爬虫之突破xm-sign校验反爬
喜马拉雅
网页分析
- 打开我们要爬取的音乐专辑https://www.ximalaya.com/ertong/424529/
- F12打开开发者工具
- 点击XHR 随便点击一首歌曲会看到存储所有歌曲的地址【json格式】
- 正常情况下我们直接用requests请求上面的地址就可以直接获取歌曲的所有信息
- 我们拿着上面获取的地址向浏览器发起请求,发现没有返回任何信息
- 我们查看请求头中的信息发现有一个xm-sign参数,值为加密后的字符串,就是这个参数使我们获取不到数据
- 31a0dbb5916dfe85d62d8fa5988efc43(36)1563537528652(26)1563537531252
- 后面的时间戳为服务器时间戳和系统当前时间戳,计算过期时间
- 我们分析出xm-sign参数的加密规则,每次请求都在headers加上我们自己生成的xm-sign参数即可
加密方式:
ximalaya-时间戳(sha1加密) + (100以内随机生成一个数) + 服务器时间 + (100以内随机生成一个数) + 系统当前时间 校验方式:
ximalaya-时间戳(sha1加密) + 服务器时间
获取地址

请求地址

告诉我们没有标志,此时感觉我们在请求时少了点参数,去查看请求头
查看请求头

后端逻辑代码
- 下载安装node.js https://nodejs.org/en/download/ 安装方式:https://blog.csdn.net/cai454692590/article/details/86093297
- 获取服务器时间戳
- 调用js代码中的函数生成xm-sign参数
- 在headrs中加上生成的xm-sign参数像浏览器发起请求
- 获取数据进行持久化
js代码需要改的
目标地址:
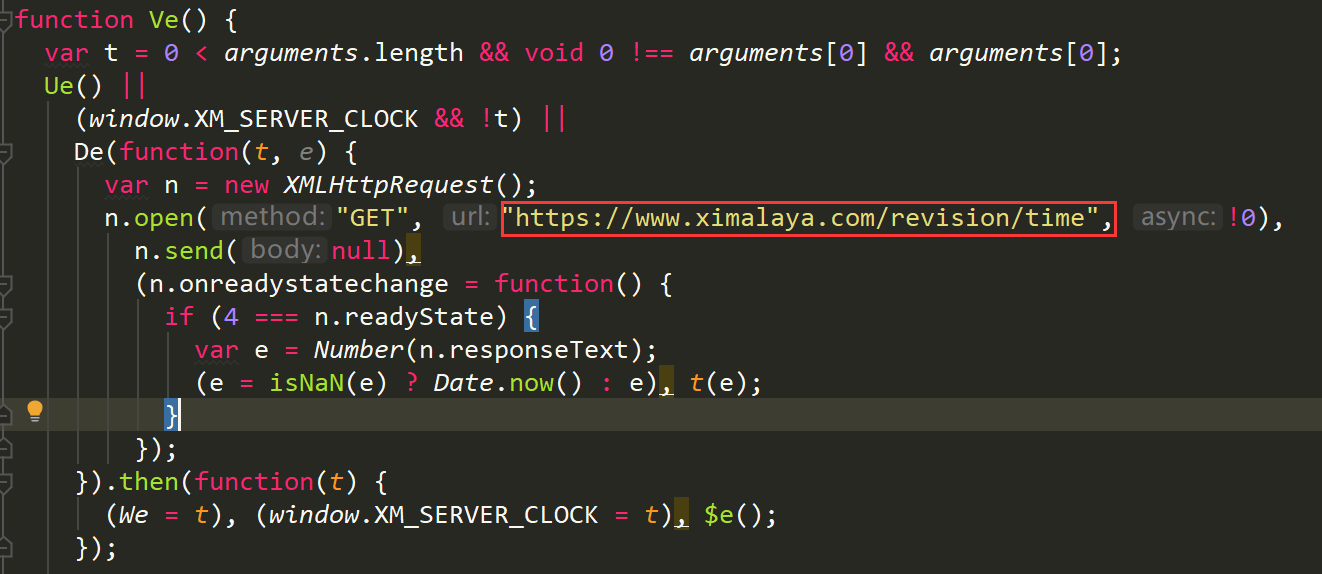
加密方式:

代码实现
安装pyexecjs模块
pip install pyexecjs
# -*- coding: utf-8 -*-
# @Time : 2019/7/19 19:05
import requests
import os
import re
from bs4 import BeautifulSoup
import lxml
import json
import execjs # 操作js代码的库 headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36',
'Accept': 'text/html,application/xhtml+ xml,application/xml;q = 0.9,image/webp,image/apng,*/*;q=0.8, application/signe-exchange;v = b3',
'Host': 'www.ximalaya.com'
} '''爬取喜马拉雅服务器系统时间戳,用于生成xm-sign'''
def getxmtime():
url="https://www.ximalaya.com/revision/time"
response = requests.get(url, headers=headers)
html = response.text
return html '''利用xmSign.js生成xm-sign'''
def exec_js():
#获取喜马拉雅系统时间戳
time = getxmtime() #读取同一路径下的js文件
with open('xmSign.js',"r",encoding='utf-8') as f:
js = f.read() # 通过compile命令转成一个js对象
docjs = execjs.compile(js)
