NLP(三) 预处理
原文链接:http://www.one2know.cn/nlp3/
- 分词
from nltk.tokenize import LineTokenizer,SpaceTokenizer,TweetTokenizer
from nltk import word_tokenize
# 根据行分词,将每行作为一个元素放到list中
lTokenizer = LineTokenizer()
print('Line tokenizer output :',lTokenizer.tokenize('hello hello\npython\nworld'))
# 根据空格分词
rawText = 'hello python,world'
sTokenizer = SpaceTokenizer()
print('Space tokenizer output :',sTokenizer.tokenize(rawText))
# word_tokenize分词
print('Word tokenizer output :',word_tokenize(rawText))
# 能使特殊符号不被分开
tTokenizer = TweetTokenizer()
print('Tweet tokenizer output :',tTokenizer.tokenize('This is a cooool #dummysmiley: :-) :-p <3'))
输出:
Line tokenizer output : ['hello hello', 'python', 'world']
Space tokenizer output : ['hello', 'python,world']
Word tokenizer output : ['hello', 'python', ',', 'world']
Tweet tokenizer output : ['This', 'is', 'a', 'cooool', '#dummysmiley', ':', ':-)', ':-p', '<3']
- 词干提取
去除词的后缀,输出词干,如wanted=>want
from nltk import PorterStemmer,LancasterStemmer,word_tokenize
# 创建raw并将raw分词
raw = 'he wants to be loved by others'
tokens = word_tokenize(raw)
print(tokens)
# 输出词干
porter = PorterStemmer()
pStems = [porter.stem(t) for t in tokens]
print(pStems)
# 这种方法去除的多,易出错
lancaster = LancasterStemmer()
lTems = [lancaster.stem(t) for t in tokens]
print(lTems)
输出:
['he', 'wants', 'to', 'be', 'loved', 'by', 'others']
['he', 'want', 'to', 'be', 'love', 'by', 'other']
['he', 'want', 'to', 'be', 'lov', 'by', 'oth']
- 词形还原
词干提取只是去除后缀,词形还原是对应字典匹配还原
from nltk import word_tokenize,PorterStemmer,WordNetLemmatizer
raw = 'Tom flied kites last week in Beijing'
tokens = word_tokenize(raw)
# 去除后缀
porter = PorterStemmer()
stems = [porter.stem(t) for t in tokens]
print(stems)
# 还原器:字典找到才还原,特殊大写词不还原
lemmatizer = WordNetLemmatizer()
lemmas = [lemmatizer.lemmatize(t) for t in tokens]
print(lemmas)
输出:
['tom', 'fli', 'kite', 'last', 'week', 'in', 'beij']
['Tom', 'flied', 'kite', 'last', 'week', 'in', 'Beijing']
- 停用词
古登堡语料库:18个未分类的纯文本
import nltk
from nltk.corpus import gutenberg
# nltk.download('gutenberg')
# nltk.download('stopwords')
print(gutenberg.fileids())
# print(stopwords)
# 获得bible-kjv.txt的所有单词,并过滤掉长度<3的单词
gb_words = gutenberg.words('bible-kjv.txt')
words_filtered = [e for e in gb_words if len(e) >= 3]
# 加载英文的停用词,并用它过滤
stopwords = nltk.corpus.stopwords.words('english')
words = [w for w in words_filtered if w.lower() not in stopwords]
# 处理的词表和未做处理的词表 词频的比较
fdistPlain = nltk.FreqDist(words)
fdist = nltk.FreqDist(gb_words)
# 观察他们的频率分布特征
print('Following are the most common 10 words in the bag')
print(fdistPlain.most_common(10))
print('Following are the most common 10 words in the bag minus the stopwords')
print(fdist.most_common(10))
输出:
