关于解决乱码问题的一点探索之一(涉及utf-8和GBK)
在使用Visual Studio 2005进行MFC开发的时候,发现自动添加的注释变成了乱码。像这样:
// TODO: ÔÚ´ËÌí¼ÓרÓôúÂëºÍ/»òµ÷ÓûùÀà还有这样:
// TODO: ÔÚ´ËÌí¼ÓÏûÏ¢´¦Àí³ÌÐò´úÂëºÍ/»òµ÷ÓÃĬÈÏÖµ它们正确的显示应该是
// TODO: 在此添加专用代码和/或调用基类和
// TODO: 在此添加消息处理程序代码和/或调用默认值
当保存的时候,还出现了这样的对话框:
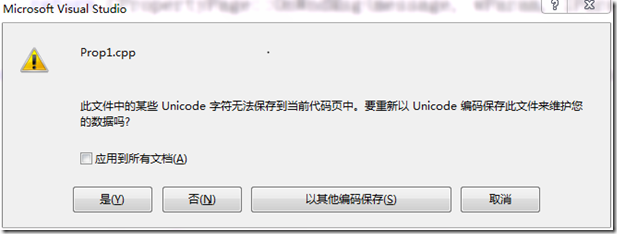
网上找了各种教程,包括什么设置“自动识别不带签名的utf-8”什么的,都没有用。所以考虑自己解决。下面是我的探索过程:
一,保存文件
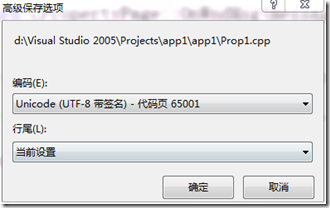
首先,将文件以“Unicode(UTF-8带签名) 代码页:65001”的形式进行保存(带签名的UTF-8是指有BOM的UTF-8,至于带BOM和不带BOM的UTF-8有什么区别,请戳此)。如下图:
二,查看文件的16进制代码(就是查看文件实际上保存成什么数据了)
使用WinHex软件打开刚刚保存的文件(当然,使用UltraEdit也可以),查看文件的16进制代码。我们找到乱码的地方,把它的16进制代码找出来,如下:
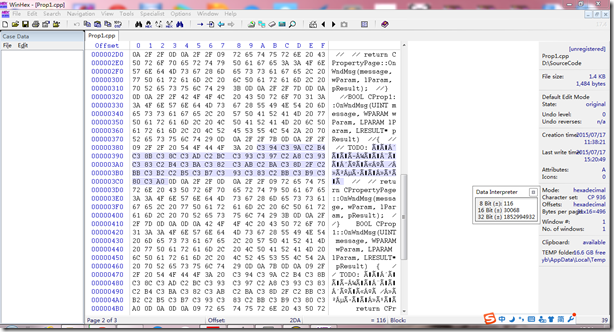
为了更清楚地演示,我将乱码单独拷出来,一定要注意将文本保存成UTF-8(最好带BOM,如果使用Windows自带的文本编辑器编辑就自带BOM)保存成这样:
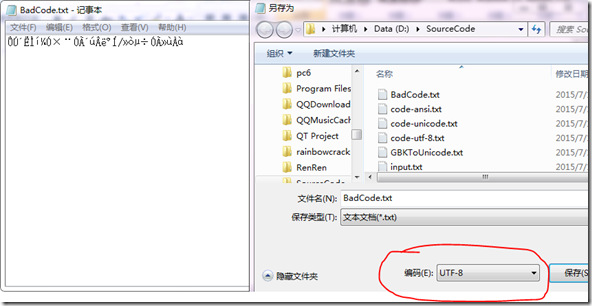
文件对应的16进制代码为:

最前面的三个字节“EF BB BF”就是前面所述的BOM标记,从第四个字节开始,就是文件的实际内容。观察后发现,在实际内容部分,奇数位上不是C2就是C3,偶数位的没有规律,同时,我们找出原话“在此添加专用代码和/或调用基类”对应的GBK编码值,进行比较。
表一:乱码文件中的16进制数据:
0xc3 0x94 0xc3 0x9a
0xc2 0xb4 0xc3 0x8b
0xc3 0x8c 0xc3 0xad
0xc2 0xbc 0xc3 0x93
0xc3 0x97 0xc2 0xa8
0xc3 0x93 0xc3 0x83
0xc2 0xb4 0xc3 0xba
0xc3 0x82 0xc3 0xab
0xc2 0xba 0xc3 0x8d
0x2f
0xc2 0xbb 0xc3 0xb2
0xc2 0xb5 0xc3 0xb7
0xc3 0x93 0xc3 0x83
0xc2 0xbb 0xc3 0xb9
0xc3 0x80 0xc3 0xa0
表二:“在此添加专用代码和/或调用基类”对应的GBK编码值,每个字符(汉字或者/)对应一行:
0xd4 0xda
0xb4 0xcb
0xcc 0xed
0xbc 0xd3
0xd7 0xa8
0xd3 0xc3
0xb4 0xfa
0xc2 0xeb
0xba 0xcd
0x2f
0xbb 0xf2
0xb5 0xf7
0xd3 0xc3
0xbb 0xf9
0xc0 0xe0
4,分析
仔细观察上面的两个表中的数据,我们不难发现以下规律:
1,将表一每行中奇数位置(除了’/’那行)的C2、C3的值去掉,剩下的值和表二中的数据高度相似。
2,除了’/’那行,表一每行中奇数位置为C2的,后面的偶数位数字就和表二中对应位(表一种第二列对应表二第一列,表一第四列对应表二中第二列)相同,表一每行中奇数位为C3的,后面的偶数位数字加上16进制数0x40后也与表二中对应位相同(对应法则同前)。
3,由于乱码文件是以utf-8存储的,但是经过转换后得到的编码为GBK,我们大致可以知道,出现乱码的原因就是visual studio 2005将两种编码搞混了,这应该算是一个bug吧。。毕竟visual studio 2013就从来没有碰到过。。
5,解决问题
根据上面的规律,我们使用二进制方式读取utf-8格式编码的文件数据后经转化然后输出到GBK编码的文件中即可修正问题了。
按照以上的规律编写一段简单的C语言程序:
