pandas之数据处理
首先,数据加载
pandas提供了一些用于将表格型数据读取为DataFrame对象的函数,期中read_csv和read_table这两个使用最多。


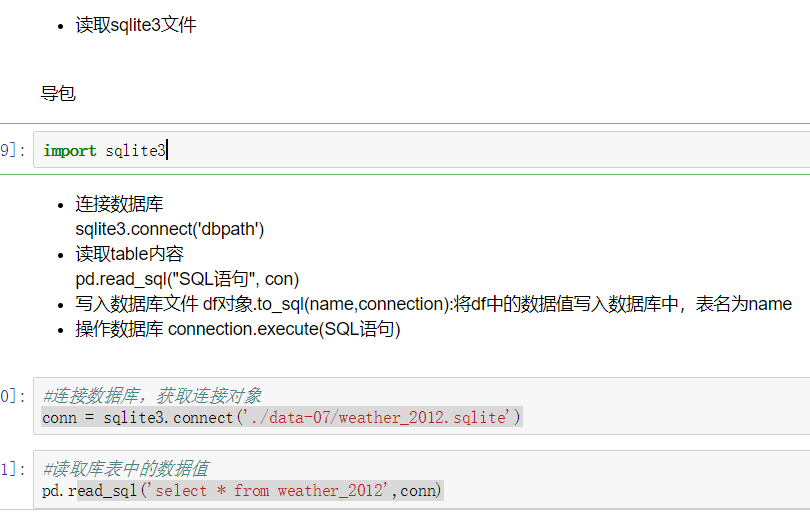
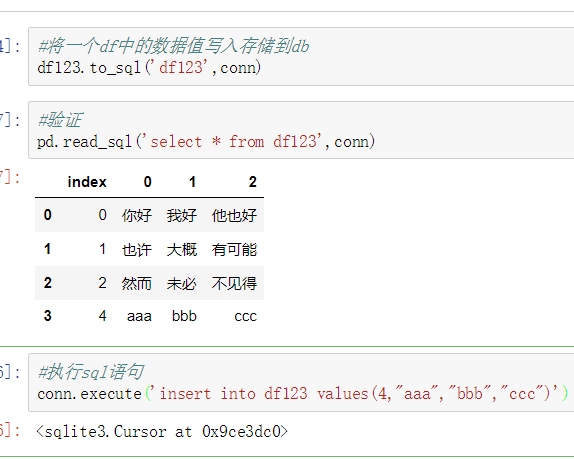
1、删除重复元素
使用duplicated()函数检测重复的行,返回元素为布尔类型的Series对象,每个元素对应一行,如果该行不是第一次出现,则元素为True。
- keep参数:指定保留哪一重复的行数据
- True 重复的行- 创建具有重复元素行的DataFrame
from pandas import Series,DataFrame
import numpy as np
import pandas as pd #创建一个df
np.random.seed(10)
df = DataFrame(data=np.random.randint(0,100,size=(3,5)),index=['A','B','C'],columns=['a','b','c','d','e'])
df
# a b c d e
A 9 15 64 28 89
B 93 29 8 73 0
C 40 36 16 11 54 df.loc['B'] = ['22','22','22','22','22']
df.loc['C'] = ['22','22','22','22','22']
df
# a b c d e
A 9 15 64 28 89
B 22 22 22 22 22
C 22 22 22 22 22
- 使用duplicated查看所有重复元素行
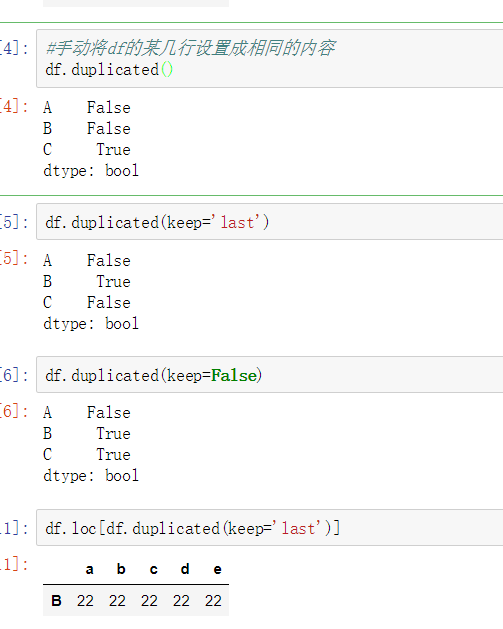
