Hadoop —— 单机环境搭建
一、前置条件
Hadoop的运行依赖JDK,需要预先安装,安装步骤见:
二、配置免密登录
Hadoop组件之间需要基于SSH进行通讯。
2.1 配置映射
配置ip地址和主机名映射:
vim /etc/hosts
# 文件末尾增加
192.168.43.202 hadoop001
2.2 生成公私钥
执行下面命令行生成公匙和私匙:
ssh-keygen -t rsa
3.3 授权
进入~/.ssh目录下,查看生成的公匙和私匙,并将公匙写入到授权文件:
[root@@hadoop001 sbin]# cd ~/.ssh
[root@@hadoop001 .ssh]# ll
-rw-------. 1 root root 1675 3月 15 09:48 id_rsa
-rw-r--r--. 1 root root 388 3月 15 09:48 id_rsa.pub
# 写入公匙到授权文件
[root@hadoop001 .ssh]# cat id_rsa.pub >> authorized_keys
[root@hadoop001 .ssh]# chmod 600 authorized_keys
三、Hadoop(HDFS)环境搭建
3.1 下载并解压
下载Hadoop安装包,这里我下载的是CDH版本的,下载地址为:http://archive.cloudera.com/cdh5/cdh/5/
# 解压
tar -zvxf hadoop-2.6.0-cdh5.15.2.tar.gz
3.2 配置环境变量
# vi /etc/profile
配置环境变量:
export HADOOP_HOME=/usr/app/hadoop-2.6.0-cdh5.15.2
export PATH=${HADOOP_HOME}/bin:$PATH
执行source命令,使得配置的环境变量立即生效:
# source /etc/profile
3.3 修改Hadoop配置
进入${HADOOP_HOME}/etc/hadoop/目录下,修改以下配置:
1. hadoop-env.sh
# JDK安装路径
export JAVA_HOME=/usr/java/jdk1.8.0_201/
2. core-site.xml
<configuration>
<property>
<!--指定namenode的hdfs协议文件系统的通信地址-->
<name>fs.defaultFS</name>
<value>hdfs://hadoop001:8020</value>
</property>
<property>
<!--指定hadoop存储临时文件的目录-->
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
</configuration>
3. hdfs-site.xml
指定副本系数和临时文件存储位置:
<configuration>
<property>
<!--由于我们这里搭建是单机版本,所以指定dfs的副本系数为1-->
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
4. slaves
配置所有从属节点的主机名或IP地址,由于是单机版本,所以指定本机即可:
hadoop001
3.4 关闭防火墙
不关闭防火墙可能导致无法访问Hadoop的Web UI界面:
# 查看防火墙状态
sudo firewall-cmd --state
# 关闭防火墙:
sudo systemctl stop firewalld.service
3.5 初始化
第一次启动Hadoop时需要进行初始化,进入${HADOOP_HOME}/bin/目录下,执行以下命令:
[root@hadoop001 bin]# ./hdfs namenode -format
3.6 启动HDFS
进入${HADOOP_HOME}/sbin/目录下,启动HDFS:
[root@hadoop001 sbin]# ./start-dfs.sh
3.7 验证是否启动成功
方式一:执行jps查看NameNode和DataNode服务是否已经启动:
[root@hadoop001 hadoop-2.6.0-cdh5.15.2]# jps
9137 DataNode
