6.2.2 辅助类GenericOptionsParser,Tool和ToolRunner深入解析
辅助类GenericOptionsParser,Tool和ToolRunner
(1)为什么要用ToolRunner
将MapReduce Job配置参数写到java代码里,一旦变更意味着修改java文件源码、编译、打包、部署一连串事情。当MapReduce 依赖配置文件的时候,你需要手工编写java代码使用DistributedCache将其上传到HDFS中,以便map和reduce函数可以读取。:当你的map或reduce 函数依赖第三方jar文件时,你在命令行中使用”-libjars”参数指定依赖jar包时,但根本没生效。Hadoop有个可以GenericOptionsParser是一个类,用来解释常用的Hadoop命令行选项,通过简单的命令行参数来实现这样的功能,为Configuration对象设置相应的取值。通常不直接使用GenericOptionsParser,更方便的方式是:实现Tool接口,通过ToolRunner来运行应用程序,ToolRunner内部调用GenericOptionsParser来解析命令行。设置Configuration对象。
(2)使用ToolRunner步骤
自定义一个ToolRunner类ToolRunnerDemo类,继承Configured类,实现Tool接口,实现Tool的run(String [] args)方法,并在main函数中调用ToolRunner. run(Tool tool, String[] args)静态方法。Run方法内部创建GenericOptionsParser parser = new GenericOptionsParser(conf, args);调用GenericOptionsParser解析命令行参数,解析完之后将参数设置到Configuration对象中。
1)创建ToolRunnerDemo对象
package org.jediael.hadoopdemo.toolrunnerdemo;
import java.util.Map.Entry;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class ToolRunnerDemo extends Configured implements Tool {
static {
//Configuration.addDefaultResource("hdfs-default.xml");
//Configuration.addDefaultResource("hdfs-site.xml");
//Configuration.addDefaultResource("mapred-default.xml");
//Configuration.addDefaultResource("mapred-site.xml");
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
for (Entry<String, String> entry : conf) {
System.out.printf("%s=%s\n", entry.getKey(), entry.getValue());
}
return 0;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new ToolRunnerDemo(), args);//ToolRunnerDemo对象实现了Tool接口,形参传入对象引用,在调用tool.run()方法,实际是调用ToolRunner重写的run方法。
System.exit(exitCode);
}
}
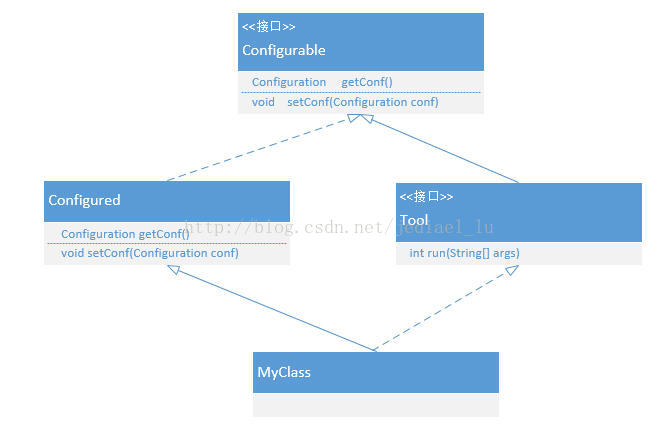
Configurable接口只有两个函数,获取设置Configuration对象
package org.apache.hadoop.conf;
public interface Configurable {
void setConf(Configuration conf);
Configuration getConf();
}
Configred类实现了Configurable接口
package org.apache.hadoop.conf;
public class Configured implements Configurable {
private Configuration conf;
public Configured() {
this(null);
}
public Configured(Configuration conf) {
setConf(conf);
}
public void setConf(Configuration conf) {
this.conf = conf;
}
public Configuration getConf() {
return conf;
}
}
2)ToolRunner.run()函数内部创建GenericOptionsParser对象
public static int run(Configuration conf, Tool tool, String[] args) throws Exception {
if (conf == null) {
conf = new Configuration();
}
GenericOptionsParser parser = new GenericOptionsParser(conf, args);
tool.setConf(conf);
String[] toolArgs = parser.getRemainingArgs();
return tool.run(toolArgs);
}
3)GenericOptionsParser构造函数1调用构造函数2,构造函数2调用解析函数parseGeneralOptions
public GenericOptionsParser(Options opts, String[] args) throws IOException {
this(new Configuration(), opts, args);
}//构造函数1
public GenericOptionsParser(Configuration conf, Options options, String[] args) throws IOException {
this.parseGeneralOptions(options, conf, args);
this.conf = conf;
}//构造函数2
4)parseGeneralOptions先调用解析函数parser.parse解析命令行,然后再用函数this.processGeneralOptions()执行命令。
private void parseGeneralOptions(Options opts, Configuration conf, String[] args) throws IOException {
opts = buildGeneralOptions(opts);
GnuParser parser = new GnuParser();
try {