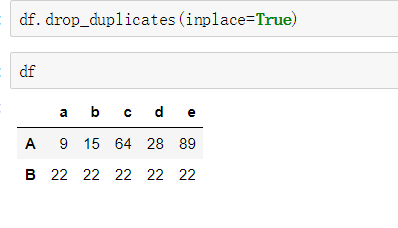
使用drop_duplicates()函数删除重复的行
- drop_duplicates(keep='first/last'/False)
2. 映射:指定替换
1) replace()函数:替换元素
使用replace()函数,对values进行映射操作
Series替换操作
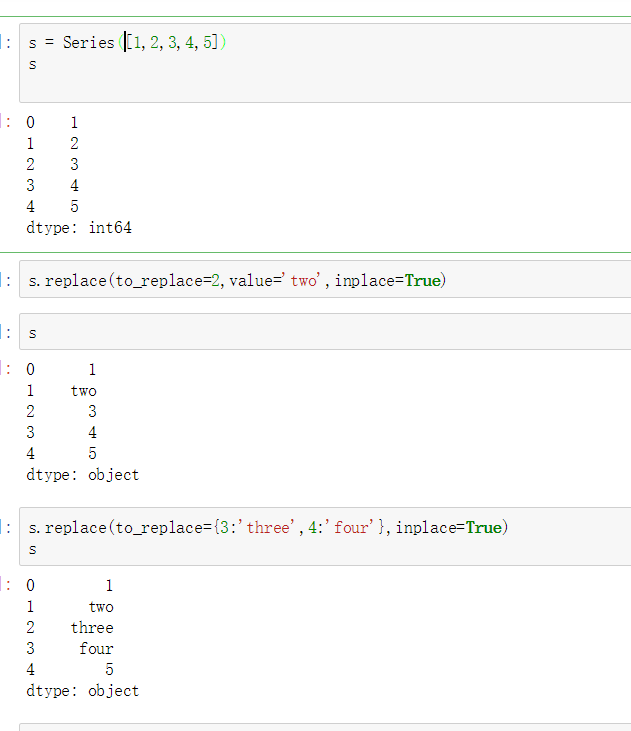
- 单值替换
- 普通替换
- 字典替换(推荐)
- 多值替换
- 列表替换
- 字典替换(推荐)
- 参数
- to_replace:被替换的元素
单值普通替换
eplace参数说明:
- method:对指定的值使用相邻的值填充替换
- limit:设定填充次数
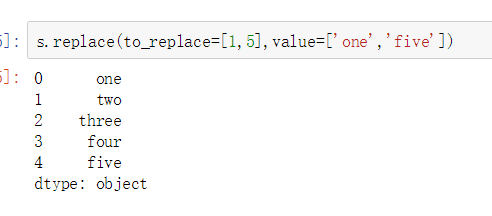
DataFrame替换操作
- 单值替换
- 普通替换: 替换所有符合要求的元素:to_replace=15,value='e'
- 按列指定单值替换: to_replace={列标签:替换值} value='value'
- 多值替换
- 列表替换: to_replace=[] value=[]
- 字典替换(推荐) to_replace={to_replace:value,to_replace:value}
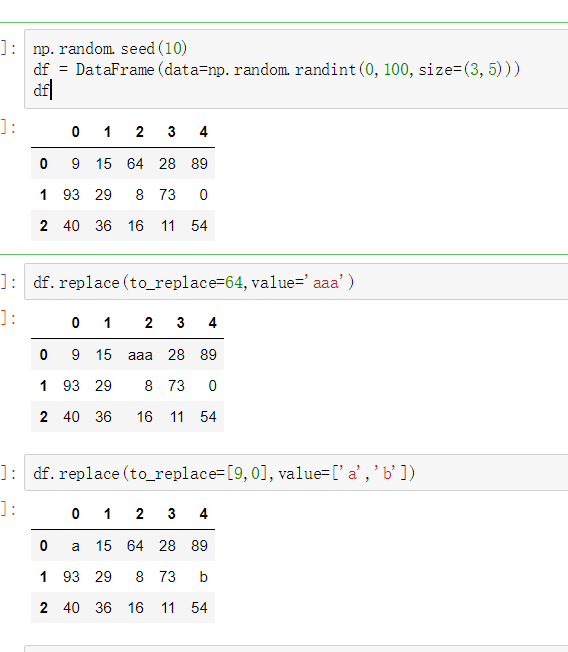

2) map()函数:新建一列 , map函数并不是df的方法,而是series的方法
- map是Series的一个函数
- map()可以映射新一列数据
- map()中可以使用lambd表达式