9026 NameNode
9390 SecondaryNameNode
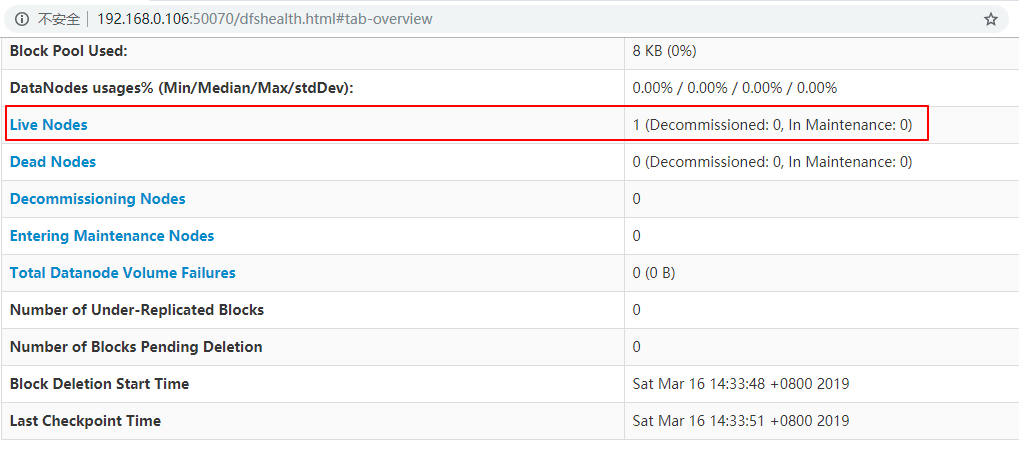
方式二:查看Web UI界面,端口为50070:
四、Hadoop(YARN)环境搭建
4.1 修改配置
进入${HADOOP_HOME}/etc/hadoop/目录下,修改以下配置:
1. mapred-site.xml
# 如果没有mapred-site.xml,则拷贝一份样例文件后再修改
cp mapred-site.xml.template mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2. yarn-site.xml
<configuration>
<property>
<!--配置NodeManager上运行的附属服务。需要配置成mapreduce_shuffle后才可以在Yarn上运行MapReduce程序。-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
4.2 启动服务
进入${HADOOP_HOME}/sbin/目录下,启动YARN:
./start-yarn.sh
4.3 验证是否启动成功
方式一:执行jps命令查看NodeManager和ResourceManager服务是否已经启动:
[root@hadoop001 hadoop-2.6.0-cdh5.15.2]# jps
9137 DataNode
9026 NameNode
12294 NodeManager
12185 ResourceManager
9390 SecondaryNameNode
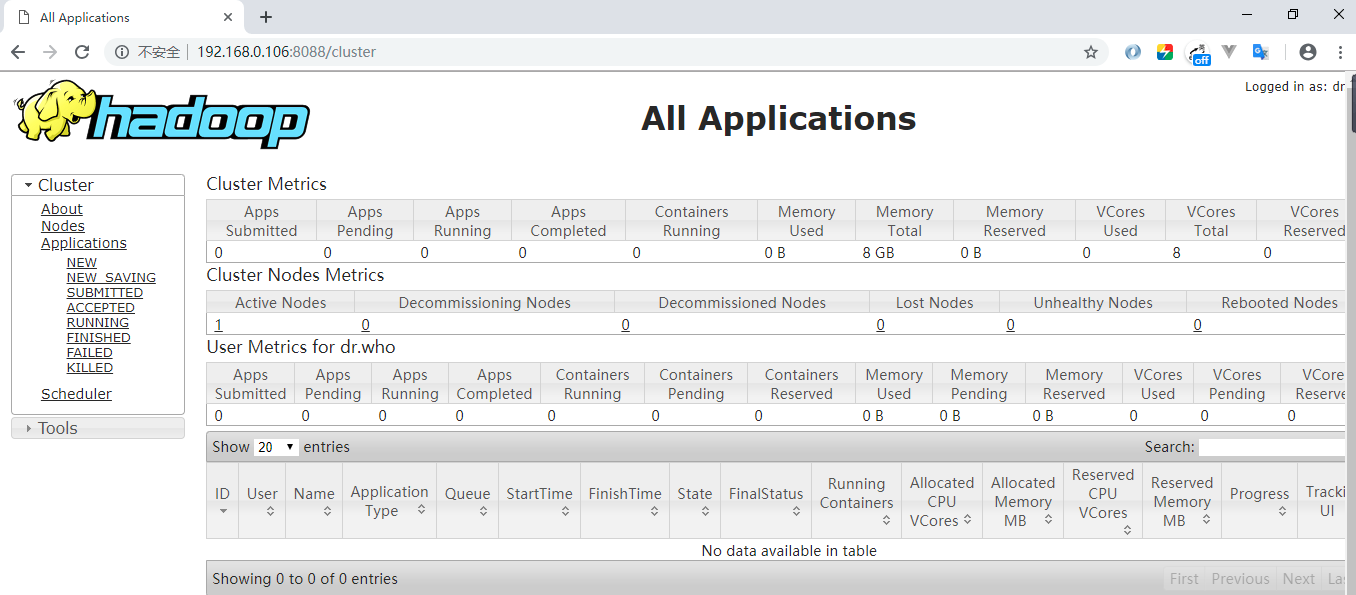
方式二:查看Web UI界面,端口号为8088:
更多大数据系列文章可以参见个人 GitHub 开源项目: 程序员大数据入门指南
一、前置条件
Hadoop的运行依赖JDK,需要预先安装,安装步骤见:
二、配置免密登录
Hadoop组件之间需要基于SSH进行通讯。
2.1 配置映射
配置ip地址和主机名映射:
vim /etc/hosts
# 文件末尾增加
192.168.43.202 hadoop001
2.2 生成公私钥
执行下面命令行生成公匙和私匙:
ssh-keygen -t rsa
3.3 授权
进入~/.ssh目录下,查看生成的公匙和私匙,并将公匙写入到授权文件:
[root@@hadoop001 sbin]# cd ~/.ssh
[root@@hadoop001 .ssh]# ll
-rw-------. 1 root root 1675 3月 15 09:48 id_rsa
-rw-r--r--. 1 root root 388 3月 15 09:48 id_rsa.pub
# 写入公匙到授权文件
[root@hadoop001 .ssh]# cat id_rsa.pub >> authorized_keys
[root@hadoop001 .ssh]# chmod 600 authorized_keys
三、Hadoop(HDFS)环境搭建
3.1 下载并解压
下载Hadoop安装包,这里我下载的是CDH版本的,下载地址为:http://archive.cloudera.com/cdh5/cdh/5/
# 解压
tar -zvxf hadoop-2.6.0-cdh5.15.2.tar.gz
3.2 配置环境变量
# vi /etc/profile
配置环境变量:
export HADOOP_HOME=/usr/app/hadoop-2.6.0-cdh5.15.2
export PATH=${HADOOP_HOME}/bin:$PATH
执行source命令,使得配置的环境变量立即生效:
# source /etc/profile
3.3 修改Hadoop配置
进入${HADOOP_HOME}/etc/hadoop/目录下,修改以下配置:
1. hadoop-env.sh
# JDK安装路径
export JAVA_HOME=/usr/java/jdk1.8.0_201/
2. core-site.xml
<configuration>
<property>
<!--指定namenode的hdfs协议文件系统的通信地址-->
