Introduction to Locking in SQL Server
Locking is a major part of every RDBMS and is important to know about. It is a database functionality which without a multi-user environment could not work. The main problem of locking is that in an essence it's a logical and not physical problem. This means that no amount of hardware will help you in the end. Yes you might cut execution times but this is only a virtual fix. In a heavy multi-user environment any logical problems will appear sooner or later.
Lock modes
All examples are run under the default READ COMMITED isolation level. Taken locks differ between isolation levels, however these examples are just to demonstrate the lock mode with an example. Here's a little explanation of the three columns from sys.dm_tran_locks used in the examples:
| resource_type | This tells us what resource in the database the locks are being taken on. It can be one of these values: DATABASE, FILE, OBJECT, PAGE, KEY, EXTENT, RID, APPLICATION, METADATA, HOBT, ALLOCATION_UNIT. |
| request_mode | This tells us the mode of our lock. |
| resource_description | This shows a brief description of the resource. Usually holds the id of the page, object, file, row, etc. It isn't populated for every type of lock |
The filter on resource_type <> 'DATABASE' just means that we don't want to see general shared locks taken on databases. These are always present. All shown outputs are from the sys.dm_tran_locks dynamic management view. In some examples it is truncated to display only locks relevant for the example. For full output you can run these yourself.
Shared locks (S)
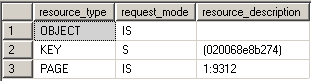
Shared locks are held on data being read under the pessimistic concurrency model. While a shared lock is being held other transactions can read but can't modify locked data. After the locked data has been read the shared lock is released, unless the transaction is being run with the locking hint (READCOMMITTED, READCOMMITTEDLOCK) or under the isolation level equal or more restrictive than Repeatable Read. In the example you can't see the shared locks because they're taken for the duration of the select statement and are already released when we would select data from sys.dm_tran_locks. That is why an addition of WITH (HOLDLOCK) is needed to see the locks.
BEGIN TRAN USE AdventureWorks SELECT * FROM Person.Address WITH (HOLDLOCK)
WHERE AddressId = 2 SELECT resource_type, request_mode, resource_description
FROM sys.dm_tran_locks
WHERE resource_type <> 'DATABASE' ROLLBACK
Update locks (U)
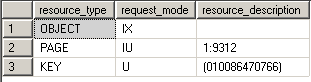
Update locks are a mix of shared and exclusive locks. When a DML statement is executed SQL Server has to find the data it wants to modify first, so to avoid lock conversion deadlocks an update lock is used. Only one update lock can be held on the data at one time, similar to an exclusive lock. But the difference here is that the update lock itself can't modify the underlying data. It has to be converted to an exclusive lock before the modification takes place. You can also force an update lock with the UPDLOCK hint:
BEGIN TRAN USE AdventureWorks SELECT * FROM Person.Address WITH (UPDLOCK)
WHERE AddressId < 2 SELECT resource_type, request_mode, resource_description
FROM sys.dm_tran_locks
WHERE resource_type <> 'DATABASE' ROLLBACK
Exclusive locks (X)
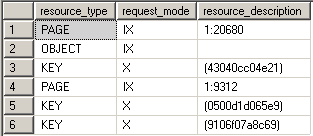
Exclusive locks are used to lock data being modified by one transaction thus preventing modifications by other concurrent transactions. You can read data held by exclusive lock only by specifying a NOLOCK hint or using a read uncommitted isolation level. Because DML statements first need to read the data they want to modify you'll always find Exclusive locks accompanied by shared locks on that same data.
BEGIN TRAN USE AdventureWorks UPDATE Person.Address
SET AddressLine2 = 'Test Address 2'
WHERE AddressId = 5 SELECT resource_type, request_mode, resource_description
FROM sys.dm_tran_locks
WHERE resource_type <> 'DATABASE' ROLLBACK
Intent locks (I)
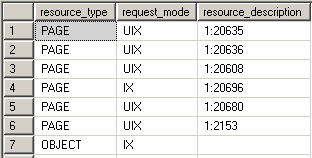
Intent locks are a means in which a transaction notifies other transaction that it is intending to lock the data. Thus the name. Their purpose is to assure proper data modification by preventing other transactions to acquire a lock on the object higher in lock hierarchy. What this means is that before you obtain a lock on the page or the row level an intent lock is set on the table. This prevents other transactions from putting exclusive locks on the table that would try to cancel the row/page lock. In the example we can see the intent exclusive locks being placed on the page and the table where the key is to protect the data from being locked by other transactions.
BEGIN TRAN USE AdventureWorks UPDATE TOP(5) Person.Address
SET AddressLine2 = 'Test Address 2'
WHERE PostalCode = '98011' SELECT resource_type, request_mode, resource_description
FROM sys.dm_tran_locks
WHERE resource_type <> 'DATABASE' ROLLBACK
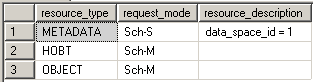
Schema locks (Sch)
There are two types of schema locks:
- Schema stability lock (Sch-S): Used while generating execution plans. These locks don't block access to the object data.
