hdfs、yarn集成ranger
一、安装hdfs插件
从源码安装ranger的服务器上拷贝hdfs的插件到你需要安装的地方
1、解压安装
# tar zxvf ranger-2.1.0-hdfs-plugin.tar.gz -C /data1/hadoop
2、修改插件配置文件,如下
# cd /data1/hadoop/ranger-2.1.0-SNAPSHOT-hdfs-plugin/
修改install.properties文件
主要修改以下几个参数:
POLICY_MGR_URL= http://192.168.4.50:6080 #policy地址,也就是ranger-admin地址
REPOSITORY_NAME=hadoopdev #服务名字,在ranger-admin前台创建的时候,需要与这个参数值一样。
XAAUDIT.SOLR.ENABLE=true #开启审计日志
XAAUDIT.SOLR.URL=http://192.168.4.50:6083/solr/ranger_audits #solr地址
CUSTOM_USER=hduser #定义插件用户,我猜这个值是启动集群的用户
CUSTOM_GROUP=hduser
3、修改hdfs配置文件
# vim hdfs-site.xml
添加如下配置:
<property>
<name>dfs.namenode.inode.attributes.provider.class</name>
<value>org.apache.ranger.authorization.hadoop.RangerHdfsAuthorizer</value>
</property>
<property>
<name>dfs.permissions</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions.ContentSummary.subAccess</name>
<value>true</value>
</property>
4、启动插件
# sudo ./enable-hdfs-plugin.sh (需要root权限)
二、安装yarn插件
1、解压安装
# tar zxvf ranger-2.0.0-yarn-plugin.tar.gz -C /data1/hadoop
2、修改配置文件install.properties
修改如下属性:
POLICY_MGR_URL=http://192.168.4.50:6080
REPOSITORY_NAME=yarndev
XAAUDIT.SOLR.ENABLE=true
XAAUDIT.SOLR.URL=http://192.168.4.50:6083/solr/ranger_audits
CUSTOM_USER=hduser
CUSTOM_GROUP=hduser
3、修改yarn-site.xml配置文件
添加如下属性:
<property>
<name>yarn.acl.enable</name>
<value>true</value>
</property>
<property>
<name>yarn.authorization-provider</name>
<value>org.apache.ranger.authorization.yarn.authorizer.RangerYarnAuthorizer</value>
</property>
4、启动yarn插件
# ./enable-yarn-plugin.sh
# 重启集群
三、前台配置
1、hdfs配置
(1) 登录:http/192.168.4.50:6080
(1) 添加服务

点击加号添加服务
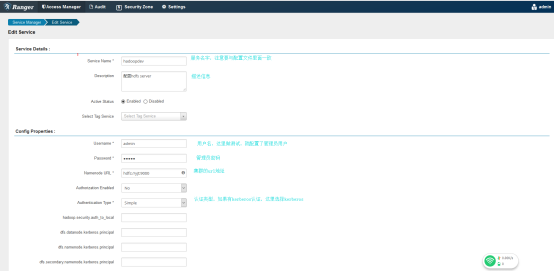
点击测试
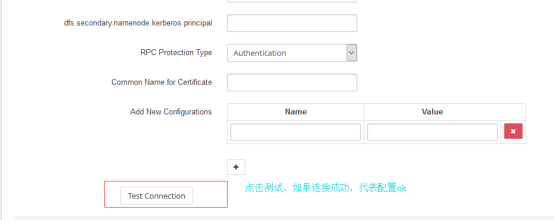

配置完了不要忘记点击保存。
配置完在前台界面如下:

(1) 配置策略
点击hadoopdev进行策略的配置

默认已经有两个策略,这里点击右上角进行策略的添加
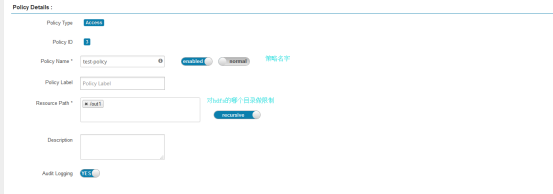

保存。
(1) 测试yjt这个用户是否还有对/out1这个目录有权限。

分析:
从上述可以看到,对于这个目录只要没有对用户或者组加决绝的ACL,正常是可以读取的,但是上述我们对yjt这个用户对/out1这个目录进行了策略控制(拒绝访问)的限制,可以看到,目前这个用户对于该目录没有权限读取了,说明配置成功。
2、yarn配置
(1) 添加服务
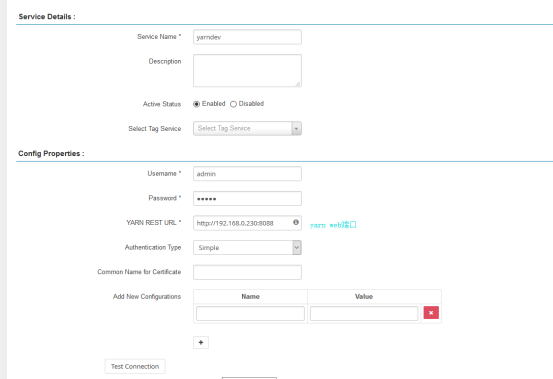
配置完可以进行测试连接,看配置是否ok
(1) 添加策略
对yarn的限制,主要是对于用户对队列的访问,以及任务提交限制
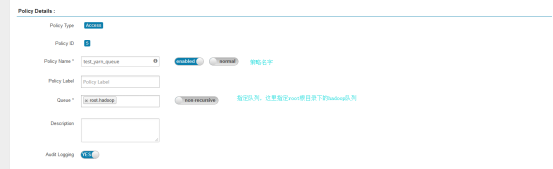
添加权限控制

