Tensorflow快餐教程(1) - 30行代码搞定手写识别
去年买了几本讲tensorflow的书,结果今年看的时候发现有些样例代码所用的API已经过时了。看来自己维护一个保持更新的Tensorflow的教程还是有意义的。这是写这一系列的初心。
快餐教程系列希望能够尽可能降低门槛,少讲,讲透。
为了让大家在一开始就看到一个美好的场景,而不是停留在漫长的基础知识积累上,参考网上的一些教程,我们直接一开始就直接展示用tensorflow实现MNIST手写识别的例子。然后基础知识我们再慢慢讲。
Tensorflow安装速成教程
由于Python是跨平台的语言,所以在各系统上安装tensorflow都是一件相对比较容易的事情。GPU加速的事情我们后面再说。
Linux平台安装tensorflow
我们以Ubuntu 16.04版为例,首先安装python3和pip3。pip是python的包管理工具。
sudo apt install python3
sudo apt install python3-pip- 1
- 2
然后就可以通过pip3来安装tensorflow:
pip3 install tensorflow --upgrade- 1
MacOS安装tensorflow
建议使用Homebrew来安装python。
brew install python3- 1
安装python3之后,还是通过pip3来安装tensorflow.
pip3 install tensorflow --upgrade- 1
Windows平台安装Tensorflow
Windows平台上建议通过Anaconda来安装tensorflow,下载地址在:https://www.anaconda.com/download/#windows
然后打开Anaconda Prompt,输入:
conda create -n tensorflow pip
activate tensorflow
pip install --ignore-installed --upgrade tensorflow- 1
- 2
- 3
这样就安装好了Tensorflow。
我们迅速来个例子试下好不好用:
import tensorflow as tf
a = tf.constant(1)
b = tf.constant(2)
c = a * b
sess = tf.Session()
print(sess.run(c))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
输出结果为2.
Tensorflow顾名思义,是一些Tensor张量的流组成的运算。
运算需要一个Session来运行。如果print(c)的话,会得到
Tensor("mul_1:0", shape=(), dtype=int32)- 1
就是说这是一个乘法运算的Tensor,需要通过Session.run()来执行。
入门捷径:线性回归
我们首先看一个最简单的机器学习模型,线性回归的例子。
线性回归的模型就是一个矩阵乘法:
tf.multiply(X, w)- 1
然后我们通过调用Tensorflow计算梯度下降的函数tf.train.GradientDescentOptimizer来实现优化。
我们看下这个例子代码,只有30多行,逻辑还是很清晰的。例子来自github上大牛的工作:https://github.com/nlintz/TensorFlow-Tutorials,不是我的原创。
import tensorflow as tf
import numpy as np
trX = np.linspace(-1, 1, 101)
trY = 2 * trX + np.random.randn(*trX.shape) * 0.33 # 创建一些线性值附近的随机值
X = tf.placeholder("float")
Y = tf.placeholder("float")
def model(X, w):
return tf.multiply(X, w) # X*w线性求值,非常简单
w = tf.Variable(0.0, name="weights")
y_model = model(X, w)
