Spark 系列(八)—— Spark SQL 之 DataFrame 和 Dataset
一、Spark SQL简介
Spark SQL 是 Spark 中的一个子模块,主要用于操作结构化数据。它具有以下特点:
- 能够将 SQL 查询与 Spark 程序无缝混合,允许您使用 SQL 或 DataFrame API 对结构化数据进行查询;
- 支持多种开发语言;
- 支持多达上百种的外部数据源,包括 Hive,Avro,Parquet,ORC,JSON 和 JDBC 等;
- 支持 HiveQL 语法以及 Hive SerDes 和 UDF,允许你访问现有的 Hive 仓库;
- 支持标准的 JDBC 和 ODBC 连接;
- 支持优化器,列式存储和代码生成等特性;
- 支持扩展并能保证容错。

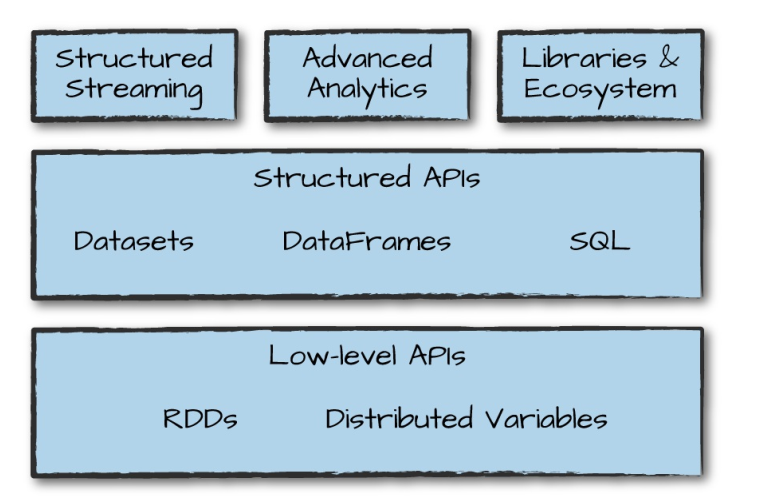
二、DataFrame & DataSet
2.1 DataFrame
为了支持结构化数据的处理,Spark SQL 提供了新的数据结构 DataFrame。DataFrame 是一个由具名列组成的数据集。它在概念上等同于关系数据库中的表或 R/Python 语言中的 data frame。 由于 Spark SQL 支持多种语言的开发,所以每种语言都定义了 DataFrame 的抽象,主要如下:
| 语言 | 主要抽象 |
|---|---|
| Scala | Dataset[T] & DataFrame (Dataset[Row] 的别名) |
| Java | Dataset[T] |
| Python | DataFrame |
| R | DataFrame |
2.2 DataFrame 对比 RDDs
DataFrame 和 RDDs 最主要的区别在于一个面向的是结构化数据,一个面向的是非结构化数据,它们内部的数据结构如下:
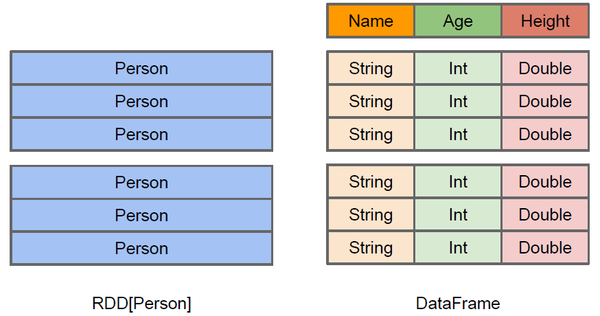
DataFrame 内部的有明确 Scheme 结构,即列名、列字段类型都是已知的,这带来的好处是可以减少数据读取以及更好地优化执行计划,从而保证查询效率。
DataFrame 和 RDDs 应该如何选择?