map()中可以使用方法,可以是自定义的方法
eg:map({to_replace:value})
- 注意 map()中不能使用sum之类的函数,for循环

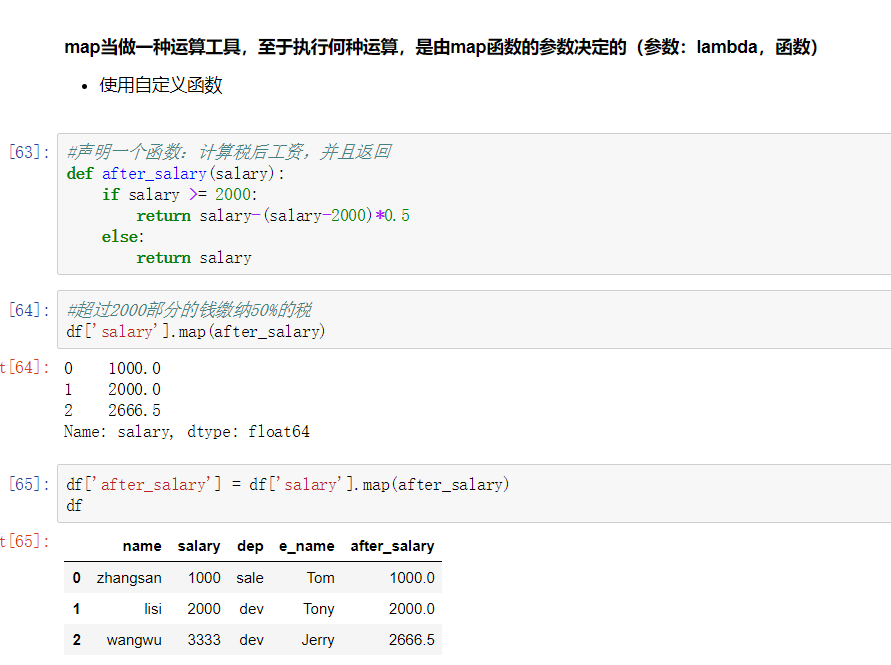
注意:并不是任何形式的函数都可以作为map的参数。只有当一个函数具有一个参数且有返回值,那么该函数才可以作为map的参数。
3. 使用聚合操作对数据异常值检测和过滤
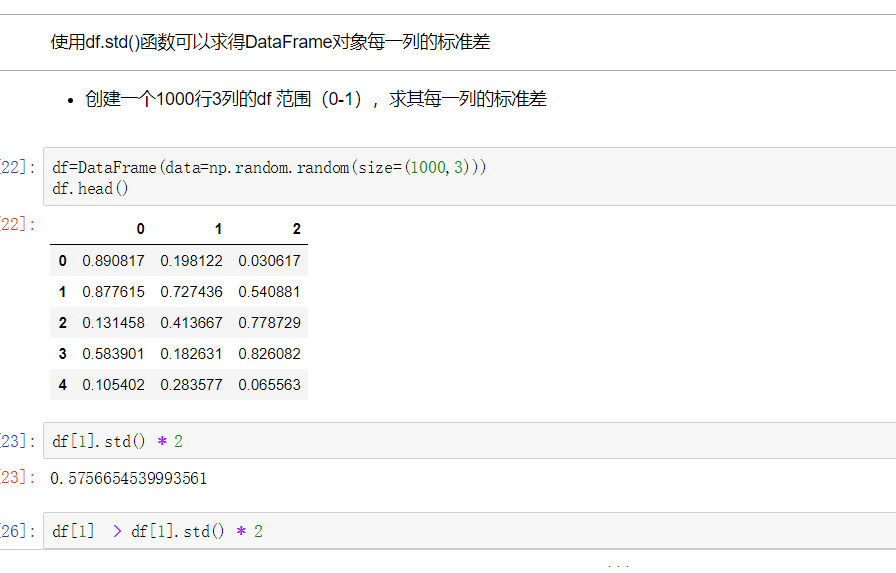

4. 排序
使用.take()函数排序
- take()函数接受一个索引列表,用数字表示,使得df根据列表中索引的顺序进行排序
- eg:df.take([1,3,4,2,5])
可以借助np.random.permutation()函数随机排序

随机抽样
当DataFrame规模足够大时,直接使用np.random.permutation(x)函数,就配合take()函数实现随机抽样
5. 数据分类处理
数据聚合是数据处理的最后一步,通常是要使每一个数组生成一个单一的数值。
数据分类处理:
- 分组:先把数据分为几组
- 用函数处理:为不同组的数据应用不同的函数以转换数据
- 合并:把不同组得到的结果合并起来
数据分类处理的核心:
- groupby()函数
- groups属性查看分组情况
- eg: df.groupby(by='item').groups分组




pandas之数据处理的更多相关文章
- Pandas缺失数据处理
Pandas缺失数据处理 Pandas用np.nan代表缺失数据 reindex() 可以修改 索引,会返回一个数据的副本: df1 = df.reindex(index=dates[0:4], co ...
