一看像是背包但是显然背包容量太大了所以可以考虑用dfs+剪枝,贪心得到的不 ...
- 面试加分项-HashMap源码中这些常量的设计目的
前言 之前周会技术分享,一位同事讲解了HashMap的源码,涉及到一些常量设计的目的,本文将谈谈这些常量为何这样设计,希望大家有所收获. HashMap默认初始化大小为什么是1 << 4( ...
- 解决问题:SpringMvc中转发的html文件中文是乱码
目录 1.环境说明,以及前言 2.问题描述: 3.失败的方法(这里写失败并不代表在其他情况不管用) 3.1 html网页本身编码不是UTF-8(推荐尝试) 3.2 web.xml中没有设置配置编码方式 ...
- 《即时消息技术剖析与实战》学习笔记5——IM系统如何保证消息的一致性
一.什么是消息一致性 消息一致性指的是消息的时序一致性,即消息收发的一致性.如果不能保证时序一致性,就会造成聊天语义不连贯,引起误会. 对于点对点的聊天场景,时序一致性保证接收方的接收顺序和发送方的发 ...
- c语言文件的基本操作
c语言对文件的操作主要分为:按字符操作,按行操作,按内存块操作 主要的函数: fopen(): FILE * fopen(_In_z_ const char * _Filename, _In_z_ c ...
- Java ArrayList源码分析(有助于理解数据结构)
arraylist源码分析 1.数组介绍 数组是数据结构中很基本的结构,很多编程语言都内置数组,类似于数据结构中的线性表 在java中当创建数组时会在内存中划分出一块连续的内存,然后当有数据进入的时候 ...
- IDEA中运行测试方法
1. 2. 3. 4. 5.
- springboot打包jar包后运行
我们知道,spring boot内嵌tomcat,打包成jar包以后,直接就可以运行. 我们也可以使用启动项里面的mian入口来运行程序. 运行jar包时,我们一般是java -jar xxx.jar ...
- 【LeetCode】Two Sum II - Input array is sorted
[Description] Given an array of integers that is already sorted in ascending order, find two numbers ...
- Java多线程(十三):线程池
线程池类结构 1.Executor是顶级接口,有一个execute方法. 2.ExecutorService接口提供了管理线程的方法. 3.AbstractExecutorService管理普通线程, ...