- Schema modification lock (Sch-M): Used while executing a DDL statement. Blocks access to the object data since its structure is being changed.
In the example we can see the Sch-S and Sch-M locks being taken on the system tables and the TestTable plus a lot of other locks on the system tables.
BEGIN TRAN USE AdventureWorks CREATE TABLE TestTable (TestColumn INT) SELECT resource_type, request_mode, resource_description
FROM sys.dm_tran_locks
WHERE resource_type <> 'DATABASE' ROLLBACK
Bulk Update locks (BU)
Bulk Update locks are used by bulk operations when TABLOCK hint is used by the import. This allows for multiple fast concurrent inserts by disallowing data reading to other transactions.
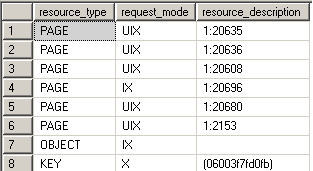
Conversion locks
Conversion locks are locks resulting from converting one type of lock to another. There are 3 types of conversion locks:
- Shared with Intent Exclusive (SIX). A transaction that holds a Shared lock also has some pages/rows locked with an Exclusive lock
- Shared with Intent Update (SIU). A transaction that holds a Shared lock also has some pages/rows locked with an Update lock.
- Update with Intent Exclusive (UIX). A transaction that holds an Update lock also has some pages/rows locked with an Exclusive lock.
In the example you can see the UIX conversion lock being taken on the page:
BEGIN TRAN USE AdventureWorks UPDATE TOP(5) Person.Address
SET AddressLine2 = 'Test Address 2'
WHERE PostalCode = '98011' SELECT resource_type, request_mode, resource_description
FROM sys.dm_tran_locks
WHERE resource_type <> 'DATABASE' ROLLBACK
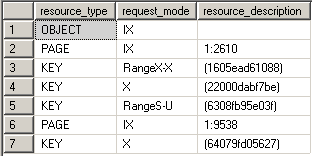
Key - Range locks
Key-range locks protect a range of rows implicitly included in a record set being read by a Transact-SQL statement while using the serializable transaction isolation level. Key-range locking prevents phantom reads. By protecting the ranges of keys between rows, it also prevents phantom insertions or deletions into a record set accessed by a transaction. In the example we can see that there are two types of key-range locks taken:
- RangeX-X - exclusive lock on the interval between the keys and exclusive lock on the last key in the range
- RangeS-U – shared lock on the interval between the keys and update lock on the last key in the range
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE; BEGIN TRAN USE AdventureWorks UPDATE Person.Address
SET AddressLine2 = 'Test Address 2'
WHERE AddressLine1 LIKE '987 %' SELECT resource_type, request_mode, resource_description
FROM sys.dm_tran_locks
WHERE resource_type <> 'DATABASE' ROLLBACK
Lock Granularity
Lock granularity consists of TABLE, PAGE and ROW locks. If you have a clustered index on the table then instead of a ROW lock you have a KEY lock. Locking on the lower level increases concurrency, but if a lot of locks are taken consumes more memory and vice versa for the higher levels. So granularity simply means the level at which the SQL Server locks data. Also note that the more restricted isolation level we choose, the higher the locking level to keep data in correct state. You can override the locking level by using ROWLOCK, PAGLOCK or TABLOCK hints but the use of these hints is discouraged since SQL Server know what are the appropriate locks to take for each scenario. If you must use them you should be aware of the concurrency and data consistency issues you might cause.
Spinlocks
Spinlocks are a light-weight lock mechanism that doesn't lock data but it waits for a short period of time for a lock to be free if a lock already exists on the data a transaction is trying to lock. It's a mutual exclusion mechanism to reduce context switching between threads in SQL Server.
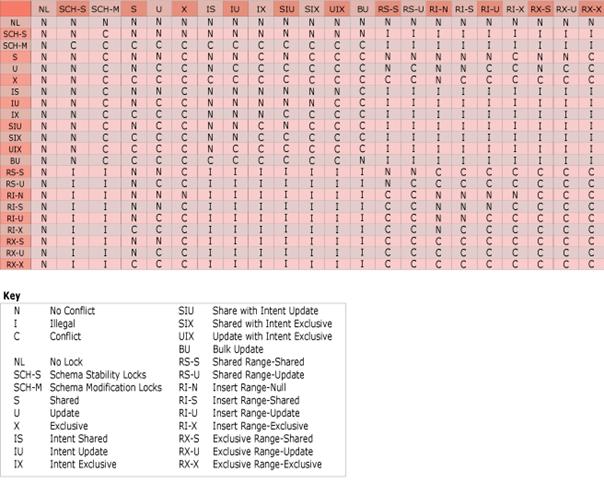
Lock Compatibility Matrix
This is taken from http://msdn2.microsoft.com/En-US/library/ms186396.aspx. Also a good resource to have is a Lock Compatibility Matrix which tells you how each lock plays nice with other lock modes. It is one of those things you don't think you need up until the moment you need it.