cost = tf.square(Y - y_model) # 用平方误差做为优化目标
train_op = tf.train.GradientDescentOptimizer(0.01).minimize(cost) # 梯度下降优化
# 开始创建Session干活!
with tf.Session() as sess:
# 首先需要初始化全局变量,这是Tensorflow的要求
tf.global_variables_initializer().run()
for i in range(100):
for (x, y) in zip(trX, trY):
sess.run(train_op, feed_dict={X: x, Y: y})
print(sess.run(w))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
最终会得到一个接近2的值,比如我这次运行的值为1.9183811
多种方式搞定手写识别
线性回归不过瘾,我们直接一步到位,开始进行手写识别。

我们采用深度学习三巨头之一的Yann Lecun教授的MNIST数据为例。如上图所示,MNIST的数据是28x28的图像,并且标记了它的值应该是什么。
线性模型:logistic回归
我们首先不管三七二十一,就用线性模型来做分类。
算上注释和空行,一共加起来30行左右,我们就可以解决手写识别这么困难的问题啦!请看代码:
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
def init_weights(shape):
return tf.Variable(tf.random_normal(shape, stddev=0.01))
def model(X, w):
return tf.matmul(X, w) # 模型还是矩阵乘法
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
trX, trY, teX, teY = mnist.train.images, mnist.train.labels, mnist.test.images, mnist.test.labels
X = tf.placeholder("float", [None, 784])
Y = tf.placeholder("float", [None, 10])
w = init_weights([784, 10])
py_x = model(X, w)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=py_x, labels=Y)) # 计算误差
train_op = tf.train.GradientDescentOptimizer(0.05).minimize(cost) # construct optimizer
predict_op = tf.argmax(py_x, 1)
with tf.Session() as sess:
tf.global_variables_initializer().run()
for i in range(100):
for start, end in zip(range(0, len(trX), 128), range(128, len(trX)+1, 128)):
sess.run(train_op, feed_dict={X: trX[start:end], Y: trY[start:end]})
print(i, np.mean(np.argmax(teY, axis=1) ==
sess.run(predict_op, feed_dict={X: teX})))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
经过100轮的训练,我们的准确率是92.36%。
无脑的浅层神经网络
用了最简单的线性模型,我们换成经典的神经网络来实现这个功能。神经网络的图如下图所示。
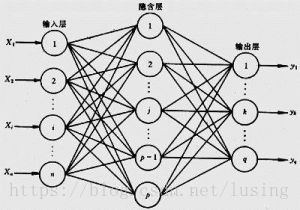
我们还是不管三七二十一,建立一个隐藏层,用最传统的sigmoid函数做激活函数。其核心逻辑还是矩阵乘法,这里面没有任何技巧。
h = tf.nn.sigmoid(tf.matmul(X, w_h))
return tf.matmul(h, w_o)- 1
- 2
完整代码如下,仍然是40多行,不长:
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
# 所有连接随机生成权值
def init_weights(shape):
return tf.Variable(tf.random_normal(shape, stddev=0.01))
def model(X, w_h, w_o):
h = tf.nn.sigmoid(tf.matmul(X, w_h))
return tf.matmul(h, w_o)
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
trX, trY, teX, teY = mnist.train.images, mnist.train.labels, mnist.test.images, mnist.test.labels
X = tf.placeholder("float", [None, 784])
Y = tf.placeholder("float", [None, 10])
w_h = init_weights([784, 625])
w_o = init_weights([625, 10])
py_x = model(X, w_h, w_o)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=py_x, labels=Y)) # 计算误差损失
train_op = tf.train.GradientDescentOptimizer(0.05).minimize(cost) # construct an optimizer
predict_op = tf.argmax(py_x, 1)
with tf.Session() as sess:
tf.global_variables_initializer().run()
for i in range(100):
for start, end in zip(range(0, len(trX), 128), range(128, len(trX)+1, 128)):
sess.run(train_op, feed_dict={X: trX[start:end], Y: trY[start:end]})
print(i, np.mean(np.argmax(teY, axis=1) ==
sess.run(predict_op, feed_dict={X: teX})))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
第一轮运行,我这次的准确率只有69.11% ,第二次就提升到了82.29%。最终结果是95.41%,比Logistic回归的强!
