内存模型学习-- Container Executor task之间的关系
(分割线前的都是废话)
java8内存模型:
http://www.cnblogs.com/paddix/p/5309550.html
http://www.cnblogs.com/dingyingsi/p/3760447.html
帖子里提到
5、方法区:
方法区也是所有线程共享。主要用于存储类的信息、常量池、方法数据、方法代码等。
方法区逻辑上属于堆的一部分,但是为了与堆进行区分,通常又叫“非堆”。
1.7和1.8后这个方法区 没有了,被原空间取代了
不过元空间与永久代之间最大的区别在于:
元空间并不在虚拟机中,而是使用本地内存。因此,默认情况下,元空间的大小仅受本地内存限制,但可以通过以下参数来指定元空间的大小:
--------------分割线---------------------------------------------------------------------------------
那么这些jvm在yarn 和spark的内存模型上是怎么工作的?
其实我是想知道:
spark on yarn下
一个yarn的Container 可以包含几个spark Executor?
还是一个Executor 下可以有多个Container ?
是一个Container 起了一个jvm,在这个jvm下执行多个task?
一篇帖子spark架构中提到
传送门: http://www.cnblogs.com/gaoxing/p/5041806.html
任何Spark的进程都是一个JVM进程
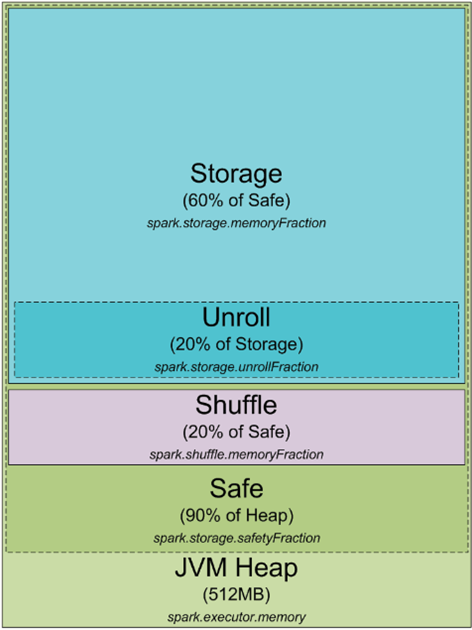

把其中一部分摘出来:
1.当运行在yarn集群上时,Yarn的ResourceMananger用来管理集群资源,集群上每个节点上的NodeManager用来管控所在节点的资源,从yarn的角度来看,每个节点看做可分配的资源池,当向ResourceManager请求资源时,它返回一些NodeManager信息,这些NodeManager将会提供execution container给你,每个execution container就是满足请求的堆大小的JVM进程,JVM进程的位置是由ResourceMananger管理的,不能自己控制,如果一个节点有64GB的内存被yarn管理(通过yarn.nodemanager.resource.memory-mb配置),当请求10个4G内存的executors时,这些executors可能运行在同一个节点上。
2.当在集群上执行应用时,job会被切分成stages,每个stage切分成task,每个task单独调度,可以把executor的jvm进程看做task执行池,每个executor有 spark.executor.cores / spark.task.cpus execution 个执行槽
3.task基本上就是spark的一个工作单元,作为exector的jvm进程中的一个线程执行,这也是为什么spark的job启动时间快的原因,在jvm中启动一个线程比启动一个单独的jvm进程块(在hadoop中执行mapreduce应用会启动多个jvm进程)
总结:所以就是一个container对应一个JVM进程(也就是一个executor)
具体的每个节点下container和executor内存分配看下面的帖子
http://www.tuicool.com/articles/YVFVRf3
内存模型学习-- Container Executor task之间的关系的更多相关文章
- storm中worker、executor、task之间的关系
这里做一些补充: worker是一个进程,由supervisor启动,并只负责处理一个topology,所以不会同时处理多个topology. executor是一个线程,由worker启动,是运行t ...
- Storm概念学习系列之Worker、Task、Executor三者之间的关系
不多说,直接上干货! Worker.Task.Executor三者之间的关系 Storm集群中的一个物理节点启动一个或者多个Worker进程,集群的Topology都是通过这些Worker进程运行的. ...