Conclusion
Hopefully this article has shed some light on how SQL Server operates with locks and why is locking of such importance to proper application and database design and operation. Remember that locking problems are of logical and not physical nature so they have to be well thought out. Locking goes hand in hand with transaction isolation levels so be familiar with those too. In the next article I'll show some ways to resolve locking problems.
from:http://www.sqlteam.com/article/introduction-to-locking-in-sql-server
Introduction to Locking in SQL Server的更多相关文章
- SQL Server on Linux: How? Introduction: SQL Server Blog
SQL Server Blog Official News from Microsoft’s Information Platform https://blogs.technet.microsoft. ...
- SQL Server 监控系列(文章索引)
一.前言(Introduction) SQL Server监控在很多时候可以帮助我们了解数据库做了些什么,比如谁谁在什么时候修改了表结构,谁谁在删除了某个对象,当这些事情发生了,老板在后面追着说这是谁 ...
- SQL Server 复制系列(文章索引)
一.本文所涉及的内容(Contents) 本文所涉及的内容(Contents) 前言(Introduction) 复制逻辑结构图(Construction) 系列文章索引(Catalog) 总结&am ...
- Step1:SQL Server 复制介绍
一.本文所涉及的内容(Contents) 本文所涉及的内容(Contents) 前言(Introduction) 复制逻辑结构图(Construction) 系列文章索引(Catalog) 总结&am ...
- SQL Server: Difference Between Locking, Blocking and Dead Locking
Like ever, today’s article of Pinal Dave was interesting and informative. After, our mutual discussi ...
- Quick Introduction to SQL Server Profiler
Introduction to Profiler SQL Server Profiler — or just Profiler — is a tool that can help monitor al ...
- SQL Server Debugging with WinDbg – an Introduction
Klaus Aschenbrenner Klaus Aschenbrenner provides independent SQL Server Consulting Services across E ...
- 《Pro SQL Server Internals, 2nd edition》的CHAPTER 3 Statistics中的Introduction to SQL Server Statistics、Statistics and Execution Plans、Statistics Maintenance(译)
<Pro SQL Server Internals> 作者: Dmitri Korotkevitch 出版社: Apress出版年: 2016-12-29页数: 804定价: USD 59 ...
- SQL Server 2008性能故障排查(一)——概论
原文:SQL Server 2008性能故障排查(一)--概论 备注:本人花了大量下班时间翻译,绝无抄袭,允许转载,但请注明出处.由于篇幅长,无法一篇博文全部说完,同时也没那么快全部翻译完,所以按章节 ...
随机推荐
- GPS-Graph Processing System Graph Coloring算法分析 (三)
HamaWhite 原创,转载请注明出处!欢迎大家增加Giraph 技术交流群: 228591158 Graph coloring is the problem of assignin ...
- 浅谈Fluent Ribbon 中的SplitButton
Fluent Ribbon Control Suite 就不做介绍了,网上的例子比较多,类似Office2007及以后版本的图形界面(菜单栏).官网地址:https://github.com/flue ...
- springboot项目用maven打jar包
clean package -Dmaven.test.skip=true idea eclipse STS
- Dubbo实践(十)代理
Invoker调用 代理有几种方式:普通代理.JDK.Javassist库动态代理.Javassist库动态字节码代理. 生成代理的目的是你调用invoker的相关函数后,就等同于是调用DubboIn ...
- CSU - 1581 Clock Pictures (KMP的变形题,难想到)
题目链接: http://acm.csu.edu.cn/csuoj/problemset/problem?pid=1581 题目意思:告诉你现在有两个钟,现在两个钟上面都有n个指针,告诉你指针的位置, ...
- 服务器监控zabbix
nagios服务器安装:http://www.jb51.net/article/79496.htm默认端口12489 nagios +ndo2db+mysqlhttps://www.cnblogs.c ...
- ACM-SG函数之S-Nim——hdu1536 hdu1944 poj2960
S-Nim Time Limit: 5000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Total Subm ...
- 自己动手写一个简易对象关系映射,ORM(单例版和数据库池版)
准备知识 DBUtils模块 <<-----重点 DBUtils是Python的一个用于实现数据库连接池的模块 此连接池有两种连接模式: DBUtils提供两种外部接口: Persist ...
- thinphp5-image图片处理类库压缩图片
使用tp5的thinkphp-image类库处理图片 使用方法手册都有,为了增加印象我自己记录一下 手册:https://www.kancloud.cn/manual/thinkphp5/177530 ...
- 关于flume的filechannel的 full 问题
事务启动以后,批量向事务Transaction的一个putList的尾部写入,putlist是一个LinkedBlockingDeque . 事务提交的时候, 把putlist中的event批量移除, ...