请注意我们模型的核心那两行代码,完全就是无脑地全连接做了一个隐藏层而己,这其中没有任何的技术。完全是靠神经网络的模型能力。
深度学习时代的方案 - ReLU和Dropout显神通
上一个技术含量有点低,现在是深度学习的时代了,我们有很多进步。比如我们知道要将sigmoid函数换成ReLU函数。我们还知道要做Dropout了。于是我们还是一个隐藏层,写个更现代一点的模型吧:
X = tf.nn.dropout(X, p_keep_input)
h = tf.nn.relu(tf.matmul(X, w_h))
h = tf.nn.dropout(h, p_keep_hidden)
h2 = tf.nn.relu(tf.matmul(h, w_h2))
h2 = tf.nn.dropout(h2, p_keep_hidden)
return tf.matmul(h2, w_o)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
除了ReLU和dropout这两个技巧,我们仍然只有一个隐藏层,表达能力没有太大的增强。并不能算是深度学习。
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
def init_weights(shape):
return tf.Variable(tf.random_normal(shape, stddev=0.01))
def model(X, w_h, w_h2, w_o, p_keep_input, p_keep_hidden):
X = tf.nn.dropout(X, p_keep_input)
h = tf.nn.relu(tf.matmul(X, w_h))
h = tf.nn.dropout(h, p_keep_hidden)
h2 = tf.nn.relu(tf.matmul(h, w_h2))
h2 = tf.nn.dropout(h2, p_keep_hidden)
return tf.matmul(h2, w_o)
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
trX, trY, teX, teY = mnist.train.images, mnist.train.labels, mnist.test.images, mnist.test.labels
X = tf.placeholder("float", [None, 784])
Y = tf.placeholder("float", [None, 10])
w_h = init_weights([784, 625])
w_h2 = init_weights([625, 625])
w_o = init_weights([625, 10])
p_keep_input = tf.placeholder("float")
p_keep_hidden = tf.placeholder("float")
py_x = model(X, w_h, w_h2, w_o, p_keep_input, p_keep_hidden)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=py_x, labels=Y))
train_op = tf.train.RMSPropOptimizer(0.001, 0.9).minimize(cost)
predict_op = tf.argmax(py_x, 1)
with tf.Session() as sess:
# you need to initialize all variables
tf.global_variables_initializer().run()
for i in range(100):
for start, end in zip(range(0, len(trX), 128), range(128, len(trX)+1, 128)):
sess.run(train_op, feed_dict={X: trX[start:end], Y: trY[start:end],
p_keep_input: 0.8, p_keep_hidden: 0.5})
print(i, np.mean(np.argmax(teY, axis=1) ==
sess.run(predict_op, feed_dict={X: teX,
p_keep_input: 1.0,
p_keep_hidden: 1.0})))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
从结果看到,第二次就达到了96%以上的正确率。后来就一直在98.4%左右游荡。仅仅是ReLU和Dropout,就把准确率从95%提升到了98%以上。
卷积神经网络出场
真正的深度学习利器CNN,卷积神经网络出场。这次的模型比起前面几个无脑型的,的确是复杂一些。涉及到卷积层和池化层。这个是需要我们后面详细讲一讲了。
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
batch_size = 128
test_size = 256
def init_weights(shape):
return tf.Variable(tf.random_normal(shape, stddev=0.01))
def model(X, w, w2, w3, w4, w_o, p_keep_conv, p_keep_hidden):
l1a = tf.nn.relu(tf.nn.conv2d(X, w, # l1a shape=(?, 28, 28, 32)
strides=[1, 1, 1, 1], padding='SAME'))
l1 = tf.nn.max_pool(l1a, ksize=[1, 2, 2, 1], # l1 shape=(?, 14, 14, 32)
strides=[1, 2, 2, 1], padding='SAME')
l1 = tf.nn.dropout(l1, p_keep_conv)
l2a = tf.nn.relu(tf.nn.conv2d(l1, w2, # l2a shape=(?, 14, 14, 64)
strides=[1, 1, 1, 1], padding='SAME'))
l2 = tf.nn.max_pool(l2a, ksize=[1, 2, 2, 1], # l2 shape=(?, 7, 7, 64)
strides=[1, 2, 2, 1], padding='SAME')
l2 = tf.nn.dropout(l2, p_keep_conv)
l3a = tf.nn.relu(tf.nn.conv2d(l2, w3, # l3a shape=(?, 7, 7, 128)
strides=[1, 1, 1, 1], padding='SAME'))