['austen-emma.txt', 'austen-persuasion.txt', 'austen-sense.txt', 'bible-kjv.txt', 'blake-poems.txt', 'bryant-stories.txt', 'burgess-busterbrown.txt', 'carroll-alice.txt', 'chesterton-ball.txt', 'chesterton-brown.txt', 'chesterton-thursday.txt', 'edgeworth-parents.txt', 'melville-moby_dick.txt', 'milton-paradise.txt', 'shakespeare-caesar.txt', 'shakespeare-hamlet.txt', 'shakespeare-macbeth.txt', 'whitman-leaves.txt']
Following are the most common 10 words in the bag
[('shall', 9760), ('unto', 8940), ('LORD', 6651), ('thou', 4890), ('thy', 4450), ('God', 4115), ('said', 3995), ('thee', 3827), ('upon', 2730), ('man', 2721)]
Following are the most common 10 words in the bag minus the stopwords
[(',', 70509), ('the', 62103), (':', 43766), ('and', 38847), ('of', 34480), ('.', 26160), ('to', 13396), ('And', 12846), ('that', 12576), ('in', 12331)]
- 编辑距离 Levenshtein_distance
从一个字符串变到另外一个字符串所需要最小的步骤,衡量两个字符串的相似度
动态规划算法:创建一个二维表,若相等,则=左上;否则=min(左,上,左上)+1
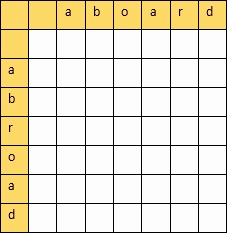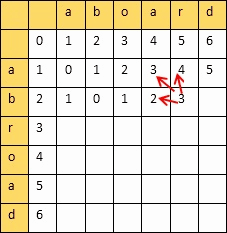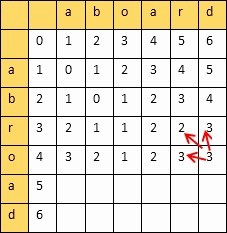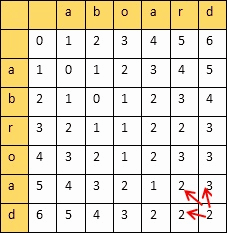
填完表计算编辑距离和相似度:
设两个字符串的长度分别是m,n,填的二维表为A
则
编辑距离 = A[m][n]
相似度 = 1 - 编辑距离/max(m,n)
代码实现:
from nltk.metrics.distance import edit_distance
def my_edit_distance(str1,str2):
m = len(str1) + 1
n = len(str2) + 1
# 创建二维表,初始化第一行和第一列
table = {}
for i in range(m): table[i,0] = i
for j in range(n): table[0,j] = j
# 填表
for i in range(1,m):
for j in range(1,n):
cost = 0 if str1[i-1] == str2[j-1] else 1
table[i,j] = min(table[i,j-1]+1,table[i-1,j]+1,table[i-1,j-1]+cost)
return table[i,j],1-table[i,j]/max(i,j)
print('My Algorithm :',my_edit_distance('aboard','abroad'))
print('NLTK Algorithm :',edit_distance('aboard','abroad'))
输出:
My Algorithm : (2, 0.6666666666666667)
NLTK Algorithm : 2
- 提取两个文本共有词汇
story1 = open('story1.txt','r',encoding='utf-8').read()
story2 = open('story2.txt','r',encoding='utf-8').read()
# 删除特殊字符,所有字符串小写
story1 = story1.replace(',',' ').replace('\n',' ').replace('.',' ').replace('"',' ')\
.replace("'",' ').replace('!',' ').replace('?',' ').casefold()
story2 = story2.replace(',',' ').replace('\n',' ').replace('.',' ').replace('"',' ')\
.replace("'",' ').replace('!',' ').replace('?',' ').casefold()
# 分词
story1_words = story1.split(' ')
story2_words = story2.split(' ')
# 去掉重复词
story1_vocab = set(story1_words)
story2_vocab = set(story2_words)
# 找共同词
common_vocab = story1_vocab & story2_vocab
print('Common Vocabulary :',common_vocab)
输出:
Common Vocabulary : {'', 'got', 'for', 'but', 'out', 'you', 'caught', 'so', 'very', 'away', 'could', 'to', 'not', 'it', 'a', 'they', 'was', 'of', 'and', 'said', 'ran', 'the', 'saw', 'have'}
NLP(三) 预处理的更多相关文章
- NLP 文本预处理
1.不同类别文本量统计,类别不平衡差异 2.文本长度统计 3.文本处理,比如文本语料中简体与繁体共存,这会加大模型的学习难度.因此,他们对数据进行繁体转简体的处理. 同时,过滤掉了对分类没有任何作用的 ...
- DeepLearning (三) 预处理:主成分分析与白化
[原创]Liu_LongPo 转载请注明出处 [CSDN]http://blog.csdn.net/llp1992 PCA算法前面在前面的博客中已经有介绍,这里简单在描述一下,更详细的PCA算法请参考 ...