this.commandLine = parser.parse(opts, this.preProcessForWindows(args), true);
this.processGeneralOptions(conf, this.commandLine);
} catch (ParseException var7) {
LOG.warn("options parsing failed: " + var7.getMessage());
HelpFormatter formatter = new HelpFormatter();
formatter.printHelp("general options are: ", opts);
}
}
5)processGeneralOptions函数内部会根据不同的命令选项:fs、jt、conf、libjars、files、archives进行设置。
private void processGeneralOptions(Configuration conf, CommandLine line) throws IOException {
//设置默认的文件系统
if (line.hasOption("fs")) {
FileSystem.setDefaultUri(conf, line.getOptionValue("fs"));
}
//设置jobtracker服务ip地址和端口,用于监听并接收来自各个TaskTracker发送的心跳信息,包括资源使用情况和任务运行情况等信息。
String fileName;
if (line.hasOption("jt")) {
fileName = line.getOptionValue("jt");
if (fileName.equalsIgnoreCase("local")) {
conf.set("mapreduce.framework.name", fileName);
}
conf.set("yarn.resourcemanager.address", fileName, "from -jt command line option");
}
//添加新的配置文件
String[] arr$;
int len$;
int i$;
String prop;
String[] property;
if (line.hasOption("conf")) {
property = line.getOptionValues("conf");
arr$ = property;
len$ = property.length;
for(i$ = 0; i$ < len$; ++i$) {
prop = arr$[i$];
conf.addResource(new Path(prop));
}
}
//从本地文件系统中复制指定的jar包到jobtracker使用的共享文件系统中,添加到mapreduce任务路径,这个选项是一个很有用放入方法来添加任务的依赖jar包。
if (line.hasOption("libjars")) {
conf.set("tmpjars", this.validateFiles(line.getOptionValue("libjars"), conf), "from -libjars command line option");
URL[] libjars = getLibJars(conf);
if (libjars != null && libjars.length > 0) {
conf.setClassLoader(new URLClassLoader(libjars, conf.getClassLoader()));
Thread.currentThread().setContextClassLoader(new URLClassLoader(libjars, Thread.currentThread().getContextClassLoader()));
}
}
//从本地文件系统中复制指定的文件到jobtracker使用的共享文件系统中,使他们能够被mapreduce任务使用
if (line.hasOption("files")) {
conf.set("tmpfiles", this.validateFiles(line.getOptionValue("files"), conf), "from -files command line option");
}
//从本地文件系统中复制指定的档案到jobtracker使用的共享文件系统中,使他们能够被mapreduce任务使用。
if (line.hasOption("archives")) {
conf.set("tmparchives", this.validateFiles(line.getOptionValue("archives"), conf), "from -archives command line option");
}
//给属性设置属性值
if (line.hasOption('D')) {
property = line.getOptionValues('D');
arr$ = property;
len$ = property.length;
for(i$ = 0; i$ < len$; ++i$) {
prop = arr$[i$];
String[] keyval = prop.split("=", 2);
if (keyval.length == 2) {
conf.set(keyval[0], keyval[1], "from command line");
}
}
}
conf.setBoolean("mapreduce.client.genericoptionsparser.used", true);
if (line.hasOption("tokenCacheFile")) {
fileName = line.getOptionValue("tokenCacheFile");
FileSystem localFs = FileSystem.getLocal(conf);
Path p = localFs.makeQualified(new Path(fileName));
if (!localFs.exists(p)) {
throw new FileNotFoundException("File " + fileName + " does not exist.");
}
if (LOG.isDebugEnabled()) {
LOG.debug("setting conf tokensFile: " + fileName);
}
UserGroupInformation.getCurrentUser().addCredentials(Credentials.readTokenStorageFile(p, conf));
conf.set("mapreduce.job.credentials.json", p.toString(), "from -tokenCacheFile command line option");
}
}
6)设置好配置之后,所有的命令行都解析执行,参数都添加到了Configuration对象之中,接下来就可以获取这些参数。
在第2)步的ToolRunner的run函数中
