pandas之数据处理
首先,数据加载
pandas提供了一些用于将表格型数据读取为DataFrame对象的函数,期中read_csv和read_table这两个使用最多。


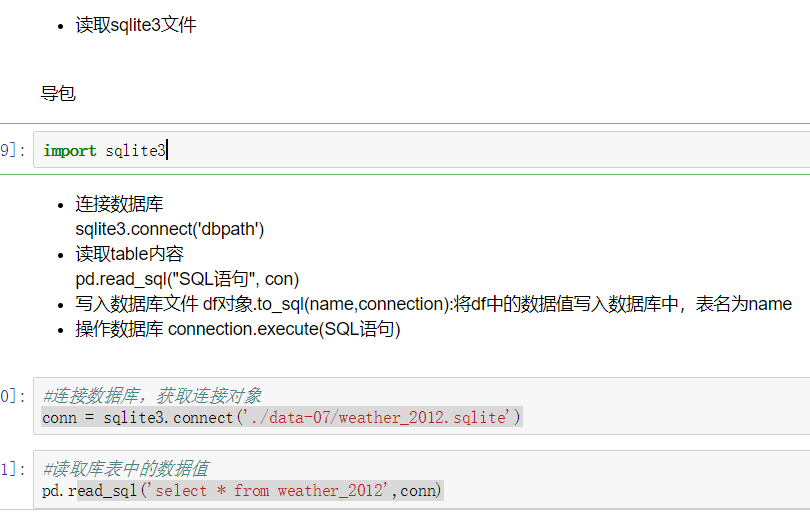
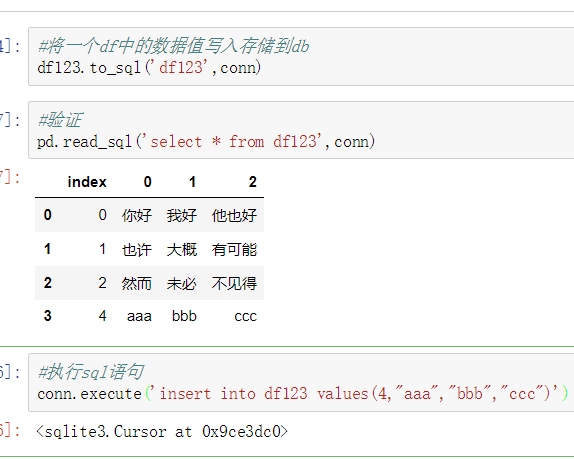
1、删除重复元素
使用duplicated()函数检测重复的行,返回元素为布尔类型的Series对象,每个元素对应一行,如果该行不是第一次出现,则元素为True。
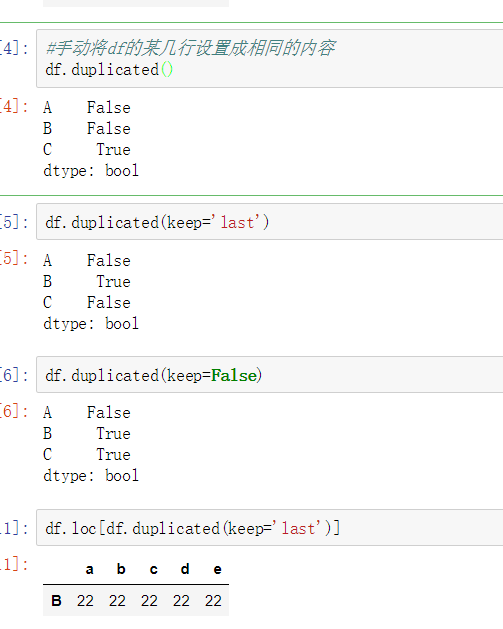
- keep参数:指定保留哪一重复的行数据
- True 重复的行- 创建具有重复元素行的DataFrame
from pandas import Series,DataFrame
import numpy as np
import pandas as pd #创建一个df
np.random.seed(10)
df = DataFrame(data=np.random.randint(0,100,size=(3,5)),index=['A','B','C'],columns=['a','b','c','d','e'])
df
# a b c d e
A 9 15 64 28 89
B 93 29 8 73 0
C 40 36 16 11 54 df.loc['B'] = ['22','22','22','22','22']
df.loc['C'] = ['22','22','22','22','22']
df
# a b c d e
A 9 15 64 28 89
B 22 22 22 22 22
C 22 22 22 22 22
