NiFi使用总结 一 hive到hive的PutHiveStreaming processor和SelectHiveQL
我说实话,NiFi的坑真的挺多的。。。
1、PutHiveStreaming processor的使用
具体配置可参考:https://community.hortonworks.com/articles/88309/using-puthivestreaming-processor-in-nifi.html
该控制器配置需要hive启用事物;且目前只支持orc格式,且建表需要分桶,开启事务等,建表示例如下:
create table test_trancaction
(user_id Int,name String)
clustered by (user_id) into 3 buckets
stored as orc TBLPROPERTIES ('transactional'='true');
hive的事物配置,hive-site.xml配置添加:
<!--start for trancaction --> <property>
<name>hive.support.concurrency</name>
<value>true</value>
</property> <property>
<name>hive.enforce.bucketing</name>
<value>true</value>
</property> <property>
<name>hive.exec.dynamic.partition.mode</name>
<value>nonstrict</value>
</property> <property>
<name>hive.txn.manager</name>
<value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value>
</property> <property>
<name>hive.compactor.initiator.on</name>
<value>true</value>
</property> <property>
<name>hive.compactor.worker.threads</name>
<value>1</value>
</property>
hive的事物性配置、验证参考:https://my.oschina.net/wangjiankui/blog/711942
具体配置:
PutHiveStreaming
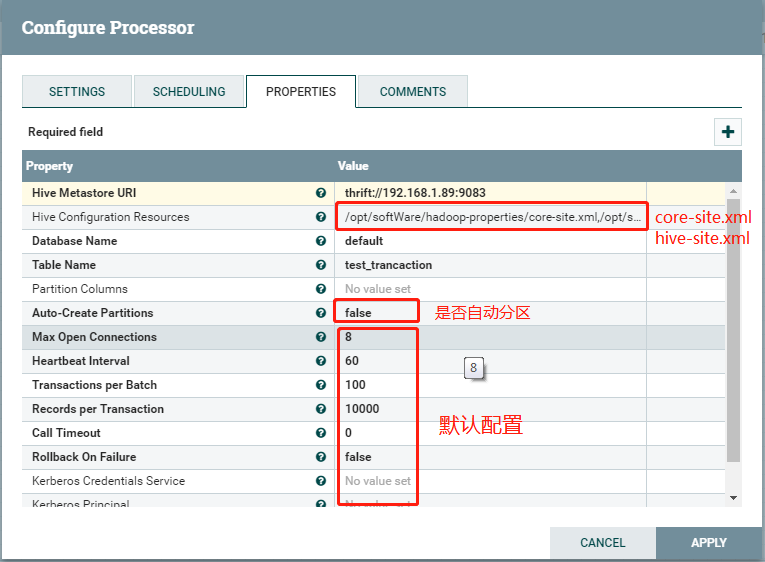
SelectHiveQL:
双击,进入config配置:
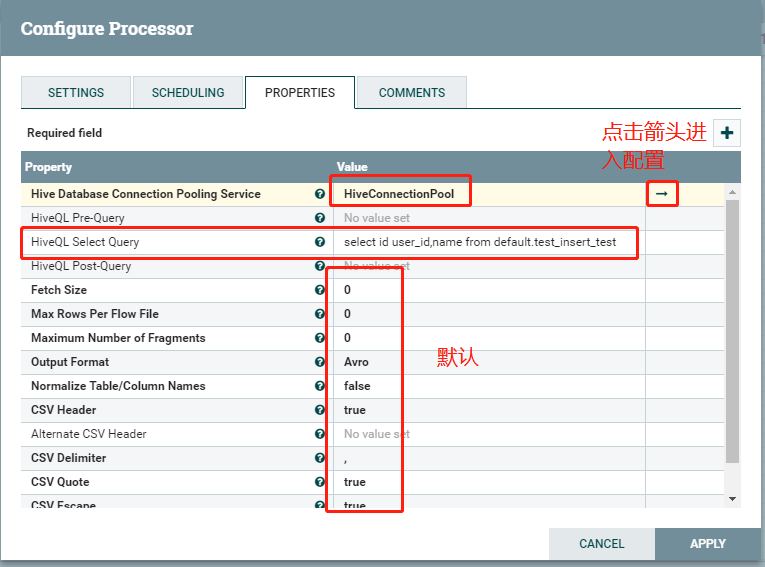
HiveConnectionPool配置:

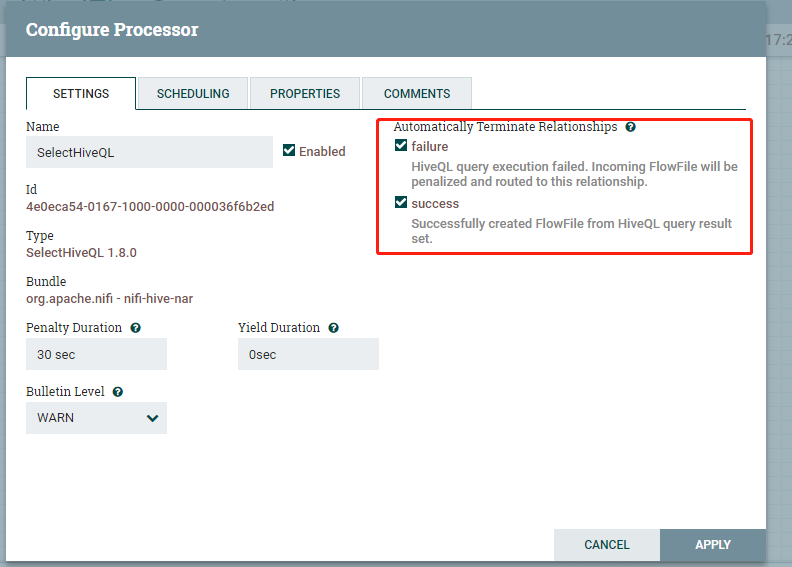
勾选自动终止关系类型:可以都选上
选择调度策略:
有三种,常用的有time driven,CRON driven
简单测试使用Run Schedule不要用0秒,不然会一直不停的在写入数据。。。
有关调度策略下篇在做具体说明

运行一下看看:
源数据:
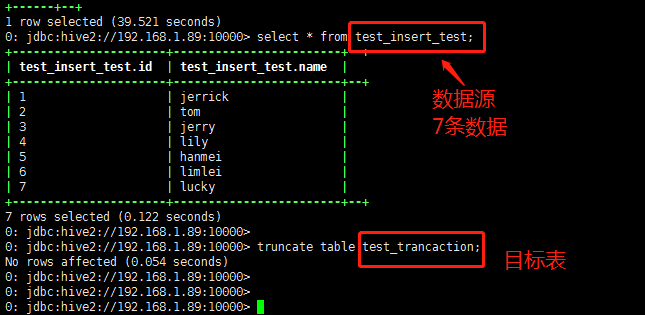
配置好之后右键点击start
过一分钟左右查看插入数据:
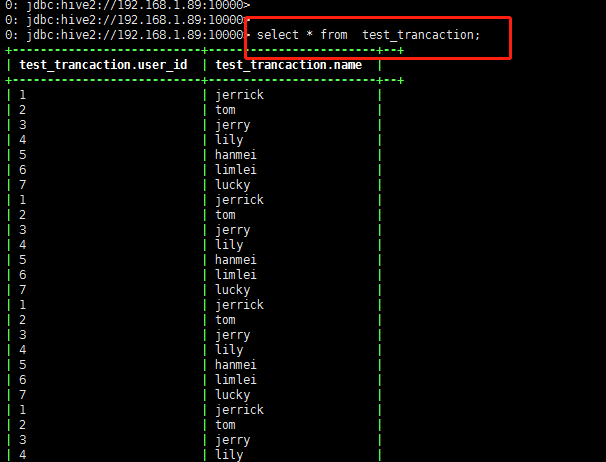
条数有可能不止14条,后续再研究调度的程序设置;
到此为止简单实现了hive-hive的配置
NiFi使用总结 一 hive到hive的PutHiveStreaming processor和SelectHiveQL的更多相关文章
- 【hive】——Hive四种数据导入方式
Hive的几种常见的数据导入方式这里介绍四种:(1).从本地文件系统中导入数据到Hive表:(2).从HDFS上导入数据到Hive表:(3).从别的表中查询出相应的数据并导入到Hive表中:(4).在 ...