public static int run(Configuration conf, Tool tool, String[] args) throws Exception {
if (conf == null) {
conf = new Configuration();
}
GenericOptionsParser parser = new GenericOptionsParser(conf, args);
tool.setConf(conf);
String[] toolArgs = parser.getRemainingArgs();
return tool.run(toolArgs);
}
parser.getRemainingArgs();获取的实际上是第4)步中解析的命令行参数
public String[] getRemainingArgs() {
return this.commandLine == null ? new String[0] : this.commandLine.getArgs();
}
7)调用tool接口的run方法,实际是调用ToolRunnerDemo重写的run方法。因为ToolRunnerDemo对象实现了Tool接口,ToolRunner.run函数形参传入ToolRunnerDemo对象引用,在调用tool.run()方法, 实际是调用ToolRunnerDemo重写的run方法。
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
for (Entry<String, String> entry : conf) {//输出所有的属性值
System.out.printf("%s=%s\n", entry.getKey(), entry.getValue());
}
return 0;
}
(3)使用ToolRunnerDemo设置hadoop参数调用实例
1)使用ToolRunnerDemo输出所有配置属性
[root@jediael project]#hadoop jar toolrunnerdemo.jar org.jediael.hadoopdemo.toolrunnerdemo.ToolRunnerDemo
io.seqfile.compress.blocksize=1000000
keep.failed.task.files=false
mapred.disk.healthChecker.interval=60000
dfs.df.interval=60000
dfs.datanode.failed.volumes.tolerated=0
mapreduce.reduce.input.limit=-1
mapred.task.tracker.http.address=0.0.0.0:50060
mapred.used.genericoptionsparser=true
mapred.userlog.retain.hours=24
dfs.max.objects=0
mapred.jobtracker.jobSchedulable=org.apache.hadoop.mapred.JobSchedulable
mapred.local.dir.minspacestart=0
hadoop.native.lib=true
2)通过-D指定新的参数,-D设置参数color为yello,grep查看设置属性
[root@jediael project]# hadoop org.jediael.hadoopdemo.toolrunnerdemo.ToolRunnerDemo -D color=yello | grep color
color=yello
3)通过-conf增加新的配置文件,-conf用于添加配置文件,wc命令用于查看配置数量。
hadoop jar toolrunnerdemo.jar org.jediael.hadoopdemo.toolrunnerdemo.ToolRunnerDemo-conf /opt/jediael/hadoop-1.2.0/conf/mapred-site.xml | wc
68 68 3028
其中mapred-site.xml的内容如下:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration>
(4)ToolRunner使用汇总
|
-D color=yello |
-D设置参数color为yello,grep查看设置属性 |
|
-conf conf/mapred-site.xml |
-conf用于添加配置文件 |
|
-fs uri |
//设置文件系统为uri指定的路径,等同-D fs.default.FS=url |
|
-jt 10.21.34.11:3800 |
//hadoop1中用于设置jobtracker的ip地址和端口,用于监听并接收来自各个TaskTracker发送的心跳信息,包括资源使用情况和任务运行情况等信息。hadoop2中用于指定YARN资源管理器地址。等同-D yarn.resourcemanager.address= 10.21.34.11:3800. |
|
-files file1,file2 |
从本地文件系统中复制指定的文件到jobtracker使用的共享文件系统中,使他们能够被mapreduce任务使用 |
|
-libjars jars1,jars2 |
从本地文件系统中复制指定的jar包到jobtracker使用的共享文件系统中,添加到mapreduce任务路径,这个选项是一个很有用放入方法来添加任务的依赖jar包。 |
|
-archives archive1,archive2 |
从本地文件系统中复制指定的档案到jobtracker使用的共享文件系统中,使他们能够被mapreduce任务使用。 |
参考文献:
https://blog.csdn.net/xin15200793067/article/details/12623797
https://blog.csdn.net/jediael_lu/article/details/38751885
https://blog.csdn.net/tototuzuoquan/article/details/72856761
自己开发了一个股票智能分析软件,功能很强大,需要的点击下面的链接获取:
https://www.cnblogs.com/bclshuai/p/11380657.html
6.2.2 辅助类GenericOptionsParser,Tool和ToolRunner深入解析的更多相关文章
- 关于Tool接口--------hadoop接口:extends Configured implements Tool 和 ToolRunner.run
我们在写Hadoop--map/reduce程序时,遇到使用按文件url来分析文件----------多表连接的DistributedCache方式,看不懂使用extends Configured i ...
- MapReduce编程实战之“调试”和"调优"
本篇内容 在上一篇的"初识"环节,我们已经在本地和Hadoop集群中,成功的执行了几个MapReduce程序,对MapReduce编程,已经有了最初的理解. 在本篇文章中,我们对M ...