- C++11并发内存模型学习
C++11标准已发布多年,编译器支持也逐渐完善,例如ms平台上从vc2008 tr1到vc2013.新标准对C++改进体现在三方面:1.语言特性(auto,右值,lambda,foreach):2.标 ...
- Java内存模型学习笔记
Java内存模型(JMM):描述了java程序中各种变量(线程共享变量)的范根规则,以及在JVM中将变量存储到内存和从内存中读取出变量这样的底层细节.共享变量就是指一个线程中的变量在其他线程中也是可见 ...
- java内存模型学习
根据 JVM 规范,JVM 内存共分为虚拟机栈.堆.方法区.程序计数器.本地方法栈五个部分. 虚拟机的内存模型分为两部分:一部分是线程共享的,包括 Java 堆和方法区:另一部分是线程私有的,包括虚拟 ...
- java 内存模型 ——学习笔记
一.Java 内存模型 java内存模型把 Java 虚拟机内部划分为线程栈和堆 下面这张图演示了调用栈和本地变量存放在线程栈上,对象存放在堆上. ==>> 一个局部变量可能是 ...
- Java内存模型学习笔记(一)—— 基础
1.并发编程模型的分类 在并发编程中,我们需要处理两个关键的问题:1.线程间如何通信,2.线程间如何同步.通信是指线程之间以何种机制来交换信息,同步是指程序用于不同线程之间操作发生相对顺序的机制. 在 ...
- Storm-源码分析- Component ,Executor ,Task之间关系
Component包含Executor(threads)的个数 在StormBase中的num-executors, 这对应于你写topology代码时, 为每个component指定的并发数(通过s ...
- Java 内存模型学习笔记
1.Java类 public class Math { public static final Integer CONSTANT = 666; public int math(){ int a = 1 ...
随机推荐
- 『Tree nesting 树形状压dp 最小表示法』
Tree nesting (CF762F) Description 有两个树 S.T,问 S 中有多少个互不相同的连通子图与 T 同构.由于答案 可能会很大,请输出答案模 1000000007 后的值 ...
- Java学习:Set接口与HashSet集合存储数据的结构(哈希表)
Set接口 java.util.Set接口 extends Collection接口 Set接口的特点: 不允许存储重复的元素 没有索引,没有带索引的方法,也不能使用普通的for循环遍历 java.u ...
- ML学习笔记之TF-IDF原理及使用
0x00 什么是TF-IDF TF-IDF(Term Frequency-Inverse Document Frequency, 词频-逆文件频率). # 是一种用于资讯检索与资讯探勘的常用加权技术. ...
- C# Mysql数据库备份、还原(MVC)
一.准备工作 1.电脑上要安装上mysql,并且已经配置好了环境变量. 二.公共代码 1.配置文件(该节点只是为备份.还原使用,数据库连接字符串有另外的节点) <connectionString ...
- Git 管理版本/回退
参考链接:https://www.liaoxuefeng.com/wiki/896043488029600/896954074659008 Git status命令可以让我们时刻掌握仓库当前的状态,比 ...
- JS调用栈的一些总结
原文地址 调用栈 调用栈是解释器追踪函数执行流的一种机制.当执行环境中调用了多个函数函数时,通过这种机制,我们能够追踪到哪个函数正在执行,执行的函数体中又调用了哪个函数. 我们知道JavaScript ...
- 虚拟机-VMware小结
1.网卡的3种模式 桥接模式:虚拟机=物理机器,连接物理网卡,虚拟ip设置物理网卡的网段和网管.可上网. NAT模式:虚拟机把物理机器当做路由器,虚拟ip网段ip自动获取.可上网. https://w ...
- python json dumps与loads
json.dumps() 是将一个Python数据结构转换为一个JSON编码的字符串 json.loads() 是将一个JSON编码的字符串转换为一个Python数据结构 一般要求当要字符串通过l ...
- Django 之 rest_framework 分页器使用
Django rest_framework 之分页器使用以及其源码分析 三种分页方式: 常规分页 -->PageNumberPagination 偏移分页 -->LimitOffsetPa ...
- linux磁盘空间满了 但是没有大文件
很常见的一个问题 linux磁盘空间满了 但是没有大文件 解决思路: 1.用df 检查发现/根目录可用空间为0 [root@/]#df -h 2.用du检查发现各目录占用的空间都很少,有约3G的空间莫 ...