# 调用js的function生成sign
res = docjs.call('python',time)
return res """获取专辑一共有多少页"""
def getPage():
url = "https://www.ximalaya.com/ertong/424529/"
html = requests.get(url,headers=headers).text
# 创建BeautifulSoup对象
suop = BeautifulSoup(html,'lxml') # 实例化对象,使用lxml进行解析
# 根据属性获取 最大页码
max_page = suop.find("input",placeholder="请输入页码").attrs["max"]
return max_page response_list = []
"""请求歌曲源地址"""
def gethtml():
# 调用exec_js函数生成xm-sign
xm_sign = exec_js()
# 将生成的xm-sign添加到请求投中
headers["xm-sign"] = xm_sign
max_page = getPage()
for page in range(1,int(max_page)+1):
url = "https://www.ximalaya.com/revision/play/album?albumId=424529&pageNum={}&sort=1&pageSize=30".format(page)
# 下载
response= requests.get(url,headers=headers).text
response = json.loads(response)
response_list.append(response) """数据持久化"""
def write_data():
# 请求歌曲地址拿到响应数据json
gethtml()
for res in response_list:
data_list = res["data"]["tracksAudioPlay"]
for data in data_list:
trackName = data["trackName"] # 歌名
trackCoverPath = data["trackCoverPath"] # 封面地址
music_path = data["src"] # url
print(trackName,trackCoverPath,music_path)
write_data()
下载音频
爬虫之突破xm-sign校验反爬的更多相关文章
- python爬虫的一个常见简单js反爬
python爬虫的一个常见简单js反爬 我们在写爬虫是遇到最多的应该就是js反爬了,今天分享一个比较常见的js反爬,这个我已经在多个网站上见到过了. 我把js反爬分为参数由js加密生成和js生成coo ...
- Python爬虫入门教程 63-100 Python字体反爬之一,没办法,这个必须写,反爬第3篇
背景交代 在反爬圈子的一个大类,涉及的网站其实蛮多的,目前比较常被爬虫coder欺负的网站,猫眼影视,汽车之家,大众点评,58同城,天眼查......还是蛮多的,技术高手千千万,总有五花八门的反爬技术 ...
- 《C# 爬虫 破境之道》:第二境 爬虫应用 — 第六节:反爬策略研究
之前的章节也略有提及反爬策略,本节,我们就来系统的对反爬.反反爬的种种,做一个了结. 从防盗链说起: 自从论坛兴起的时候,网上就有很多人会在论坛里发布一些很棒的文章,与当下流行的“点赞”“分享”一样, ...
- python 爬虫 汽车之家车辆参数反爬
水平有限,仅供参考. 如图所示,汽车之家的车辆详情里的数据做了反爬对策,数据被CSS伪类替换. 观察 Sources 发现数据就在当前页面. 发现若干条进行CSS替换的js 继续深入此JS 知道了数据 ...
