0 MapReduce实现Reduce Side Join操作
一.准备两张表以及对应的数据
(1)m_ys_lab_jointest_a(以下简称表A)
建表语句:
create table if not exists m_ys_lab_jointest_a (
id bigint,
name string
)
row format delimited
fields terminated by ''
lines terminated by ''
stored as textfile;
id name |
create table if not exists m_ys_lab_jointest_b (
id bigint,
statyear bigint,
num bigint
)
row format delimited
fields terminated by ''
lines terminated by ''
stored as textfile;
id statyear num |
我们的目的是,以id为key做join操作,得到以下表:m_ys_lab_jointest_ab
| id name statyear num 1 北京 2011 2019 1 北京 2010 1962 2 天津 2011 1355 2 天津 2010 1299 4 山西 2011 3593 4 山西 2010 3574 |
二.计算模型
整个计算过程是:
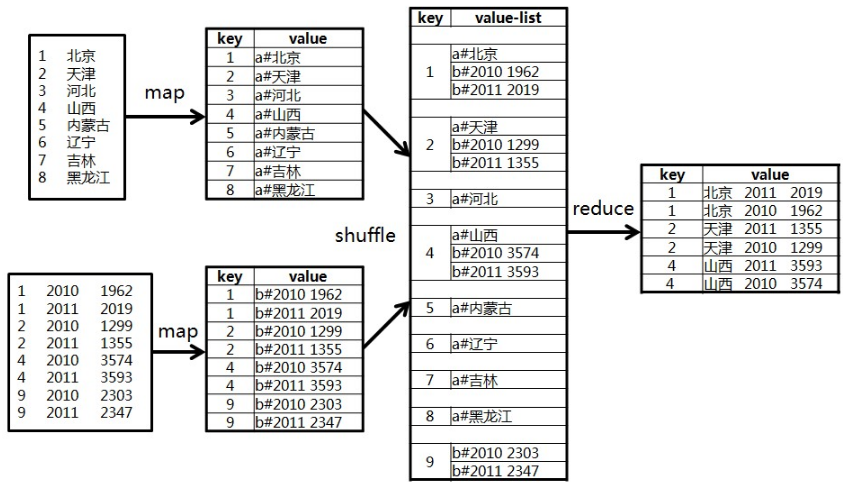
上代码:
import java.io.IOException;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileSplit;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter; /**
* MapReduce实现Join操作
*/
public class MapRedJoin {
public static final String DELIMITER = "\u0009"; // 字段分隔符 // map过程
public static class MapClass extends MapReduceBase implements Mapper<LongWritable, Text, Text, Text> {
public void configure(JobConf job) {
super.configure(job);
} public void map(LongWritable key, Text value, OutputCollector<Text, Text> output, Reporter reporter) throws IOException, ClassCastException {
// 获取输入文件的全路径和名称
String filePath = ((FileSplit)reporter.getInputSplit()).getPath().toString();
// 获取记录字符串
String line = value.toString();
// 抛弃空记录
if (line == null || line.equals("")){
return;
}
// 处理来自表A的记录
if (filePath.contains("m_ys_lab_jointest_a")) {
String[] values = line.split(DELIMITER); // 按分隔符分割出字段
if (values.length < 2){
return;
}
String id = values[0]; // id
String name = values[1]; // name
output.collect(new Text(id), new Text("a#"+name));
} else if (filePath.contains("m_ys_lab_jointest_b")) {// 处理来自表B的记录
String[] values = line.split(DELIMITER); // 按分隔符分割出字段
if (values.length < 3){
return;
}
String id = values[0]; // id
String statyear = values[1]; // statyear
String num = values[2]; //num
output.collect(new Text(id), new Text("b#"+statyear+DELIMITER+num));
}
}
} // reduce过程
public static class Reduce extends MapReduceBase implements Reducer<Text, Text, Text, Text> {
public void reduce(Text key, Iterator<Text> values, OutputCollector<Text, Text> output, Reporter reporter) throws IOException {
List<String> listA = new ArrayList<String>(); // 存放来自表A的值
List<String> listB = new ArrayList<String>(); // 存放来自表B的值
while (values.hasNext()) {
String value = values.next().toString();
if (value.startsWith("a#")) {
listA.add(value.substring(2));
} else if (value.startsWith("b#")) {
listB.add(value.substring(2));
}
}
int sizeA = listA.size();
int sizeB = listB.size();
// 遍历两个向量
int i, j;
for (i = 0; i < sizeA; i ++) {
for (j = 0; j < sizeB; j ++) {
output.collect(key, new Text(listA.get(i) + DELIMITER +listB.get(j)));
}
}
}
} protected void configJob(JobConf conf) {
conf.setMapOutputKeyClass(Text.class);
conf.setMapOutputValueClass(Text.class);
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(Text.class);
conf.setOutputFormat(ReportOutFormat.class);
}
}
三.技术细节
0 MapReduce实现Reduce Side Join操作的更多相关文章
- MapReduce的Reduce side Join
1. 简单介绍 reduce side join是全部join中用时最长的一种join,可是这样的方法可以适用内连接.left外连接.right外连接.full外连接和反连接等全部的join方式.r ...