l3 = tf.nn.max_pool(l3a, ksize=[1, 2, 2, 1], # l3 shape=(?, 4, 4, 128)
strides=[1, 2, 2, 1], padding='SAME')
l3 = tf.reshape(l3, [-1, w4.get_shape().as_list()[0]]) # reshape to (?, 2048)
l3 = tf.nn.dropout(l3, p_keep_conv)
l4 = tf.nn.relu(tf.matmul(l3, w4))
l4 = tf.nn.dropout(l4, p_keep_hidden)
pyx = tf.matmul(l4, w_o)
return pyx
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
trX, trY, teX, teY = mnist.train.images, mnist.train.labels, mnist.test.images, mnist.test.labels
trX = trX.reshape(-1, 28, 28, 1) # 28x28x1 input img
teX = teX.reshape(-1, 28, 28, 1) # 28x28x1 input img
X = tf.placeholder("float", [None, 28, 28, 1])
Y = tf.placeholder("float", [None, 10])
w = init_weights([3, 3, 1, 32]) # 3x3x1 conv, 32 outputs
w2 = init_weights([3, 3, 32, 64]) # 3x3x32 conv, 64 outputs
w3 = init_weights([3, 3, 64, 128]) # 3x3x32 conv, 128 outputs
w4 = init_weights([128 * 4 * 4, 625]) # FC 128 * 4 * 4 inputs, 625 outputs
w_o = init_weights([625, 10]) # FC 625 inputs, 10 outputs (labels)
p_keep_conv = tf.placeholder("float")
p_keep_hidden = tf.placeholder("float")
py_x = model(X, w, w2, w3, w4, w_o, p_keep_conv, p_keep_hidden)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=py_x, labels=Y))
train_op = tf.train.RMSPropOptimizer(0.001, 0.9).minimize(cost)
predict_op = tf.argmax(py_x, 1)
with tf.Session() as sess:
# you need to initialize all variables
tf.global_variables_initializer().run()
for i in range(100):
training_batch = zip(range(0, len(trX), batch_size),
range(batch_size, len(trX)+1, batch_size))
for start, end in training_batch:
sess.run(train_op, feed_dict={X: trX[start:end], Y: trY[start:end],
p_keep_conv: 0.8, p_keep_hidden: 0.5})
test_indices = np.arange(len(teX)) # Get A Test Batch
np.random.shuffle(test_indices)
test_indices = test_indices[0:test_size]
print(i, np.mean(np.argmax(teY[test_indices], axis=1) ==
sess.run(predict_op, feed_dict={X: teX[test_indices],
p_keep_conv: 1.0,
p_keep_hidden: 1.0})))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
我们看下这次的运行数据:
0 0.95703125
1 0.9921875
2 0.9921875
3 0.98046875
4 0.97265625
5 0.98828125
6 0.99609375- 1
- 2
- 3
- 4
- 5
- 6
- 7
在第6轮的时候,就跑出了99.6%的高分值,比ReLU和Dropout的一个隐藏层的神经网络的98.4%大大提高。因为难度是越到后面越困难。
在第16轮的时候,竟然跑出了100%的正确率:
7 0.99609375
8 0.99609375
9 0.98828125
10 0.98828125
11 0.9921875
12 0.98046875
13 0.99609375
14 0.9921875
15 0.99609375
16 1.0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
综上,借助Tensorflow和机器学习工具,我们只有几十行代码,就解决了手写识别这样级别的问题,而且准确度可以达到如此程度。
下一节,我们回到基础讲起。
Tensorflow快餐教程(1) - 30行代码搞定手写识别的更多相关文章
- 30行代码搞定WCF并发性能测试
[以下只是个人观点,欢迎交流] 30行代码搞定WCF并发性能 轻量级测试. 1. 调用并发测试接口 static void Main() { List< ...
- 10分钟教你用python 30行代码搞定简单手写识别!
欲直接下载代码文件,关注我们的公众号哦!查看历史消息即可! 手写笔记还是电子笔记好呢? 毕业季刚结束,眼瞅着2018级小萌新马上就要来了,老腊肉小编为了咱学弟学妹们的学习,绞尽脑汁准备编一套大学秘籍, ...
- 10行代码搞定移动web端自定义tap事件
发发牢骚 移动web端里摸爬滚打这么久踩了不少坑,有一定移动web端经验的同学一定被click困扰过.我也不列外.一路走来被虐的不行,fastclick.touchend.iscroll什么的都用过, ...
- [Unity Editor]10行代码搞定Hierarchy排序
在日常的工作和研究中,当给我们的场景摆放过多的物件的时候,Hierarchy面板就会变得杂乱不堪.比如这样: 过多的层次结构充斥在里面,根层的物件毫无序列可言,整个层次面板显示非常的杂乱不堪,如 ...