#include <stdio.h>
#include <stdlib.h> int main(int argc, char const *argv[])
{
FILE* fp;
FILE* fp2;
//打开存储乱码的文件,utf-8格式,二进制打开
if((fp2=fopen("BadCode.txt","rb+"))==NULL)
{
printf("Open Source File Failed!\n");
system("pause");
exit();
}
//打开、新建存储处理后数据的文件
if((fp=fopen("BadCodeH.txt","w+"))==NULL)
{
printf("Open/Create Destination File Failed!\n");
system("pause");
exit();
}
//纪录奇数位(高位)的数据
unsigned ch;
//纪录偶数位(低位)的数据
unsigned cl;
//获得数据
ch=fgetc(fp2);
//判断文件的格式,utf-8或者Unicode,并跳过BOM字符
if(ch==0xef)
{
fgetc(fp2);
fgetc(fp2);
ch=fgetc(fp2);
}
else if(ch==0xff)
{
fgetc(fp2);
ch=fgetc(fp2);
}
//不达结尾
while(!feof(fp2))
{
//ASCII字符,正常输出
if(ch<=0x7f)
{
fputc(ch,fp);
}
//奇数位为0xC3,获得偶数位后加0x40后输出
else if(ch==0xc3)
{
cl=fgetc(fp2);
cl+=0x40;
fputc(cl,fp);
}
//奇数位为0xC2,获得偶数位后直接输出
else if(ch==0xc2)
{
cl=fgetc(fp2);
fputc(cl,fp);
}
//其他情况,直接输出
else
{
fputc(ch,fp);
}
//获得下一个数据
ch=fgetc(fp2);
} fclose(fp);
fclose(fp2);
system("pause");
return ;
}
操作实例结果如下图:
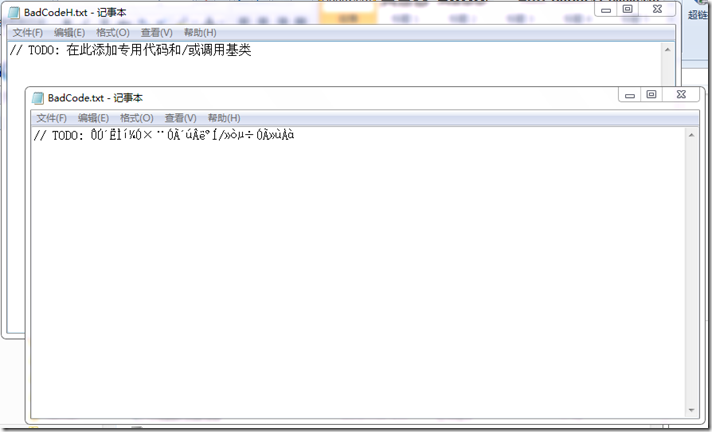
6,更一般的情况(既有正确的中文字符又有乱码)
我们必须注意到一点:上面的C语言程序只适合一种情况:就是乱码文档格式为utf-8且文档中只存在中文乱码字符与ASCII字符。但是我们很多时候是源码中既有正确的中文字符又有乱码字符,这时上面的程序就无效了,因为我们需要将正确中文字符的utf-8编码转换为GBK编码才可以。我们尝试修改上面的代码来解决这个问题。
对于既有乱码又有正常字符的文件来说,只要将正确的中文字符的utf-8编码转化为GBK编码就解决问题了,所以主要问题的关键就是建立一个utf-8与GBK编码的转换表。baidu一下,我们很容易找到了这个表,然后,就写了以下的程序。UnicodeToGBK.txt文件请戳下载地址:
#include <stdio.h>
#include <stdlib.h>
//将gbk编码值存入数组中utf-8编码对应的位置上
bool ReadTable(unsigned* mapValue2)
{
//声明文件指针
FILE* fp;
//打开转换表文件,文件中第一列为汉字的GBK编码,第二列为utf-8编码
//以可读写方式打开
if (NULL == (fp = fopen("Utf8ToGBKTable.txt", "r+")))
{
printf("Open Table Failed!");
system("pause");
return false;
}
//记录gbk的编码值
unsigned gbk=;
//临时记录各位数据
unsigned data;
//记录utf-8的编码值
unsigned long utf=;
//循环次数记号
unsigned id=;
while(!feof(fp))
{
//获得第一列gbk的编码值
for (int i = ; i < ; ++i)
{
data=fgetc(fp);
data=data>='A'?data-'A'+:data-'';