- ubuntu下搭建hive(包括hive的web接口)记录
Hive版本 0.12.0(独立模式) Hadoop版本 1.12.1 Ubuntu 版本 12.10 今天试着搭建了hive,差点迷失在了网上各种资料中,现在把我的经验分享给大家,亲手实践过,但未必 ...
- [Hive - LanguageManual] Hive Concurrency Model (待)
Hive Concurrency Model Hive Concurrency Model Use Cases Turn Off Concurrency Debugging Configuration ...
- Shell脚本运行hive语句 | hive以日期建立分区表 | linux schedule程序 | sed替换文件字符串 | shell推断hdfs文件文件夹是否存在
#!/bin/bash source /etc/profile; ################################################## # Author: ouyang ...
- Hive记录-Hive介绍(转载)
1.Hive是什么? Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的 SQL 查询功能,将类 SQL 语句转换为 MapReduce 任务执 ...
- Hive记录-Hive on Spark环境部署
1.hive执行引擎 Hive默认使用MapReduce作为执行引擎,即Hive on mr.实际上,Hive还可以使用Tez和Spark作为其执行引擎,分别为Hive on Tez和Hive on ...
- Ambari配置Hive,Hive的使用
mysql安装,hive环境的搭建 ambari部署hadoop 博客大牛:董的博客 ambari使用 ambari官方文档 hadoop 2.0 详细配置教程 使用Ambari快速部署Hadoop大 ...
- Hive之 hive的三种使用方式(CLI、HWI、Thrift)
Hive有三种使用方式——CLI命令行,HWI(hie web interface)浏览器 以及 Thrift客户端连接方式. 1.hive 命令行模式 直接输入/hive/bin/hive的执行程 ...
- Hive之 hive架构
Hive架构图 主要分为以下几个部分: 用户接口,包括 命令行CLI,Client,Web界面WUI,JDBC/ODBC接口等 中间件:包括thrift接口和JDBC/ODBC的服务端,用于整合Hiv ...
随机推荐
- Deepin (Linux Debian)使用日记
(现在Deepin使用了debian的stable源,如果求新,推荐使用排行榜前三的Linux发行版——> Manjaro) 修复开启混合显卡驱动后,屏幕泛白偏灰问题“: https://blo ...
- 修改Windows中文用户名为英文(更全面的方法)
网上方法很多,但是大多不全面. 我的建议是 1,新建/切换管理员账号 net user administrator /active:yes 然后点击桌面,使用Alt+F4组合键 注销中文用户名账号,并 ...
- 关于c语言的逻辑短路规则
原来的代码是 if (temp == 3 && (a % b != 0 || b == 0 )){ printf("go"); } dev-c 报错: progra ...
- Spring Boot 知识笔记(定时任务与异步)
一.定时任务 1.启动类里面增加注入 @SpringBootApplication //@SpringBootApplication = @Configuration+@EnableAutoConfi ...
- 三、hexo+github搭建个人博客的主题配置
更换博客主题 主题可参考:https://hexo.io/themes/ hexo默认主题:Landscape 示例主题:Next 下载Next主题 进入Blog所在目录,输入下载命令 #进入Blog ...
- 【03】Jenkins:SonarQube
写在前面的话 SonarQube 这个服务有些人熟悉,有些人陌生.对于我们这样的运维人员,我们需要了解的是,SonarQube 是一个代码质量管理平台,懂得怎么安装配置,这其实就差不多足够了.我们在 ...
- [原创]Spring-Security-Oauth2.0浏览器端的登录项目分享
1.简介 CitySecurity项目为正式上线项目做得一个Demo,这里主要介绍浏览器端的登录.本项目使用了SpringSecurity实现表单安全登录.图形验证的校验.记住我时长控制机制.第三 ...
- [转] console.log的高级用法
//基本用法 console.log('最常见用法\n换行'); console.error('输出错误信息 会以红色显示'); console.warn('打印警告信息 会以黄色显示'); cons ...
- kafka 解密:破除单机topic数多性能下降魔咒
https://bbs.huaweicloud.com/blogs/112956 版权归PUMA项目组所有,转载请声明,多谢. kakfa大规模集群能力在前面已给大家分享过,kafka作为消息总线,在 ...
- asp.net 路由注册
webapi的路由注册 mvc的路由注册 urlRoutingModule路由