- 使用ToolRunner运行Hadoop程序基本原理分析
为了简化命令行方式运行作业,Hadoop自带了一些辅助类.GenericOptionsParser是一个类,用来解释常用的Hadoop命令行选项,并根据需要,为Configuration对象设置相应的 ...
- 采用ToolRunner执行Hadoop基本面分析程序
为了简化执行作业的命令行.Hadoop它配备了一些辅助类.GenericOptionsParser它是一类.经常用来解释Hadoop命令行选项,并根据需要.至Configuration采取相应的对象设 ...
- 使用ToolRunner运行Hadoop程序基本原理分析 分类: A1_HADOOP 2014-08-22 11:03 3462人阅读 评论(1) 收藏
为了简化命令行方式运行作业,Hadoop自带了一些辅助类.GenericOptionsParser是一个类,用来解释常用的Hadoop命令行选项,并根据需要,为Configuration对象设置相应的 ...
- 解析GenericOptionsParser
hadoop源代码分析(4)-org.apache.hadoop.util包-GenericOptionsParser类[原创] 一 准备 hadoop版本:1.0.3,GenericOptio ...
- hadoop MapReduce 笔记
1. MapReduce程序开发步骤 编写map 和 reduce 程序–> 单元测试 -> 编写驱动程序进行验证-> 本地数据集调试 -> 部署到集群运行 用 ...
- Nutch源码阅读进程1---inject
最近在Ubuntu下配置好了nutch和solr的环境,也用nutch爬取了一些网页,通过solr界面呈现,也过了一把自己建立小搜索引擎的瘾,现在该静下心来好好看看nutch的源码了,先从Inject ...
- 《Hadoop权威》学习笔记五:MapReduce应用程序
一.API的配置---Configuration类 API的配置:Hadoop提供了专门的API对资源进行配置,Configuration类的实例(在org.apache.hadoop.conf包)包 ...
随机推荐
- 域渗透基础之Kerberos认证协议
本来昨晚就该总结整理,又拖到今天早上..6点起来赶可还行 0x01 Kerberos前言 Kerberos 是一种由 MIT(麻省理工大学)提出的一种网络身份验证协议.它旨在通过使用密钥加密技术为客 ...
- docker配置阿里云镜像
今天docker pull镜像的时候太慢了 所以这里配置下阿里云镜像 打开阿里云控制台,没有的可以用淘宝账号或者支付宝账号直接登录 打开容器镜像服务,镜像加速器,复制加速器地址 修改配置文件 $: ...
- phpstorm格式设置不同导致的Git代码无法正常比较
多人开发代码,使用Git作为管理工具,遇到一个问题是 : IDE的格式设置不一样导致的整个文件无法正常的比较. window 和 linux 以及 mac 不同平台的换行符是导致这一个问题比较常见的原 ...
- Python开发【第十一篇】函数
函数 什么是函数? 函数是可以重复执行的语句块,可以重复调用并执行函数的面向过程编程的最小单位. 函数的作用: 函数用于封装语句块,提高代码的重用性,定义用户级别的函数.提高代码的可读性和易维护性. ...
- 浅谈爬虫 《一》 ===python
浅谈爬虫 <一> ===python ‘’正文之前先啰嗦一下,准确来说,在下还只是一个刚入门IT世界的菜鸟,工作近两年了,之前做前端的时候就想写博客来着,现在都转做python了,如果还 ...
- vue css 深度选择器
在我们想穿透的选择器前边添加 >>> 或者 /deep/ 或者 ::v-deep. 官方地址:https://vue-loader.vuejs.org/guide/scoped-cs ...
- 图论-最短路径<Dijkstra,Floyd>
昨天: 图论-概念与记录图的方法 以上是昨天的Blog,有需要者请先阅读完以上再阅读今天的Blog. 可能今天的有点乱,好好理理,认真看完相信你会懂得 分割线 第二天 引子:昨天我们简单讲了讲图的概念 ...
- 百万年薪python之路 -- 文件操作
1.文件操作: f = open("zcy.txt" , mode="r" , encoding="UTF-8") open() 打开 第一 ...
- QButtonGroup 的使用
1.3以后尽量手写,因为没有现在的控件了 2. // lyy : 2016/8/26 12:17:41 说明:存放radioButton QButtonGroup *buttonGroup; // l ...
- Azure DevOps 替换 appsettings 解决方案
之前发布了 <.Net Core DevOps -免费用Azure四步实现自动化发布(CI/CD)>之后,有很多朋友私信我说如何替换 appsettings 里面的 ConnectionS ...