gbk=gbk*+data;
}
//跳过tab键
fgetc(fp);
//获得第二列utf-8的编码值
for (int i = ; i < ; ++i)
{
data=fgetc(fp);
data=data>='A'?data-'A'+:data-'';
utf=utf*+data;
}
if (id>)
{
printf("%d\t%ld\n",gbk,utf );
}
mapValue2[utf-]=gbk;
fgetc(fp);
// fgetc(fp);
//重置数据
gbk=;
utf=;
id++;
} fclose(fp);
return true;
} int main(int argc, char const *argv[])
{
FILE* fp;
FILE* fp2;
//打开存储乱码的文件,utf-8格式,二进制打开
if((fp2=fopen("BadCode.txt","rb+"))==NULL)
{
printf("Open Source File Failed!\n");
system("pause");
exit();
}
//打开、新建存储处理后数据的文件
if((fp=fopen("BadCodeH.txt","w+"))==NULL)
{
printf("Open/Create Destination File Failed!\n");
system("pause");
exit();
}
unsigned mapValue2[];
if(!ReadTable(mapValue2))
{ printf("Convert Failed!\n");
system("pause");
exit(1);
} //纪录奇数位(高位)的数据
unsigned ch;
//纪录偶数位(低位)以及utf-8高位的数据
unsigned cl;
//记录utf-8末位字节的信息
unsigned cu;
////记录正常字符的utf-8编码
unsigned long utf;
//记录正常字符的gbk编码
unsigned cgbk;
//获得数据
ch=fgetc(fp2);
//判断文件的格式,utf-8或者Unicode,并跳过BOM字符
if(ch==0xef)
{
fgetc(fp2);
fgetc(fp2);
ch=fgetc(fp2);
}
else if(ch==0xff)
{
fgetc(fp2);
ch=fgetc(fp2);
}
//不达结尾
while(!feof(fp2))
{
//ASCII字符,正常输出
if(ch<=0x7f)
{
fputc(ch,fp);
}
//奇数位为0xC3,获得偶数位后加0x40后输出
else if(ch==0xc3)
{
cl=fgetc(fp2);
cl+=0x40;
fputc(cl,fp);
}
//奇数位为0xC2,获得偶数位后直接输出
else if(ch==0xc2)
{
cl=fgetc(fp2);
fputc(cl,fp);
}
//其他情况,即正常utf-8字符,转换为GBK字符后输出
else
{ //获得utf-8的中位字节
cl=fgetc(fp2);
//获得utf-8的末尾字节
cu=fgetc(fp2);
//计算utf-8编码
utf=ch*+cl*+cu;
//获得对应的gbk编码
cgbk=mapValue2[utf-0xe4b880];
//输出数据
fputc(cgbk/,fp);
fputc(cgbk%,fp);
}
//获得下一个数据
ch=fgetc(fp2);
} fclose(fp);
fclose(fp2);
system("pause");
return ;
}
使用上面的代码进行测试,就得到下面的结果,表明此算法是有效的。

至此,虽然有点麻烦,但是问题也算解决了。
关于解决乱码问题的一点探索之一(涉及utf-8和GBK)的更多相关文章
- 关于解决乱码问题的一点探索之二(涉及Unicode(utf-16)和GBK)
在上篇日志中(链接),我们讨论了utf-8编码和GBK编码之间转化的乱码问题,这一篇我们讨论Unicode(utf-16编码方式)与GBK编码之间转换的乱码问题. 在Windows系统 ...
