33、shuffle性能优化
一、shuffle性能优化
1、没有开启consolidation机制的性能低下的原理剖析
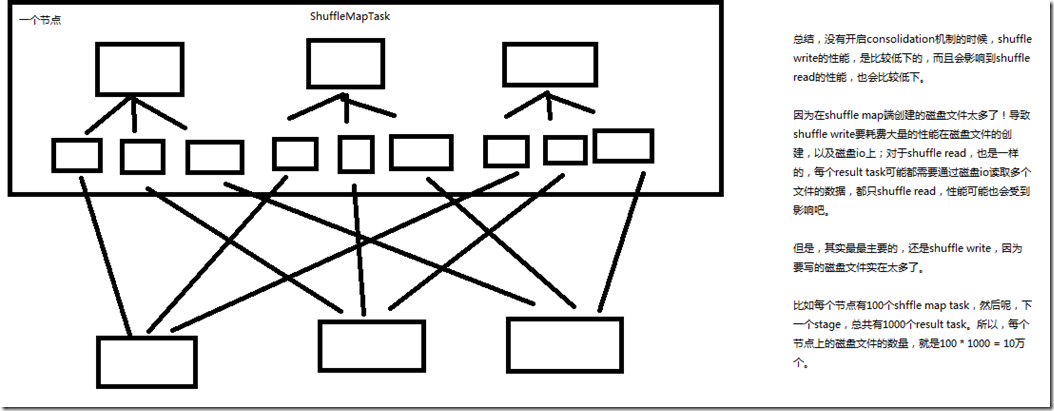
2、开启consolidation机制之后对磁盘io性能的提升的原理
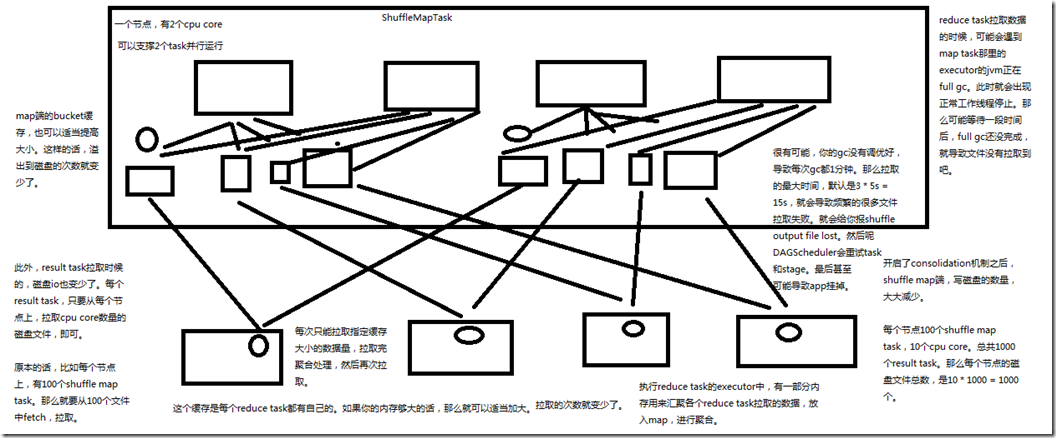
spark.shuffle.consolidateFiles:是否开启shuffle block file的合并,默认为false; 总结,开启了consolidation机制之后,shuffle map端,写磁盘的数量,大大减少; 比如节点100个shuffle map task ,10个cpu core,总共1000个result task,那么每个节点的磁盘文件总数,是10 * 1000 = 1万个; 此外,result task拉取的时候,磁盘io也变少了,每个result task,只要从每个节点上,拉取cpu core数量的磁盘文件即可; 比如,每个节点上,有100个shuffle map task,那么就要从100个文件中fetch,拉取,现在只需要从10个文件中fetch,拉取; map端的bucket缓存,也可以适当提高大小,这样,溢出到磁盘的次数就变少了; spark.shuffle.file.buffer:map task的写磁盘缓存,默认32k; 每次只能拉取指定缓存大小的数据量,拉取完聚合处理,然后再次拉取,这个缓存是每个reduce task都有自己的,如果内存够大的话,那么可以适当加大,
那么拉取的次数就变少了,spark.reducer.maxSizeInFlight:reduce task的拉取缓存,默认48m; 执行reduce task的executor中,有一部分内存用来汇聚各个reduce task 拉取的数据,放入map,进行聚合,spark.shuffle.memoryFraction:用于reduce端聚合的内存比例,
默认0.2,超过比例就会溢出到磁盘上; reduce task 拉取数据的时候,可能会遇到map task哪里的executor的jvm正在full gc,此时就会出现正常工作线程停止,那么可能等待一段时间后,full gc还没完成,
就导致文件没有拉取到,spark.shuffle.io.maxRetries:拉取失败的最大重试次数,默认3次; 很有可能,gc没有调优好,导致每次gc都1分钟,那么拉取的最大时间,默认是3 * 5 = 15s,就会导致频繁的很多文件拉取失败,就会给你报shuffle output file lost,
然后,DAGScheduler会重试task和stage,最后甚至可能导致Application挂掉,spark.shuffle.io.retryWait:拉取失败的重试间隔,默认5s;
3、调优参数总结
new SparkConf().set("spark.shuffle.consolidateFiles", "true")
spark.shuffle.consolidateFiles:是否开启shuffle block file的合并,默认为false
spark.reducer.maxSizeInFlight:reduce task的拉取缓存,默认48m
spark.shuffle.file.buffer:map task的写磁盘缓存,默认32k
spark.shuffle.io.maxRetries:拉取失败的最大重试次数,默认3次
spark.shuffle.io.retryWait:拉取失败的重试间隔,默认5s
spark.shuffle.memoryFraction:用于reduce端聚合的内存比例,默认0.2,超过比例就会溢出到磁盘上
33、shuffle性能优化的更多相关文章
- Spark记录-Spark性能优化(开发、资源、数据、shuffle)
开发调优篇 原则一:避免创建重复的RDD 通常来说,我们在开发一个Spark作业时,首先是基于某个数据源(比如Hive表或HDFS文件)创建一个初始的RDD:接着对这个RDD执行某个算子操作,然后得到 ...