- 如果你想使用函数式编程而不是 DataFrame API,则使用 RDDs;
- 如果你的数据是非结构化的 (比如流媒体或者字符流),则使用 RDDs,
- 如果你的数据是结构化的 (如 RDBMS 中的数据) 或者半结构化的 (如日志),出于性能上的考虑,应优先使用 DataFrame。
2.3 DataSet
Dataset 也是分布式的数据集合,在 Spark 1.6 版本被引入,它集成了 RDD 和 DataFrame 的优点,具备强类型的特点,同时支持 Lambda 函数,但只能在 Scala 和 Java 语言中使用。在 Spark 2.0 后,为了方便开发者,Spark 将 DataFrame 和 Dataset 的 API 融合到一起,提供了结构化的 API(Structured API),即用户可以通过一套标准的 API 就能完成对两者的操作。
这里注意一下:DataFrame 被标记为 Untyped API,而 DataSet 被标记为 Typed API,后文会对两者做出解释。
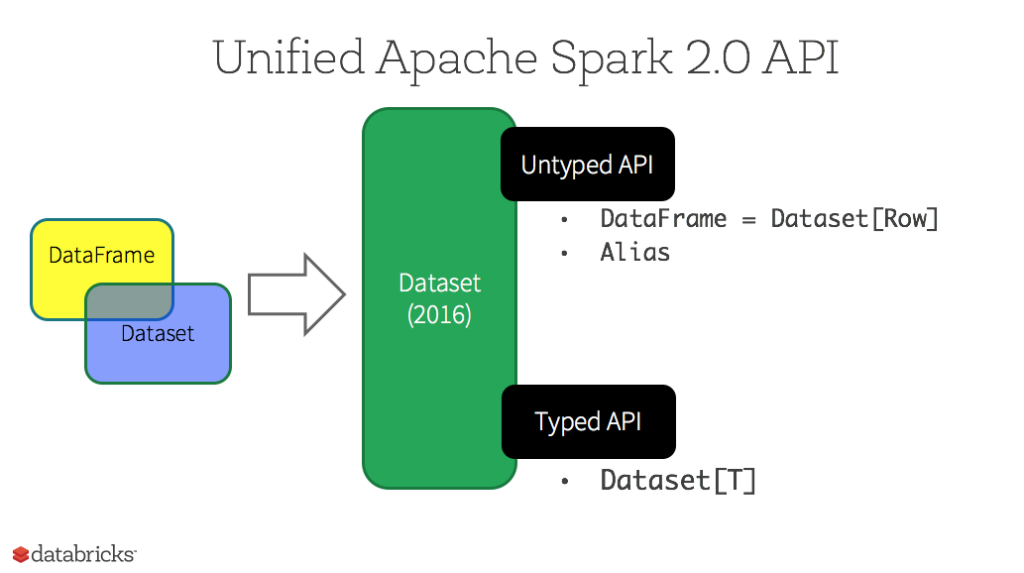
2.4 静态类型与运行时类型安全
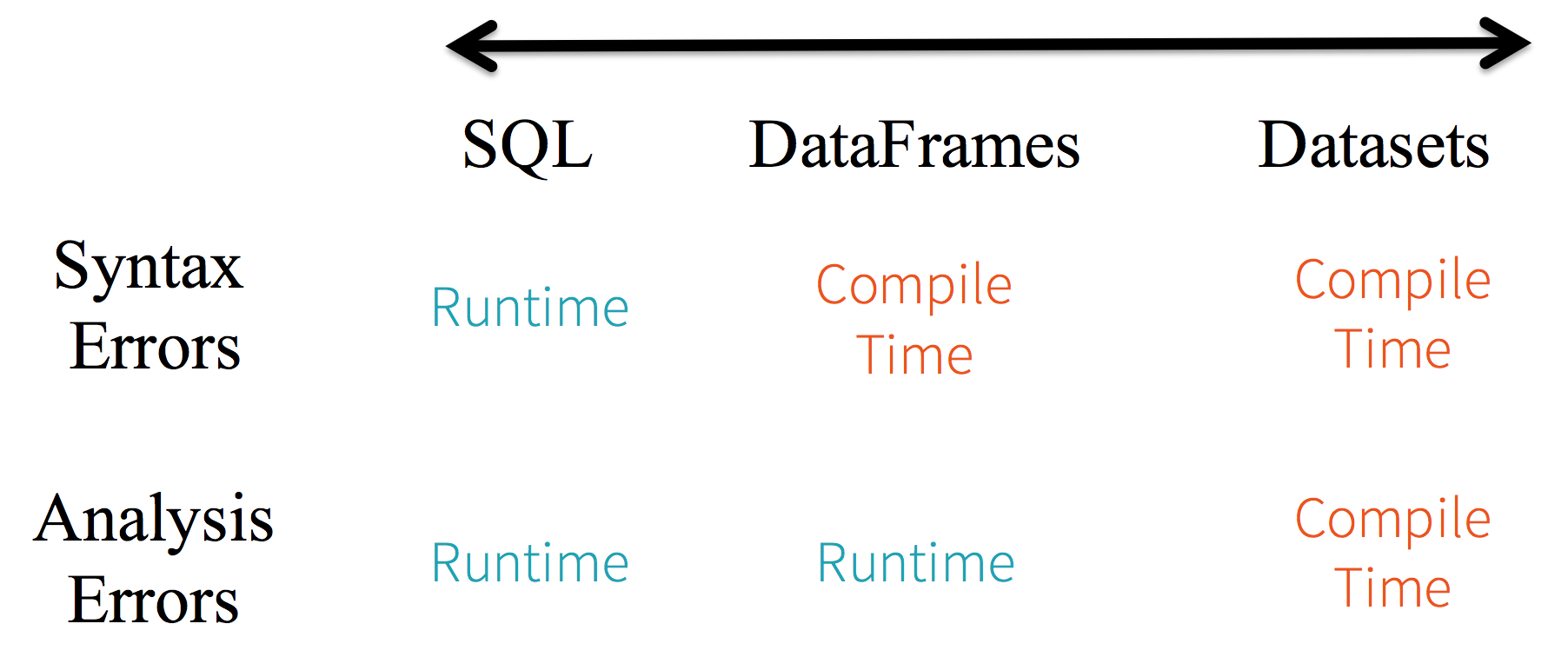
静态类型 (Static-typing) 与运行时类型安全 (runtime type-safety) 主要表现如下:
在实际使用中,如果你用的是 Spark SQL 的查询语句,则直到运行时你才会发现有语法错误,而如果你用的是 DataFrame 和 Dataset,则在编译时就可以发现错误 (这节省了开发时间和整体代价)。DataFrame 和 Dataset 主要区别在于:
在 DataFrame 中,当你调用了 API 之外的函数,编译器就会报错,但如果你使用了一个不存在的字段名字,编译器依然无法发现。而 Dataset 的 API 都是用 Lambda 函数和 JVM 类型对象表示的,所有不匹配的类型参数在编译时就会被发现。
以上这些最终都被解释成关于类型安全图谱,对应开发中的语法和分析错误。在图谱中,Dataset 最严格,但对于开发者来说效率最高。
上面的描述可能并没有那么直观,下面的给出一个 IDEA 中代码编译的示例:
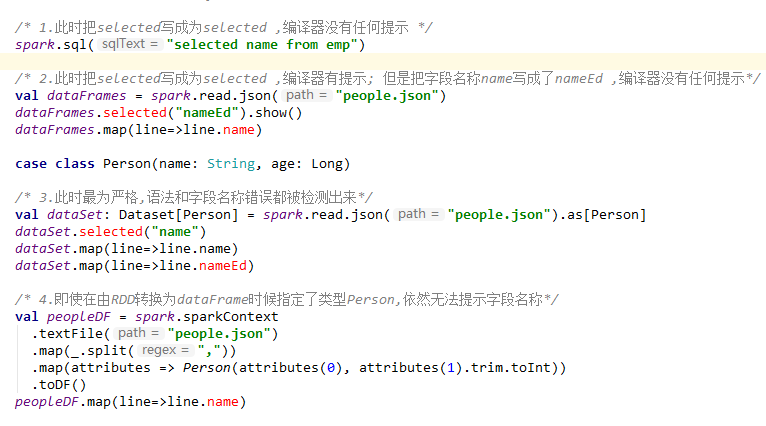
这里一个可能的疑惑是 DataFrame 明明是有确定的 Scheme 结构 (即列名、列字段类型都是已知的),但是为什么还是无法对列名进行推断和错误判断,这是因为 DataFrame 是 Untyped 的。