<name>fs.defaultFS</name>
<value>hdfs://hadoop001:8020</value>
</property>
<property>
<!--指定hadoop存储临时文件的目录-->
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
</configuration>
3. hdfs-site.xml
指定副本系数和临时文件存储位置:
<configuration>
<property>
<!--由于我们这里搭建是单机版本,所以指定dfs的副本系数为1-->
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
4. slaves
配置所有从属节点的主机名或IP地址,由于是单机版本,所以指定本机即可:
hadoop001
3.4 关闭防火墙
不关闭防火墙可能导致无法访问Hadoop的Web UI界面:
# 查看防火墙状态
sudo firewall-cmd --state
# 关闭防火墙:
sudo systemctl stop firewalld.service
3.5 初始化
第一次启动Hadoop时需要进行初始化,进入${HADOOP_HOME}/bin/目录下,执行以下命令:
[root@hadoop001 bin]# ./hdfs namenode -format
3.6 启动HDFS
进入${HADOOP_HOME}/sbin/目录下,启动HDFS:
[root@hadoop001 sbin]# ./start-dfs.sh
3.7 验证是否启动成功
方式一:执行jps查看NameNode和DataNode服务是否已经启动:
[root@hadoop001 hadoop-2.6.0-cdh5.15.2]# jps
9137 DataNode
9026 NameNode
9390 SecondaryNameNode
方式二:查看Web UI界面,端口为50070:
四、Hadoop(YARN)环境搭建
4.1 修改配置
进入${HADOOP_HOME}/etc/hadoop/目录下,修改以下配置:
1. mapred-site.xml
# 如果没有mapred-site.xml,则拷贝一份样例文件后再修改
cp mapred-site.xml.template mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2. yarn-site.xml
<configuration>
<property>
<!--配置NodeManager上运行的附属服务。需要配置成mapreduce_shuffle后才可以在Yarn上运行MapReduce程序。-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
4.2 启动服务
进入${HADOOP_HOME}/sbin/目录下,启动YARN:
./start-yarn.sh
4.3 验证是否启动成功
方式一:执行jps命令查看NodeManager和ResourceManager服务是否已经启动:
[root@hadoop001 hadoop-2.6.0-cdh5.15.2]# jps
9137 DataNode
9026 NameNode
12294 NodeManager
12185 ResourceManager
9390 SecondaryNameNode
方式二:查看Web UI界面,端口号为8088:
更多大数据系列文章可以参见个人 GitHub 开源项目: 程序员大数据入门指南
Hadoop —— 单机环境搭建的更多相关文章
- hadoop单机环境搭建
[在此处输入文章标题] Hadoop单机搭建 1. 工具准备 1) Hadoop Linux安装包 2) VMware虚拟机 3) Java Linux安装包 4) Window 电脑一台 2. 开始 ...
- 攻城狮在路上(陆)-- hadoop单机环境搭建(一)
一.环境说明: 操作系统:Centos6.5 Linux node1 2.6.32-431.el6.x86_64 #1 SMP Fri Nov 22 03:15:09 UTC 2013 x86 ...