- Spark性能优化(1)——序列化、内存、并行度、数据存储格式、Shuffle
序列化 背景: 在以下过程中,需要对数据进行序列化: shuffling data时需要通过网络传输数据 RDD序列化到磁盘时 性能优化点: Spark默认的序列化类型是Java序列化.Java序列化 ...
- Spark性能优化——和shuffle搏斗
Spark的性能分析和调优很有意思,今天再写一篇.主要话题是shuffle,当然也牵涉一些其他代码上的小把戏. 以前写过一篇文章,比较了几种不同场景的性能优化,包括portal的性能优化,web se ...
- Spark性能优化指南-高级篇(spark shuffle)
Spark性能优化指南-高级篇(spark shuffle) 非常好的讲解
- 《Spark大数据处理:技术、应用与性能优化 》
基本信息 作者: 高彦杰 丛书名:大数据技术丛书 出版社:机械工业出版社 ISBN:9787111483861 上架时间:2014-11-5 出版日期:2014 年11月 开本:16开 页码:255 ...
- 《Spark大数据处理:技术、应用与性能优化》【PDF】 下载
内容简介 <Spark大数据处理:技术.应用与性能优化>根据最新技术版本,系统.全面.详细讲解Spark的各项功能使用.原理机制.技术细节.应用方法.性能优化,以及BDAS生态系统的相关技 ...
- 《Spark大数据处理:技术、应用与性能优化》【PDF】
内容简介 <Spark大数据处理:技术.应用与性能优化>根据最新技术版本,系统.全面.详细讲解Spark的各项功能使用.原理机制.技术细节.应用方法.性能优化,以及BDAS生态系统的相关技 ...
- 【大数据】Spark性能优化和故障处理
第一章 Spark 性能调优 1.1 常规性能调优 1.1.1 常规性能调优一:最优资源配置 Spark性能调优的第一步,就是为任务分配更多的资源,在一定范围内,增加资源的分配与性能的提升是成正比的, ...
- spark 性能优化 数据倾斜 故障排除
版本:V2.0 第一章 Spark 性能调优 1.1 常规性能调优 1.1.1 常规性能调优一:最优资源配置 Spark性能调优的第一步,就是为任务分配更多的资源,在一定范围 ...
随机推荐
- HTTPDNS
传统 DNS 缺点 1.域名缓存问题 它可以在本地做一个缓存,也就是说,不是每一个请求,它都会去访问权威 DNS 服务器,而是访问过一次就把结果缓存到自己本地,当其他人来问的时候,直接就返回这 ...
- Spring Boot 入门 - 目录
pring Boot 入门 - 进阶篇(3)- 定时任务(@Scheduled) 主要用于定时发送邮件.夜间自动维护等. (1)开启定时任务功能 @Configuration @EnableSched ...
- MSMQ消息加密
证书实现非对称加密/解密的代码如下 //非对称加密密钥 static byte[] RSAEncrypt(byte[] enkey, X509Certificate2 Certificate) { R ...
- ③ Python3.0 数字类型
Python3 的六个标准数据类型中:不可变数据(3 个):Number(数字).String(字符串).Tuple(元组):可变数据(3 个):List(列表).Dictionary(字典).Set ...
- Unity3d与iOS交互开发
一.Unity3d To iOS: 最近要做一个商品和人体模型T台秀相关的功能,要用到Unity3D,搜集了一些资料先保存下来. 1.创建一个C#文件 SdkToIOS.cs 这是调用iOS函数的 ...
- 【转载】 C#使用Math.Abs返回数值的绝对值
在C#的数值运算中,有时候我们需要计算值类型对象的绝对值,此时需要用到C#的数值计算类Math类中的Abs绝对值函数,Math.Abs绝对值函数一共有7个重载类型,支持decimal.double.f ...
- Bootstrap框架 简单使用
目录 Bootstrap框架 简单使用 什么是Bootstrap 下载 Bootstrap 项目结构 Bootstrap 简单使用 表格格式 Bootstrap 按钮颜色 尺寸 Bootstrap框架 ...
- Hibernate hql getHibernateTemplate()常用方法汇总
转自:https://www.iteye.com/blog/zwdsmileface-2191943 getHibernateTemplate()常用方法 一.find(String queryStr ...
- flask-sqlalchemy用法详解
一. 安装 $ pip install flask-sqlalchemy 二. 配置 配置选项列表 : 选项 说明 SQLALCHEMY_DATABASE_URI 用于连接的数据库 URI .例如:s ...
- c# Match类