- 使用duplicated查看所有重复元素行
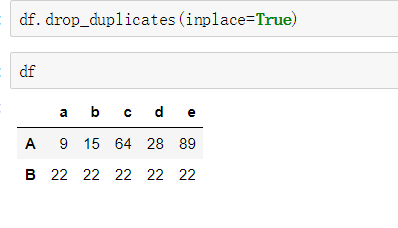
使用drop_duplicates()函数删除重复的行
- drop_duplicates(keep='first/last'/False)
2. 映射:指定替换
1) replace()函数:替换元素
使用replace()函数,对values进行映射操作
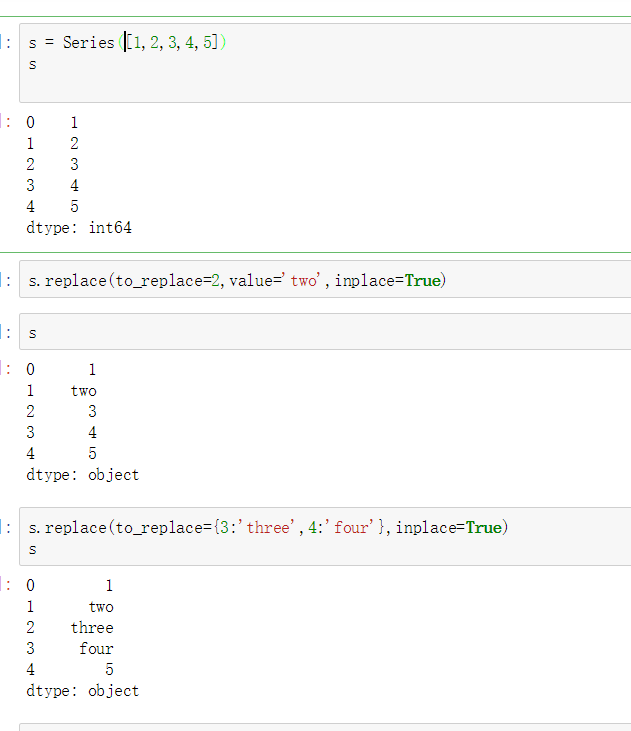
Series替换操作
- 单值替换
- 普通替换
- 字典替换(推荐)
- 多值替换
- 列表替换
- 字典替换(推荐)
- 参数
- to_replace:被替换的元素
单值普通替换
eplace参数说明:
- method:对指定的值使用相邻的值填充替换
- limit:设定填充次数
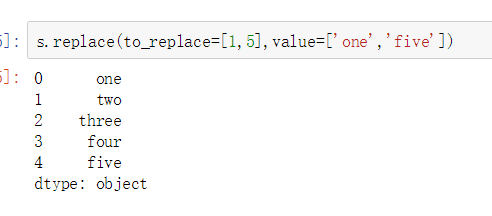
DataFrame替换操作
- 单值替换
- 普通替换: 替换所有符合要求的元素:to_replace=15,value='e'
- 按列指定单值替换: to_replace={列标签:替换值} value='value'
- 多值替换
- 列表替换: to_replace=[] value=[]
- 字典替换(推荐) to_replace={to_replace:value,to_replace:value}
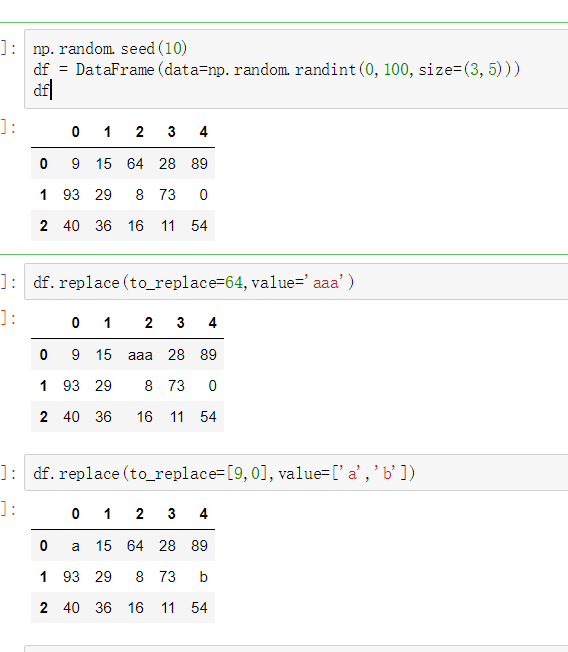

2) map()函数:新建一列 , map函数并不是df的方法,而是series的方法
- map是Series的一个函数
- map()可以映射新一列数据
- map()中可以使用lambd表达式