2.5 Untyped & Typed
在上面我们介绍过 DataFrame API 被标记为 Untyped API,而 DataSet API 被标记为 Typed API。DataFrame 的 Untyped 是相对于语言或 API 层面而言,它确实有明确的 Scheme 结构,即列名,列类型都是确定的,但这些信息完全由 Spark 来维护,Spark 只会在运行时检查这些类型和指定类型是否一致。这也就是为什么在 Spark 2.0 之后,官方推荐把 DataFrame 看做是 DatSet[Row],Row 是 Spark 中定义的一个 trait,其子类中封装了列字段的信息。
相对而言,DataSet 是 Typed 的,即强类型。如下面代码,DataSet 的类型由 Case Class(Scala) 或者 Java Bean(Java) 来明确指定的,在这里即每一行数据代表一个 Person,这些信息由 JVM 来保证正确性,所以字段名错误和类型错误在编译的时候就会被 IDE 所发现。
case class Person(name: String, age: Long)
val dataSet: Dataset[Person] = spark.read.json("people.json").as[Person]三、DataFrame & DataSet & RDDs 总结
这里对三者做一下简单的总结:
- RDDs 适合非结构化数据的处理,而 DataFrame & DataSet 更适合结构化数据和半结构化的处理;
- DataFrame & DataSet 可以通过统一的 Structured API 进行访问,而 RDDs 则更适合函数式编程的场景;
- 相比于 DataFrame 而言,DataSet 是强类型的 (Typed),有着更为严格的静态类型检查;
- DataSets、DataFrames、SQL 的底层都依赖了 RDDs API,并对外提供结构化的访问接口。
四、Spark SQL的运行原理
DataFrame、DataSet 和 Spark SQL 的实际执行流程都是相同的:
- 进行 DataFrame/Dataset/SQL 编程;
- 如果是有效的代码,即代码没有编译错误,Spark 会将其转换为一个逻辑计划;
- Spark 将此逻辑计划转换为物理计划,同时进行代码优化;
- Spark 然后在集群上执行这个物理计划 (基于 RDD 操作) 。