- pandas | 使用pandas进行数据处理——DataFrame篇
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是pandas数据处理专题的第二篇文章,我们一起来聊聊pandas当中最重要的数据结构--DataFrame. 上一篇文章当中我们介绍了 ...
- Pandas日期数据处理:如何按日期筛选、显示及统计数据
前言 pandas有着强大的日期数据处理功能,本期我们来了解下pandas处理日期数据的一些基本功能,主要包括以下三个方面: 按日期筛选数据 按日期显示数据 按日期统计数据 运行环境为 windows ...
- 5,pandas高级数据处理
1.删除重复元素 使用duplicated()函数检测重复的行,返回元素为布尔类型的Series对象,每个元素对应一行,如果该行不是第一次出现,则元素为True - keep参数:指定保留哪一重复的行 ...
- Python——Pandas 时间序列数据处理
介绍 Pandas 是非常著名的开源数据处理库,我们可以通过它完成对数据集进行快速读取.转换.过滤.分析等一系列操作.同样,Pandas 已经被证明为是非常强大的用于处理时间序列数据的工具.本节将介绍 ...
- pandas | 使用pandas进行数据处理——Series篇
本文始发于个人公众号:TechFlow,原创不易,求个关注 上周我们关于Python中科学计算库Numpy的介绍就结束了,今天我们开始介绍一个新的常用的计算工具库,它就是大名鼎鼎的Pandas. Pa ...
- python使用pandas进行数据处理
pandas数据处理 关注公众号"轻松学编程"了解更多. 以下命令都是在浏览器中输入. cmd命令窗口输入:jupyter notebook 打开浏览器输入网址http://loc ...
- 【python】pandas & matplotlib 数据处理 绘制曲面图
Python matplotlib模块,是扩展的MATLAB的一个绘图工具库,它可以绘制各种图形 建议安装 Anaconda后使用 ,集成了很多第三库,基本满足大家的需求,下载地址,对应选择pytho ...
- Python基于pandas的数据处理(二)
14 抽样 df.sample(10, replace = True) df.sample(3) df.sample(frac = 0.5) # 按比例抽样 df.sample(frac = 10, ...
随机推荐
- 使用PyTorch简单实现卷积神经网络模型
这里我们会用 Python 实现三个简单的卷积神经网络模型:LeNet .AlexNet .VGGNet,首先我们需要了解三大基础数据集:MNIST 数据集.Cifar 数据集和 ImageNet 数 ...
- Ant Design Pro Vue 时间段查询 问题
<a-form-item label="起止日期" :labelCol="{lg: {span: 7}, sm: {span: 7}}" :wrapper ...
- Qt编写安防视频监控系统(界面很漂亮)
一.前言 视频监控系统在整个安防领域,已经做到了烂大街的程序,全国起码几百家公司做过类似的系统,当然这一方面的需求量也是非常旺盛的,各种定制化的需求越来越多,尤其是这几年借着人脸识别的东风,发展更加迅 ...
- matlab学习笔记13_1 函数返回值
一起来学matlab-matlab学习笔记13函数 13_1 函数返回值 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考文献 https://blog.csdn.net/qq_36556 ...
- 深入Nginx之《HTTP请求报文与HTTP响应报文》
HTTP请求报文 这个很有必要了解,好歹我们得知道Nginx在提供HTTP服务时,客户端都会传些什么.HTTP请求中客户端传送的内容称为HTTP请求报文. 1.请求行包含: 请求方法,请求URL,HT ...
- Ribbon和Nignx的区别
Ribbon属于客户端负载均衡:在调用接口的时候,会通过服务别名到eureka上获取服务的信息列表,缓存到jvm本地,在本地采用RPC远程调用技术去调用接口,实现负载均衡.可以设置调用的规则是请求总数 ...
- Kubernetes集群中Jmeter对公司演示的压力测试
6分钟阅读 背景 压力测试是评估Web应用程序性能的有效方法.此外,越来越多的Web应用程序被分解为几个微服务,每个微服务的性能可能会有所不同,因为有些是计算密集型的,而有些是IO密集型的. 基于微服 ...
- Mysql 索引基础
[1]什么是索引?为什么要建立索引? 索引,其实就是目录. 索引,用于快速找出在某个列中有某个特定值的行. 不使用索引,MySQL必须从第一条记录开始查找整张表,直到找出相关的行,那么表越大,查询数据 ...
- SpringBoot获得application.properties中数据的几种方式
转:https://blog.csdn.net/qq_27298687/article/details/79033102 SpringBoot获得application.properties中数据的几 ...
- lsyncd实时同步工具
简介 Lysncd 实际上是lua语言封装了 inotify 和 rsync 工具,采用了 Linux 内核(2.6.13 及以后)里的 inotify 触发机制,然后通过rsync去差异同步,达到实 ...