map()中可以使用方法,可以是自定义的方法
eg:map({to_replace:value})
- 注意 map()中不能使用sum之类的函数,for循环

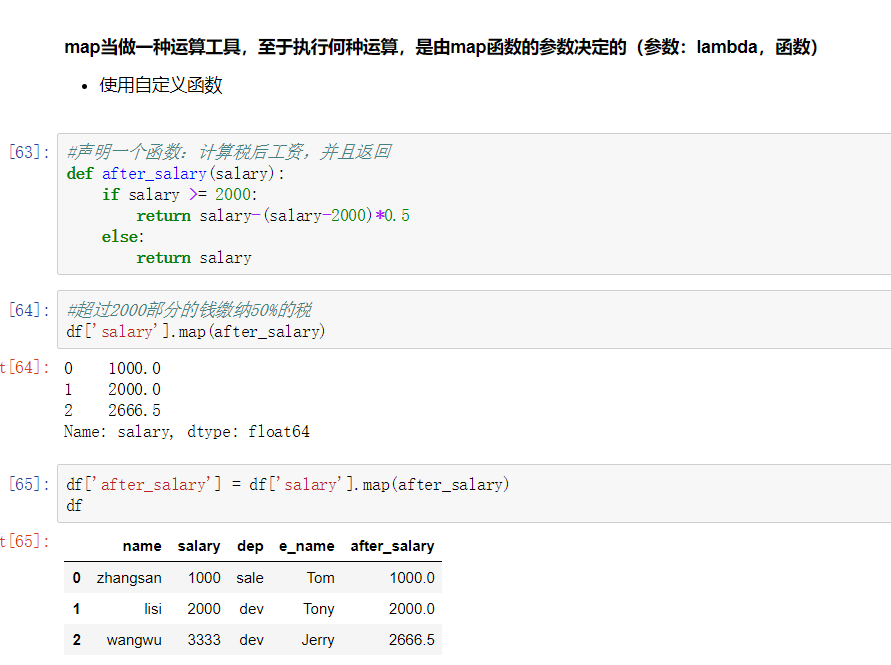
注意:并不是任何形式的函数都可以作为map的参数。只有当一个函数具有一个参数且有返回值,那么该函数才可以作为map的参数。
3. 使用聚合操作对数据异常值检测和过滤
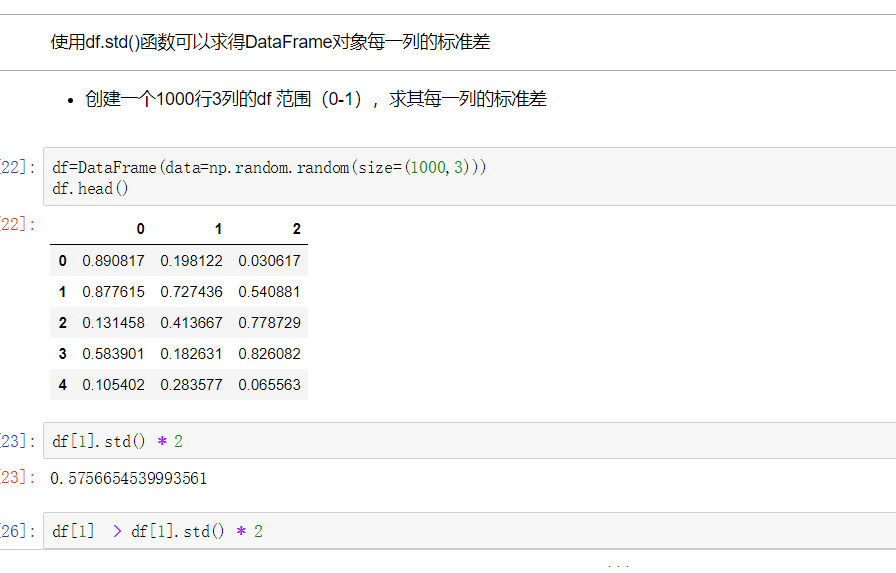

4. 排序
使用.take()函数排序
- take()函数接受一个索引列表,用数字表示,使得df根据列表中索引的顺序进行排序
- eg:df.take([1,3,4,2,5])
可以借助np.random.permutation()函数随机排序

随机抽样
当DataFrame规模足够大时,直接使用np.random.permutation(x)函数,就配合take()函数实现随机抽样
5. 数据分类处理
数据聚合是数据处理的最后一步,通常是要使每一个数组生成一个单一的数值。
数据分类处理:
- 分组:先把数据分为几组
- 用函数处理:为不同组的数据应用不同的函数以转换数据
- 合并:把不同组得到的结果合并起来
数据分类处理的核心:
- groupby()函数
- groups属性查看分组情况
- eg: df.groupby(by='item').groups分组




pandas之数据处理的更多相关文章
- Pandas缺失数据处理
Pandas缺失数据处理 Pandas用np.nan代表缺失数据 reindex() 可以修改 索引,会返回一个数据的副本: df1 = df.reindex(index=dates[0:4], co ...