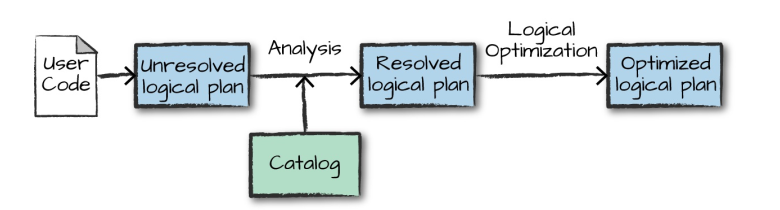
4.1 逻辑计划(Logical Plan)
执行的第一个阶段是将用户代码转换成一个逻辑计划。它首先将用户代码转换成 unresolved logical plan(未解决的逻辑计划),之所以这个计划是未解决的,是因为尽管您的代码在语法上是正确的,但是它引用的表或列可能不存在。 Spark 使用 analyzer(分析器) 基于 catalog(存储的所有表和 DataFrames 的信息) 进行解析。解析失败则拒绝执行,解析成功则将结果传给 Catalyst 优化器 (Catalyst Optimizer),优化器是一组规则的集合,用于优化逻辑计划,通过谓词下推等方式进行优化,最终输出优化后的逻辑执行计划。
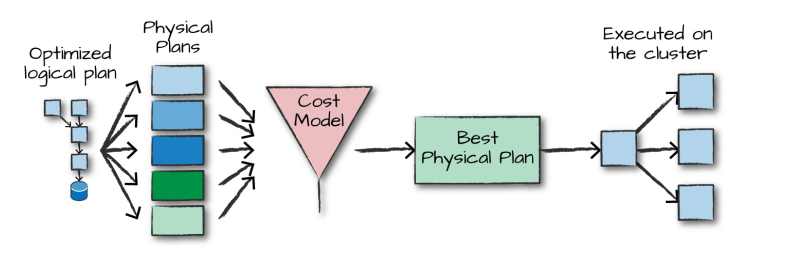
4.2 物理计划(Physical Plan)
得到优化后的逻辑计划后,Spark 就开始了物理计划过程。 它通过生成不同的物理执行策略,并通过成本模型来比较它们,从而选择一个最优的物理计划在集群上面执行的。物理规划的输出结果是一系列的 RDDs 和转换关系 (transformations)。
4.3 执行
在选择一个物理计划后,Spark 运行其 RDDs 代码,并在运行时执行进一步的优化,生成本地 Java 字节码,最后将运行结果返回给用户。
参考资料
- Matei Zaharia, Bill Chambers . Spark: The Definitive Guide[M] . 2018-02
- Spark SQL, DataFrames and Datasets Guide
- 且谈 Apache Spark 的 API 三剑客:RDD、DataFrame 和 Dataset(译文)
- A Tale of Three Apache Spark APIs: RDDs vs DataFrames and Datasets(原文)
更多大数据系列文章可以参见 GitHub 开源项目: 大数据入门指南
Spark 系列(八)—— Spark SQL 之 DataFrame 和 Dataset的更多相关文章
- spark结构化数据处理:Spark SQL、DataFrame和Dataset
本文讲解Spark的结构化数据处理,主要包括:Spark SQL.DataFrame.Dataset以及Spark SQL服务等相关内容.本文主要讲解Spark 1.6.x的结构化数据处理相关东东,但 ...