- mysql 使用set names 解决乱码问题的原理
解决乱码的方法,我们经常使用“set names utf8”,那么为什么加上这句代码就可以解决了呢?下面跟着我一起来深入set names utf8的内部执行原理 先说MySQL的字符集问题.Wind ...
- servlet 解决乱码问题
对于servlet大家应该都很熟悉了,今天再复习一下,如果有哪里写的不好或不对的地点希望广大的网友批评指正.今天只讨论get和post两w种方式,他们之间有很多的不同点,所以解决编码的方式也会不一样, ...
- 关于Mysql中文乱码问题该如何解决(乱码问题完美解决方案)(转)
这篇文章给大家介绍关于Mysql中文乱码问题该如何解决(乱码问题完美解决方案)的相关资料,还给大家收集些关于MySQL会出现中文乱码原因常见的几点,小伙伴快来看看吧 最近两天做项目总是被乱码问题困 ...
- SpringMVC解决乱码
SpringMVC解决乱码 在web.xml中配置如下代码
- http get/post解决乱码问题
<form method="默认为get"-> <s:form mothod="默认为post"-> ================= ...
- 上传Text文档并转换为PDF(解决乱码)
前些日子,Insus.NET有分享一篇<上传Text文档并转换为PDF>http://www.cnblogs.com/insus/p/4313092.html 它是按最简单与默认方式来处理 ...
- php 解决乱码的通用方法
一,出现乱码的原因分析 1,保存文件时候,文件有自己的文件编码,就是汉字,或者其他国语言,以什么编码来存储 2,输出的时候,要给内容指定编码,如以网页的形势输入时<meta http-equiv ...
- 为sublime安装package control 解决乱码问题 Mac版
为sublime安装package control Mac版参考 https://sublime.wbond.net/installation 防止中文乱码其实只需要2个东东 一个GBK enc ...
随机推荐
- Business Unit Helper
using System; using System.Linq; using Microsoft.Xrm.Sdk; using Microsoft.Crm.Sdk.Messages; using Sy ...
- SQL基于时间的盲注过程
0x00 前言 由于要使用到基于时间的盲注,但是我觉得基于时间的盲注其实就是基于布尔的盲注的升级版,所以我想顺便把基于布尔的盲注分析总结了: 首先我觉得基于时间的盲注和基于布尔的盲注的最直观的差别就是 ...
- sqlserver之on与where条件
在进行两个表乃至多个表进行联接时需要on条件进行匹配,很多时候我们会对过滤条件放在on还是where中心存疑惑.一般来讲,在外联接中on是两个表进行关联的匹配条件,在该条件匹配下会生成一个虚拟表. 如 ...
- 数据结构与算法之Stack(栈)——in dart
用dart 语言实现一个简单的stack(栈).栈的内部用List实现. class Stack<E> { final List<E> _stack; final int ca ...
- Docker入门篇(一)之docker基础
1.Docker 架构 http://blog.csdn.net/u012562943/article/category/6048991/1Docker 使用客户端-服务器 (C/S) 架构模式,使用 ...
- java Cannot resolve constructor 不能解析构造函数
这个报错是因为构造函数要求传入的变量或对象等,必须在调用时传入,否则就无法解析构造函数,这跟调用方法必须把参数传齐了一个道理
- Struts 2(八):文件上传
第一节 基于Struts 2完成文件上传 Struts 2框架中没有提供文件上传,而是通过Common-FileUpload框架或COS框架来实现的,Struts 2在原有上传框架的基础上进行了进一步 ...
- Spark实施备忘
AttributeError: 'SparkConf' object has no attribute '_get_object_id' 初始化SparkContext时出现这种错误是因为把Spark ...
- mysql增删改查、连表查询、常用操作
一.建表 1.最简单的建表CREATE TABLE user(id int,name char(20),age int); 2.带主键带注释和默认值创建表CREATE TABLE user(id I ...
- object-fix/object-position
今日浏览某大神的一篇博文时发现如下写法: .container > div > img { width: 100%; height: 100%; object-fit: cover; } ...