(1) 测试yjt这个用户是否可以提交任务

从上可以看出,yjt这个用户,不允许提交任务到hadoop队列。
hdfs、yarn集成ranger的更多相关文章
- 2.安装hdfs yarn
下载hadoop压缩包设置hadoop环境变量设置hdfs环境变量设置yarn环境变量设置mapreduce环境变量修改hadoop配置设置core-site.xml设置hdfs-site.xml设置 ...
- Hue联合(hdfs yarn hive) 后续......................
1.启动hdfs,yarn start-all.sh 2.启动hive $ bin/hive $ bin/hive --service metastore & $ bin/hive --ser ...
- hdfs、yarn集成kerberos
1.kdc创建principal 1.1.创建认证用户 登陆到kdc服务器,使用root或者可以使用root权限的普通用户操作: # kadmin.local -q “addprinc -randke ...
- Hadoop HDFS, YARN ,MAPREDUCE,MAPREDUCE ON YARN
HDFS 系统架构图 NameNode 是主节点,存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间,副本数,文件权限),以及每个文件的块列表和块所在的DataNode等.NameNode将 ...
- hadoop/hdfs/yarn 详细命令搬运
转载自文章 http://www.cnblogs.com/davidwang456/p/5074108.html 安装完hadoop后,在hadoop的bin目录下有一系列命令: container- ...
- centos7 hdfs yarn spark 搭建笔记
1.搭建3台虚拟机 2.建立账户及信任关系 3.安装java wget jdk-xxx rpm -i jdk-xxx 4.添加环境变量(全部) export JAVA_HOME=/usr/java/j ...
- Hadoop源代码点滴-系统结构(HDFS+YARN)
Hadoop建立起HDFS和YARN两个字系统,前者是文件系统,管数据存储:后者是计算框架,管数据处理. 如果只有HDFS而没有YARN,那么Hadoop集群可以被用作容错哦的文件服务器,别的就没有什 ...
- hadoop集群的各部分一般都会使用到多个端口,有些是daemon之间进行交互之用,有些是用于RPC访问以及HTTP访问。而随着hadoop周边组件的增多,完全记不住哪个端口对应哪个应用,特收集记录如此,以便查询。这里包含我们使用到的组件:HDFS, YARN, Hbase, Hive, ZooKeeper:
组件 节点 默认端口 配置 用途说明 HDFS DataNode 50010 dfs.datanode.address datanode服务端口,用于数据传输 HDFS DataNode 50075 ...
- kerberos系列之hdfs&yarn认证配置
一.安装hadoop 1.解压安装包重命名安装目录 [root@cluster2_host1 data]# tar -zxvf hadoop-2.7.1.tar.gz -C /usr/local/ [ ...
随机推荐
- 分页工具类PageResult
1.工具类 public class PageResult implements Serializable { private Long total;//总记录数 private List rows; ...
- mvc和mvvm模式
一. Mvvm定义 MVVM是Model-View-ViewModel的简写.即模型-视图-视图模型.[模型]指的是后端传递的数据.[视图]指的是所看到的页面.[视图模型]mvvm模式的核心,它是连接 ...
- 代码实现排列组合【Java】
一.代码实现 package zhen; import java.util.Arrays; public class Arrangement { /** * 计算阶乘数,即n! = n * (n-1) ...
- E2E测试工具之--01 Cypress 上手使用
The web has evolved. Finally, testing has too. 1. 简介 cypress 最近很火的e2e(即end to end(端到端))测试框架,它基于node ...
- Linux 运维入门到跑路书单推荐
一.基础入门 <鸟哥的Linux私房菜基础学习篇>:最具知名度的Linux入门书<鸟哥的Linux私房菜基础学习篇>,全面而详细地介绍了Linux操作系统. https://b ...
- Linux命令——parted
参考:8 Linux ‘Parted’ Commands to Create, Resize and Rescue Disk Partitions 简介 parted是磁盘分区操作工具,支持多种磁盘分 ...
- Multi-Task Feature Learning for Knowledge Graph Enhanced Recommendation(知识图谱)
知识图谱(Knowledge Graph,KG)可以理解成一个知识库,用来存储实体与实体之间的关系.知识图谱可以为机器学习算法提供更多的信息,帮助模型更好地完成任务. 在推荐算法中融入电影的知识图谱, ...
- jdbc.DataSourceProperties$DataSourceBeanCreationException: Failed to determine a suitable driver class
java.lang.IllegalStateException: Failed to load ApplicationContext at org.springframework.test.conte ...
- python开发笔记-类
类的基本概念: 问题空间:问题空间是问题解决者对一个问题所达到的全部认识状态,它是由问题解决者利用问题所包含的信息和已贮存的信息主动的地构成的. 初始状态:一开始时的不完全的信息或令人不满意的状况: ...
- JQuery系列(4) - AJAX方法
jQuery对象上面还定义了Ajax方法($.ajax()),用来处理Ajax操作.调用该方法后,浏览器就会向服务器发出一个HTTP请求. $.ajax方法 $.ajax()的用法主要有两种. $.a ...