- pandas | 使用pandas进行数据处理——DataFrame篇
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是pandas数据处理专题的第二篇文章,我们一起来聊聊pandas当中最重要的数据结构--DataFrame. 上一篇文章当中我们介绍了 ...
- Pandas日期数据处理:如何按日期筛选、显示及统计数据
前言 pandas有着强大的日期数据处理功能,本期我们来了解下pandas处理日期数据的一些基本功能,主要包括以下三个方面: 按日期筛选数据 按日期显示数据 按日期统计数据 运行环境为 windows ...
- 5,pandas高级数据处理
1.删除重复元素 使用duplicated()函数检测重复的行,返回元素为布尔类型的Series对象,每个元素对应一行,如果该行不是第一次出现,则元素为True - keep参数:指定保留哪一重复的行 ...
- Python——Pandas 时间序列数据处理
介绍 Pandas 是非常著名的开源数据处理库,我们可以通过它完成对数据集进行快速读取.转换.过滤.分析等一系列操作.同样,Pandas 已经被证明为是非常强大的用于处理时间序列数据的工具.本节将介绍 ...
- pandas | 使用pandas进行数据处理——Series篇
本文始发于个人公众号:TechFlow,原创不易,求个关注 上周我们关于Python中科学计算库Numpy的介绍就结束了,今天我们开始介绍一个新的常用的计算工具库,它就是大名鼎鼎的Pandas. Pa ...
- python使用pandas进行数据处理
pandas数据处理 关注公众号"轻松学编程"了解更多. 以下命令都是在浏览器中输入. cmd命令窗口输入:jupyter notebook 打开浏览器输入网址http://loc ...
- 【python】pandas & matplotlib 数据处理 绘制曲面图
Python matplotlib模块,是扩展的MATLAB的一个绘图工具库,它可以绘制各种图形 建议安装 Anaconda后使用 ,集成了很多第三库,基本满足大家的需求,下载地址,对应选择pytho ...
- Python基于pandas的数据处理(二)
14 抽样 df.sample(10, replace = True) df.sample(3) df.sample(frac = 0.5) # 按比例抽样 df.sample(frac = 10, ...
随机推荐
- what's the psutil模块
what's the psutil模块 psutil 是一个跨平台库,能够轻松实现获取系统运行的进程和系统利用率(包括CPU.内存.磁盘.网络等)信息.它主要用来做系统监控,性能分析,进程管理.它实现 ...
- Operation之过滤操作符
filter 该操作符就是用来过滤掉某些不符合要求的事件 Observable.of(2, 30, 22, 5, 60, 3, 40, 9) .filter{ $0 > 10 } .subscr ...
- 修改Window服务器虚拟内存位置
系统采用的是windows server2008操作系统,硬件部门在分配磁盘的时候C盘只有50G,其中虚拟内存就占用了30G,再除去操作系统占用空间,可用自由支配空间较小,会出现在部分异常情况下C盘占 ...
- RabbitMQ使用及与spring boot整合
1.MQ 消息队列(Message Queue,简称MQ)——应用程序和应用程序之间的通信方法 应用:不同进程Process/线程Thread之间通信 比较流行的中间件: ActiveMQ Rabbi ...
- kubernetes-dashboard获取令牌登陆
前言:kubernetes核心组件服务启动正常 一.在kubernetes-dashboard.yaml父级文件夹下创建account.yaml文件用于访问kubernetes-dashboard,添 ...
- spark 提交任务报错 Yarn application has already ended! It might have been killed or unable to launch application master
1.任务是提交在yarn上的,查看 resourceManager页面 有如下信息 Current usage: 58.4 MB of 1 GB physical memory used; 2.2 G ...
- python教程:用简单的Python编写Web应用程序
python现在已经成为很多程序员关注的编程语言之一,很多程序员也都开始弄python编程,并且很多时候都会用自己的操作来选择,而现在不管是程序员还是少儿编程,都会有python这门课,今天就和大家分 ...
- Label&Button
Button中的bg参数设置按钮背景颜色,fg参数设置字体颜色 pack中的fill参数告诉Packer让QUIT按钮占据剩余的水平空间,而expand参数则引导它填充整个水平可视空间,将按钮拉伸到左 ...
- Go语言【学习】defer和逃逸分析
defer 什么是defer? defer是Go语言的一中用于注册延迟调用的机制,使得函数活语句可以再当前函数执行完毕后执行 为什么需要defer? Go语言提供的语法糖,减少资源泄漏的发生 如何使用 ...
- golang微服务框架go-micro 入门笔记2.1 micro工具之micro api
micro api micro 功能非常强大,本文将详细阐述micro api 命令行的功能 重要的事情说3次 本文全部代码https://idea.techidea8.com/open/idea.s ...