- Spark学习之路(八)—— Spark SQL 之 DataFrame和Dataset
一.Spark SQL简介 Spark SQL是Spark中的一个子模块,主要用于操作结构化数据.它具有以下特点: 能够将SQL查询与Spark程序无缝混合,允许您使用SQL或DataFrame AP ...
- Spark SQL、DataFrame和Dataset——转载
转载自: Spark SQL.DataFrame和Datase
- Spark系列(八)Worker工作原理
工作原理图 源代码分析 包名:org.apache.spark.deploy.worker 启动driver入口点:registerWithMaster方法中的case LaunchDriver ...
- Spark系列—01 Spark集群的安装
一.概述 关于Spark是什么.为什么学习Spark等等,在这就不说了,直接看这个:http://spark.apache.org, 我就直接说一下Spark的一些优势: 1.快 与Hadoop的Ma ...
- Spark系列—02 Spark程序牛刀小试
一.执行第一个Spark程序 1.执行程序 我们执行一下Spark自带的一个例子,利用蒙特·卡罗算法求PI: 启动Spark集群后,可以在集群的任何一台机器上执行一下命令: /home/spark/s ...
- Apache Spark 2.0三种API的传说:RDD、DataFrame和Dataset
Apache Spark吸引广大社区开发者的一个重要原因是:Apache Spark提供极其简单.易用的APIs,支持跨多种语言(比如:Scala.Java.Python和R)来操作大数据. 本文主要 ...
- Spark 系列(九)—— Spark SQL 之 Structured API
一.创建DataFrame和Dataset 1.1 创建DataFrame Spark 中所有功能的入口点是 SparkSession,可以使用 SparkSession.builder() 创建.创 ...
- Spark SQL 之 DataFrame
Spark SQL 之 DataFrame 转载请注明出处:http://www.cnblogs.com/BYRans/ 概述(Overview) Spark SQL是Spark的一个组件,用于结构化 ...
随机推荐
- iOS组件化开发一pod库包含MRC的文件处理(五)
在做项目的过程中,建立了一个私有pod库,在这个库中存在mrc类文件这个时候如果在使用了arc的工程中引用这个pod的工程中手动设置当然也可以就是费时费力.现在我们来看看如何在私有库配置文件里配置自动 ...
- scrapy基础知识之scrapy自动下载图片pipelines
需要在settings.py配置: ITEM_PIPELINES = { 'scrapy.pipelines.images.ImagesPipeline': 1, }import os IMAGES_ ...
- 关系型数据库MySql简介
什么是关系型数据库? 数据库就是用来存储数据的仓库,是一种特殊的文件. 根据存储的数据不同,划分为关系型数据库和非关系型数据库. 关系型数据库就是指 建立在关系模型基础上的数据库,通俗来讲这种数据库就 ...
- Excel中PMT函数的Java实现
public class PMT { /** * * 计算月供 * * @param rate * 年利率 年利率除以12就是月利率 * @param nper * 贷款期数,单位月 该项贷款的付款总 ...
- Unix及Linux编辑器vi/vim基本使用方法
- python接口自动化(三十三)-python自动发邮件总结及实例说明番外篇——下(详解)
简介 发邮件前我们需要了解的是邮件是怎么一个形式去发送到对方手上的,通俗点来说就是你写好一封信,然后装进信封,写上地址,贴上邮票,然后就近找个邮局,把信仍进去,其他的就不关心了,只是关心时间,而电子邮 ...
- 三个标签完成springboot定时任务配置
1. 问题描述 Java项目定时任务是必备模块,月高风黑夜跑个批处理,记录或者统计一些系统信息. 2. 解决方案: 结合springboot,只需三个标签就能完成定时任务配置. 2.1 标签1 用在s ...
- NOIP2015斗地主题解 7.30考试
问题 B: NOIP2015 斗地主 时间限制: 3 Sec 内存限制: 1024 MB 题目描述 牛牛最近迷上了一种叫斗地主的扑克游戏.斗地主是一种使用黑桃.红心.梅花.方片的A到K加上大小王的共 ...
- ~~函数基础(二):返回值&作用域~~
进击のpython 函数的返回值和作用域 上文我们讲到了函数的基础--参数的相关问题 举的例子也都是带有print的函数定义 但是有个问题就出现了:我不想打印这个函数处理后的参数 我想拿到这个参数然后 ...
- python的@修饰符
‘@’引用已有的函数,对下面的函数进行修饰.引用函数必须放在修饰函数的上面,引用函数的返回值,返回给被修饰的函数 一个简单的栗子: def funA(fn): print('A') # 输出A fn( ...