- 我去!爬虫遇到JS逆向AES加密反爬,哭了
今天准备爬取网页时,遇到『JS逆向AES加密』反爬.比如这样的: 在发送请求获取数据时,需要用到参数params和encSecKey,但是这两个参数经过JS逆向AES加密而来. 既然遇到了这个情况,那 ...
- python爬虫--爬虫与反爬
爬虫与反爬 爬虫:自动获取网站数据的程序,关键是批量的获取. 反爬虫:使用技术手段防止爬虫程序的方法 误伤:反爬技术将普通用户识别为爬虫,从而限制其访问,如果误伤过高,反爬效果再好也不能使用(例如封i ...
- 简单爬虫,突破IP访问限制和复杂验证码,小总结
简单爬虫,突破复杂验证码和IP访问限制 文章地址:http://www.cnblogs.com/likeli/p/4730709.html 好吧,看题目就知道我是要写一个爬虫,这个爬虫的目标网站有 ...
- 常见的反爬措施:UA反爬和Cookie反爬
摘要:为了屏蔽这些垃圾流量,或者为了降低自己服务器压力,避免被爬虫程序影响到正常人类的使用,开发者会研究各种各样的手段,去反爬虫. 本文分享自华为云社区<Python爬虫反爬,你应该从这篇博客开 ...
- 关于使用scrapy框架编写爬虫以及Ajax动态加载问题、反爬问题解决方案
Python爬虫总结 总的来说,Python爬虫所做的事情分为两个部分,1:将网页的内容全部抓取下来,2:对抓取到的内容和进行解析,得到我们需要的信息. 目前公认比较好用的爬虫框架为Scrapy,而且 ...
随机推荐
- 内存可用性判断 IsBadCodePtr IsBadReadPtr 等等
程序异常崩溃,多数是有内存访问异常引起.为定位崩溃位置通常考虑加强内存访问控制,如此有必要进行内存可用性判断,从<Windows核心编程>中看到内存指针的可用性判断方法,感觉还不错,此处记 ...
- SQL Server 2008收缩日志文件--dbcc shrinkfile参数说明
原文:SQL Server 2008收缩日志文件--dbcc shrinkfile参数说明 DBCC SHRINKFILE 收缩相关数据库的指定数据文件或日志文件大小. 语法 DBCC SHRINKF ...
- 微信小程序把玩(十八)picker组件
原文:微信小程序把玩(十八)picker组件 picker选择器分为三种,普通选择器,时间选择器, 日期选择器 用mode属性区分,默认是普通选择器.测试时时间和日期点击无反应不知道是BUG还是啥!没 ...
- linux清除日志文件
#!/bin/bash # 清除log文件 LOG_DIR=/var/log ROOT_UID= # $UID为0的时候,用户才具有root用户的权限 LINES= # 默认的保存行数 E_XCD= ...
- 读取注册表获取Windows系统XP/7/8/10类型(使用wcscmp比较wchar[]内容)
很多方案是采用GetVersion.GetVersionEx这两个API来查询操作系统的版本号来判断当前的操作系统是Windows系列中的哪个,在Win10没有出现前,这种方法是行的通的,但是Win1 ...
- Windows开机自启动位置
HKCU refers to HKEY_CURRENT_USERHKLM refers to HKEY_LOCAL_MACHINE HKCU\Software\Microsoft\Windows\Cu ...
- C++实现半透明按钮控件(PNG,GDI+)
http://blog.csdn.net/witch_soya/article/details/6889904
- java.lang.ClassNotFoundException: org.hibernate.ejb.HibernatePersistence 解决方法
编译遇到错误,如下: May 11, 2017 1:49:42 PM org.springframework.web.context.ContextLoader initWebApplicationC ...
- 3016C语言_函数
第六章 函数 6.1 函数概述 定义 函数:是具有一定功能的一个程序块:是C语言的基本组成单位. 在前面各章的例子及读者自己编写的C语言程序中都用到了以“main“开头的主函数,并且在程序中频繁地调用 ...
- Fabric1.4源码解析: 链码容器启动过程
想写点东西记录一下最近看的一些Fabric源码,本文使用的是fabric1.4的版本,所以对于其他版本的fabric,内容可能会有所不同. 本文想针对Fabric中链码容器的启动过程进行源码的解析.这 ...