- Hadoop单机环境搭建整体流程
1. Ubuntu环境安装和基本配置 本例程中在MAC上安装使用的虚拟机Ubuntu系统(64位,desktop): 基本配置 考虑到以后涉及到hadoop的应用便于权限的管理,特别地创建一个ha ...
- [转载] Hadoop和Hive单机环境搭建
转载自http://blog.csdn.net/yfkiss/article/details/7715476和http://blog.csdn.net/yfkiss/article/details/7 ...
- 【HADOOP】| 环境搭建:从零开始搭建hadoop大数据平台(单机/伪分布式)-下
因篇幅过长,故分为两节,上节主要说明hadoop运行环境和必须的基础软件,包括VMware虚拟机软件的说明安装.Xmanager5管理软件以及CentOS操作系统的安装和基本网络配置.具体请参看: [ ...
- Hadoop单机Hadoop测试环境搭建
Hadoop单机Hadoop测试环境搭建: 1. 安装jdk,并配置环境变量,配置ssh免密码登录 2. 下载安装包hadoop-2.7.3.tar.gz 3. 配置/etc/hosts 127.0. ...
- Hadoop之环境搭建
初学Hadoop之环境搭建 阅读目录 1.安装CentOS7 2.安装JDK1.7.0 3.安装Hadoop2.6.0 4.SSH无密码登陆 本文仅作为学习笔记,供大家初学Hadoop时学习参考. ...
- Hadoop生产环境搭建(含HA、Federation)
Hadoop生产环境搭建 1. 将安装包hadoop-2.x.x.tar.gz存放到某一目录下,并解压. 2. 修改解压后的目录中的文件夹etc/hadoop下的配置文件(若文件不存在,自己创建.) ...
- Hadoop 系列(四)—— Hadoop 开发环境搭建
一.前置条件 Hadoop 的运行依赖 JDK,需要预先安装,安装步骤见: Linux 下 JDK 的安装 二.配置免密登录 Hadoop 组件之间需要基于 SSH 进行通讯. 2.1 配置映射 配置 ...
随机推荐
- JDBC 使用这个是MySQL下的
import java.sql.Connection;import java.sql.DriverManager;import java.sql.ResultSet;import java.sql.R ...
- Codeforces 15C Industrial Nim 简单的游戏
主题链接:点击打开链接 意甲冠军: 特定n 下列n行,每一行2的数量u v 表达v礧:u,u+1,u+2···u+v-1 问先手必胜还是后手必胜 思路: 首先依据Nim的博弈结论 把全部数都异或一下, ...
- 1.通过模板创建MAP版本项目
1.选择mpa+ef+module-zero 取名字 2.用vs打开项目后,在解决方案上右键 还原nuget包 3.打开程序包管理器控制台,选择以EntityFramework结尾的项目,并执行upd ...
- WPF模拟Office2010文件菜单的TabControl模板
原文:WPF模拟Office2010文件菜单的TabControl模板 这是Office2010中的文件菜单点开后的效果.本文我将以强大的WPF(www.itstrike.cn)来实现类似的效果.希望 ...
- OpenGL(四) 左右手坐标系及基本坐标变换
左手坐标系.右手坐标系.笛卡尔坐标系 左手坐标系:伸开左手,大拇指指向X轴正方向,食指指向Y轴正方向,其他三个手指指向Z轴正方向. 右手坐标系:伸开右手,大拇指指向X轴正方向,食指指向Y轴正方向,其他 ...
- 【书单】matlab 科学计算、数值分析以及数学物理问题
1. 数学计算 MATLAB数值计算 MATLAB之父 : 编程实践 2. 数学物理问题 高等应用数学问题的MATLAB求解(第3版)(豆瓣评价极好) 3. 模式识别
- C++学习笔记27,虚函数作品
C++它指定虚函数的行为,但实现的作者编译器. 通常,编译器处理虚函数的方法是给每个对象加入一个隐藏成员.隐藏成员中保存了一个指向函数地址数组的指针. 这个数组称为虚函数表(virtual funct ...
- ajax默认form表单提交,导致实体不识别
出现位置:实体比较复杂,包含List之类的时候 public class AdvertisementType { /// <summary> /// 广告位名称 /// </summ ...
- OnPropertyChanged的使用
#region INotifyPropertyChanged public event PropertyChangedEventHandler PropertyChanged; ...
- 【转】关于List排序的时效性
不多说了,就是说明List排序的时效性,仅仅用来备忘,改造自: http://blog.csdn.net/wanzhuan2010/article/details/6205884,感谢原作者 usin ...