- 使用MapReduce实现join操作
在关系型数据库中,要实现join操作是非常方便的,通过sql定义的join原语就可以实现.在hdfs存储的海量数据中,要实现join操作,可以通过HiveQL很方便地实现.不过HiveQL也是转化成 ...
- MapReduce 实现数据join操作
前段时间有一个业务需求,要在外网商品(TOPB2C)信息中加入 联营自营 识别的字段.但存在的一个问题是,商品信息 和 自营联营标示数据是 两份数据:商品信息较大,是存放在hbase中.他们之前唯一的 ...
- Hadoop基础-MapReduce的Join操作
Hadoop基础-MapReduce的Join操作 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.连接操作Map端Join(适合处理小表+大表的情况) no001 no002 ...
- Hadoop学习之路(二十一)MapReduce实现Reduce Join(多个文件联合查询)
MapReduce Join 对两份数据data1和data2进行关键词连接是一个很通用的问题,如果数据量比较小,可以在内存中完成连接. 如果数据量比较大,在内存进行连接操会发生OOM.mapredu ...
- 案例-使用MapReduce实现join操作
哈喽-各位小伙伴们中秋快乐,好久没更新新的文章啦,今天分享如何使用mapreduce进行join操作. 在离线计算中,我们常常不只是会对单一一个文件进行操作,进行需要进行两个或多个文件关联出更多数据, ...
- mapreduce join操作
上次和朋友讨论到mapreduce,join应该发生在map端,理由太想当然到sql里面的执行过程了 wheremap端 join在map之前(笛卡尔积),但实际上网上看了,mapreduce的笛卡尔 ...
- Mapreduce中的join操作
一.背景 MapReduce提供了表连接操作其中包括Map端join.Reduce端join还有半连接,现在我们要讨论的是Map端join,Map端join是指数据到达map处理函数之前进行合并的,效 ...
- [MapReduce_add_4] MapReduce 的 join 操作
0. 说明 Map 端 join && Reduce 端 join 1. Map 端 join Map 端 join:大表+小表 => 将小表加入到内存,迭代大表每一行,与之进行 ...
随机推荐
- .NET中生成水印更好的方法
.NET中生成水印更好的方法 为了保护知识产权,防止资源被盗用,水印在博客.网店等场景中非常常见. 本文首先演示了基于System.Drawing.Image做正常操作.然后基于Direct2D/WI ...
- .NET开发框架(一)-框架介绍与视频演示
本文主要介绍一套基于.NET CORE的SPA高并发.高可用的开发框架. 我们暂且称它为:(让你懂.NET)开发框架. 以此为主线,陆续编写教程,讲述如何构建高并发.高可用的框架. (欢迎转载与分享) ...
- Unity Shader 玻璃效果
一个玻璃效果主要分为两个部分,一部分是折射效果的计算,另一部分则是反射.下面分类进行讨论: 折射: 1.利用Grass Pass对当前屏幕的渲染图像进行采样 2.得到法线贴图对折射的影响 3.对采集的 ...
- 常用的HTTP状态代码(4xx、5xx)详解
HTTP状态代码常用的如下: 400 无法解析此请求. 401.1 未经授权:访问由于凭据无效被拒绝. 401.2 未经授权: 访问由于服务器配置倾向使用替代身份验证方法而被拒绝. 401.3 未经授 ...
- Azkaban学习之路(四)—— Azkaban Flow 2.0的使用
一.Flow 2.0 简介 1.1 Flow 2.0 的产生 Azkaban 目前同时支持 Flow 1.0 和 Flow2.0 ,但是官方文档上更推荐使用Flow 2.0,因为Flow 1.0会在将 ...
- 给 Windows 的终端配置代理
初衷 由于项目开发使用go,所以经常要用到go get,但是吧,terminal下根本没办法下载啊,经常下载三个小时包,写代码一个小时 迫于无奈,只好找个方式可以在terminal下使用ss cmd下 ...
- AbstractQueuedSynchronizer(AQS)源码解析
关于AQS的源码解析,本来是没有打算特意写一篇文章来介绍的.不过在写本学期课程作业中,有一门写了关于AQS的,而且也画了一些相关的图,所以直接拿过来分享一下,如有错误欢迎指正. ...
- docker开启2376端口CA认证及IDEA中一键部署docker项目
嘿,大家好,今天更新的内容是docker开启2376端口CA认证及IDEA中一键部署docker项目... 先看效果 我们可以通过idea一键部署docker项目,还以通过idea的控制台实时查看容器 ...
- 详解Linux运维工程师必备技能
张戈大神是腾讯的一名运维,张戈博客也是我接触到第一个 Linux 运维师的博客,最近也在接触 Linux,说到工具,在行外可以说是技能,在行内一般称为工具,就是运维必须要掌握的工具. 我就大概列出这几 ...
- Charles抓包工具_基本功能
一. 安装及破解 1. 安装: 下载地址:http://www.charlesproxy.com/download/,然后进行安装: 2. 破解: 将补丁文件charles.jar复制到安装目录并替换 ...