- 百度NLP三面
首先,面试官根据项目经验进行提问,主要是自然语言处理相关的问题:然后写代码题,字符串处理和数字运算居多:再者是一些语言基础知识,百度用的linux平台,C++和python居多.下面列出我面试中的一些 ...
- 史上最详尽的NLP预处理模型汇总
文章发布于公号[数智物语] (ID:decision_engine),关注公号不错过每一篇干货. 转自 | 磐创AI(公众号ID:xunixs) 作者 | AI小昕 编者按:近年来,自然语言处理(NL ...
- 浅谈NLP 文本分类/情感分析 任务中的文本预处理工作
目录 浅谈NLP 文本分类/情感分析 任务中的文本预处理工作 前言 NLP相关的文本预处理 浅谈NLP 文本分类/情感分析 任务中的文本预处理工作 前言 之所以心血来潮想写这篇博客,是因为最近在关注N ...
- C预编译, 预处理, C/C++头文件, 编译控制,
在所有的预处理指令中,#Pragma 指令可能是最复杂的了,它的作用是设定编译器的状态或者是指示编译器完成一些特定的动作.#pragma指令对每个编译器给出了一个方法,在保持与C和C++语言完全兼容的 ...
- C中的预编译宏定义
可以用宏判断是否为ARC环境 #if _has_feature(objc_arc) #else //MRC #endif C中的预编译宏定义 -- 作者: infobillows 来源:网络 在将一 ...
- 一些基础的.net用法
一.using 用法 using 别名设置 using 别名 = System.web 当两个不同的namespace里有同名的class时.可以用 using aclass = namespace1 ...
- 学习笔记之自然语言处理(Natural Language Processing)
自然语言处理 - 维基百科,自由的百科全书 https://zh.wikipedia.org/wiki/%E8%87%AA%E7%84%B6%E8%AF%AD%E8%A8%80%E5%A4%84%E7 ...
随机推荐
- NPM - 检查并更新项目依赖的版本
原文地址:https://acme.top/nodejs-npm-check-updates 前言 经常会遇到 package.json 中的库有更新,但是太多一个一个的来很费事,幸好有个工具 npm ...
- iOS 注释
1) 参数的注释: UIButton *btnSend;/**< 发送按钮 */ 效果: 2) 方法的注释: type1(无参数): /** table 相关设置 */ -(void)confi ...
- 【转载】C/C++中long long与__int64的区别
在C99标准(详情请猛击:C语言的发展及其版本)中,增加了对64位长整型数据的支持,它的类型就是 long long,占用8个字节. 由于C99标准发布较晚,一些较老的C/C++编译器不支持,新编译器 ...
- python中的赋值操作与C语言中的赋值操作中的巨大差别
首先让我们来看一个简单的C程序: a = ; b = a; b = ; printf("a = %d, b = %d\n", a, b); 相信只要学过C语言, 不用运行程序便能知 ...
- 洛谷P2630 题解
我先讲一下我的思路 将A,B,C,D四种操作用函数储存起来: 枚举所有可能出现的情况:A,B,C,D,AA,AB,AC,AD,BB,BC,BD,CC,CD,DD,ABC,ABD,ACD,BCD,ABC ...
- 第四章 文件的基本管理和XFS文件系统备份恢复 随堂笔记
第四章 文件的基本管理和XFS文件系统备份恢复 本节所讲内容: 4.1 Linux系统目录结构和相对/绝对路径. 4.2 创建/复制/删除文件,rm -rf / 意外事故 4.3 查看文件内容的命令 ...
- pipreqs 生成requirements.txt文件时编码错误问题
1,首先安装pipreqs --> pip install pipreqs 2.生成相应项目的路径 --> pipreqs e:\a\b 在此时可能会遇见 UnicodeDecodeE ...
- IBM实习工作(一)
2019.1.21 今天的任务是完成会计是否在岗配置表格增加操作记录,任务描述:1. [会计是否在岗配置] 查询结果界面: 修改人编码/修改人/修改时间 字段:2. 字段取值为[会计是否在 ...
- Vue中拆分视图层代码的5点建议
目录 一.框架的定位 二. Vue开发中的script拆分优化 1.组件划分 2.剥离业务逻辑代码 3. 剥离数据转换代码 4. 善用computed和filters处理数据展示 5. 使用direc ...
- (十九)c#Winform自定义控件-停靠窗体
前提 入行已经7,8年了,一直想做一套漂亮点的自定义控件,于是就有了本系列文章. 开源地址:https://gitee.com/kwwwvagaa/net_winform_custom_control ...