- 如何用Python统计《论语》中每个字的出现次数?10行代码搞定--用计算机学国学
编者按: 上学时听过山师王志民先生一场讲座,说每个人不论干什么,都应该学习国学(原谅我学了计算机专业)!王先生讲得很是吸引我这个工科男,可能比我的后来的那些同学听课还要认真些,当然一方面是兴趣.一方面 ...
- BaseHttpListActivity,几行代码搞定Android Http列表请求、加载和缓存
Android开发中,向服务器请求一个列表并显示是非常常见的需求,但实现起来比较麻烦,代码繁杂. 随着应用的更新迭代,这种需求越来越多,我渐渐发现了实现这种需求的代码的共同点. 于是我将Activit ...
- python爬煎蛋妹子图--20多行代码搞定煎蛋妹子图库
如果说一个人够无聊的话... 就会做一些十分美(wei)丽(suo)的事情啦哈哈哈... 好的,话不多说,进入正题. 正如标题所示,我们今天的目标很简单: 代码要少,妹子要好. 步骤如下: 1. 首先 ...
- 100行代码搞定抖音短视频App,终于可以和美女合唱了。
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由视频咖 发表于云+社区专栏 本文作者,shengcui,腾讯云高级开发工程师,负责移动客户端开发 最近抖音最近又带了一波合唱的节奏,老 ...
- python入门机器学习,3行代码搞定线性回归
本文着重是重新梳理一下线性回归的概念,至于几行代码实现,那个不重要,概念明确了,代码自然水到渠成. “机器学习”对于普通大众来说可能会比较陌生,但是“人工智能”这个词简直是太火了,即便是风云变化的股市 ...
随机推荐
- MapReduce 程序mysql JDBC驱动类找不到原因及学习hadoop写入数据到Mysql数据库的方法
报错 :ClassNotFoundException: com.mysql.jdbc.Driver 需求描述: hadoop需要动态加载个三方jar包(比如mysql JDBC 驱动包),是在MR结束 ...
- Box HDU - 2475 (Splay 维护森林)
Box \[ Time Limit: 5000 ms \quad Memory Limit: 32768 kB \] 题意 给出 \(n\) 个箱子的包含关系,每次两种操作. 操作 \(1\):把 \ ...
- git crate&query&delete tag(九)
root@vmuer-VirtualBox:/opt/myProject# git log --pretty=oneline0169b7a1c4bccb47e76711f353fd8d3864bde9 ...
- 异常DBG_PRINTEXCEPTION_C(0x40010006)和DBG_PRINTEXCEPTION_WIDE_C(0x4001000A)
简介 DBG_PRINTEXCEPTION_C,代码0x40010006:DBG_PRINTEXCEPTION_WIDE_C,代码0x4001000A:在调试器的控制台窗口打印异常信息/调试信息.它定 ...
- ESA2GJK1DH1K基础篇: Android连接MQTT简单的Demo
题外话 我老爸也问我物联网发展的趋势是什么!!!!!! 我自己感觉的:(正在朝着 "我,机器人" 这部电影的服务器方向发展) 以后的设备都会和服务器交互,就是说本地不再做处理,全部 ...
- contest4 CF1091 div2 ooooxx ooooxx ooooox
题意 div2E 一个有\(n+1\)个点的无向图, 给出\(n\)个点的度数, 求出每一种可能的\(n+1\)的度数 (题面附带公式 graph realization problem)
- Python实现电子词典
代码一览: dictionary/├── code│ ├── client.py│ ├── func.py│ ├── server.py│ └── settings.py├── dat ...
- 网络协议 4 - 交换机与 VLAN:拓扑结构
上一次,我们通过宿舍联网打魔兽的需求,认识了如何通过物理层和链路层组建一个宿舍局域网.今天,让我们切换到稍微复杂点的场景,办公室. 在这个场景里,就不像在宿舍那样,搞几根网线,拉一拉,扯一扯就 ...
- docker compose yml 文件常用字段简介
常用参数: version # 指定 compose 文件的版本 services # 定义所有的 service 信息, services 下面的第一级别的 key 既是一个 service 的名称 ...
- Linux搭建简单的http文件服务器
为了让自动化脚本可以通过wget来下载安装包,需要在集群中的某个节点部署一个http文件服务器 在Ubuntu中通过apt-get install apache2 安装apache2CentOS7中通 ...