【RL系列】马尔可夫决策过程——Jack‘s Car Rental
本篇请结合课本Reinforcement Learning: An Introduction学习
Jack's Car Rental是一个经典的应用马尔可夫决策过程的问题,翻译过来,我们就直接叫它“租车问题”吧。租车问题的描述如下:
Jack’s Car Rental Jack manages two locations for a nationwide car rental company. Each day, some number of customers arrive at each location to rent cars. If Jack has a car available, he rents it out and is credited $10 by the national company. If he is out of cars at that location, then the business is lost.
Cars become available for renting the day after they are returned. To help ensure that cars are available where they are needed, Jack can move them between the two locations overnight, at a cost of $2 per car moved.
We assume that the number of cars requested and returned at each location are Poisson random variables, where λ is the expected number.
Suppose λ is 3 and 4 for rental requests at the first and second locations and 3 and 2 for returns.
To simplify the problem slightly, we assume that there can be no more than 20 cars at each location (any additional cars are returned to the nationwide company, and thus disappear from the problem) and a maximum of five cars can be moved from one location to the other in one night. We take the discount rate to be γ = 0.9 and formulate this as a continuing finite MDP, where the time steps are days, the state is the number of cars at each location at the end of the day, and the actions are the net numbers of cars moved between the two locations overnight.
简单描述一下:
Jack有两个租车点,1号租车点和2号租车点,每个租车点最多可以停放20辆车。Jack每租车去一辆车可以获利10美金,每天租出去的车与收回的车的数量服从泊松分布。每天夜里,Jack可以在两个租车点间进行车辆调配,每晚最多调配5辆车,且每辆车花费2美金。1号租车点租车数量服从$ \lambda = 3 $的泊松分布,回收数量的$ \lambda = 3 $。二号租车点的租车数量和回收数量的$ \lambda $分别为4和2,试问使用什么样的调配策略可以使得盈利最优化(注意:这里的租车行为与回收行为是强制性的,是不可选择的)。
简单分析一下,每个租车点最多20辆车,那么状态数量就是21*21 = 441个。最多调配5辆车,那么动作集合A = {(-5, 5), (-4, 4),...,(0, 0), (1, -1),...,(5, -5)},动作集合A中的元素表示方法为(1号租车点出入车辆,2号租车点出入车辆),正负号分别表示“入”和“出”。
奖励期望的计算
首先来看一下动作奖励期望如何计算, 我们以动作后状态,1号租车点有10辆车为例:
可以肯定的是当前状态S1经过Action选择后的状态是唯一的,也就说对所有的未来可能状态来说$ P(s'|a, s) = 1 $。我们先不考虑由动作影响而造成的负收益(调配车辆的花费),而是着重计算,不论任何一个动作,只要到达状态“1号租车点有10辆车”所获得的收益期望,这样再减去每个动作引起的调配车辆的费用,就是该动作的奖励期望。
考虑状态“1号租车点有10辆车”的未来可能获得收益需要分析在保有10辆车的情况下的租(Rent)与回收(Return)的行为。计算该状态收益的过程实际上是另外一个动作策略符合泊松分布的马尔可夫决策过程。我们将1天内可能发生的Rent与Return行为记录为[#Return #Rent],其中“#Return”表示一天内回收的车辆数,“#Rent”表示租出的的车辆数,设定这两个指标皆不能超过20(理论上来说,进出车辆并不发生在同一时间,这两个指标实际为流量指标,状态每刻不超过20辆即可,但这样有违该题的初衷,且在$ \lambda = 3 $的情况下并没有太大意义,所以直接这样规定了)。假设当天早上,1号租车点里有10辆车,那么在傍晚清点的时候,可能保有的车辆数为0~20辆。如果傍晚关门歇业时还剩0辆车,那么这一天的租收行为$ A_{rt, rn} $可以是:
$$ A_{rt,rn} = \left[\begin{matrix}10 & 0\\ 11 & 1\\12& 2\\...&...\\20 & 10 \end{matrix} \right] $$
可以确定的是,Rent与Return是相互独立的行为或事件且皆服从泊松分布,所以要计算某个行为出现的概率直接将$ P(A_{rt}) $与$ P_(A_{rn}) $相乘就行了,但这里要计算的是条件概率,即为$ P(A_{rt,rn}|S'' = 0) $,所以还需要再与$ P(S'' = 0) $相除,这里的$ P(S'' = 0) $指的是傍晚清点时还剩0辆车的概率。各个租收行为所获得的收益是以租出去的车辆数为准,所以当傍晚还剩0辆车时,这一天的收益期望可以写为:
$$ R(S' = 10|S'' = 0) = 10\left[\begin{matrix} \frac{P(A_{rt} = 10)P(A_{rn} = 0)}{P(S'' = 0)} \\...\\ \frac{P(A_{rt} = 20)P(A_{rn} = 10)}{P(S'' = 0)} \end{matrix} \right]^T \left[\begin{matrix} 10\\11\\...\\20 \end{matrix} \right] $$
其中$ P(S'' = 0) $可以写为:
$$ P(S'' = 0) = \sum P(A_{rt})P(A_{rn}) $$
在计算出矩阵$ R(S' = 10|S'' = {0, 1,...,20}) $后,在进行加权平均,即可得到状态“1号租车点有10辆车”的奖励期望$ R(S' = 10) $
$$ R(S' = 10) = P(S'' = {0, 1,..., 20}) R^T(S' = 10|S'' = 0)$$
两个租车点,所有的状态按上述方法计算后,即可得出两个租车点的奖励矩阵$\begin{matrix} [R_1(S') & R_2(S')] \end{matrix}$。在计算出奖励矩阵后,这个问题就变成了bandit问题的变种,bandit问题是一个动作固定对应一个未来的状态,而这里虽然也是这样,不过所对应的状态却要以当前状态为基础进行计算得出,还是有些不同,所以称为bandit问题的一个变种。
基本算法——Policy-Evaluation & Policy-Improvement
这里所用到的主要解决方法为动态编程(DP)里的Policy-Evaluation和Policy-Improvement,我会先用Policy-Evaluation + Softmax求解一次,再用Policy-Evaluation + Policy-Improvement求解一次。这里先给出Policy-Evaluation + Softmax的算法流程:
- 计算奖励矩阵,初始化Q矩阵和V矩阵
- 进入迭代循环
- 将当前状态转变为1号与2号租车点的保有车辆数[#Car1 #Car2]
- 带入动作集合计算找出可能的未来状态S’与可执行的动作PossibleAction
- 用式子$ Q(S, \mathrm{Possible\ Action}) = R_1(S') + R_2(S') - 2\mathrm{Cost}(Possible\ Action) + \gamma V(S')$计算Q矩阵
- 用式子$ V(S) = \pi(S, A)Q^T(S) $更新V矩阵
- Softmax优化$ \pi(S, A) $: $$ \pi(S) = \frac{\exp{Q(S)}}{\sum \exp(Q(S, A))} $$
- 计算收敛程度,如果已收敛,退出循环;未收敛,继续迭代循环
Policy-Evaluation + Softmax的特点是将Softmax优化动作选择策略嵌入到迭代过程中去,这样好处是可以迅速的计算出较优的动作选择策略(在V值收敛之前),但不能保证是最优的。这中方法实际上叫Value-Iteration,是一种有策略的自更新policy的算法,大的框架还是policy-evaluation的,这一点并没有太大改变。
Policy-Improvement是将已有的动作选择策略$\pi(S, A)$和V矩阵带入与最优值进行比较,从而将$\pi(S, A)$跟新为最优。下面我们来看Policy-Improvement的算法流程,再将其与Policy-Evaluation结合起来:
- 初始化Q矩阵,将计算好的V矩阵与策略$ \pi(S, A) $带入状态循环中(每一个状态计算一遍)
- 将当前状态转变为1号与2号租车点的保有车辆数[#Car1 #Car2]
- 带入动作集合计算找出可能的未来状态S’与可执行的动作PossibleAction
- 用式子$ Q(S, \mathrm{Possible\ Action}) = R_1(S') + R_2(S') - 2\mathrm{Cost}(Possible\ Action) + \gamma V(S')$计算Q矩阵
- 用策略$\pi(S, A)$与$ Q_{max} $所在的动作进行比较,若是不符则令一个flag:Policy_Stable = False
Policy-Evaluation + Policy-Improvement算法:
- 计算奖励矩阵,初始化Q矩阵与V矩阵
- 判断Policy_Stable是否为False,如为True则输出结果$\pi(S,A)$,如为False则进入迭代循环过程。
- 令Policy_Stable = True
- 执行Policy-Evaluation算法
- 执行Policy-Improvement算法,得到Policy_Stable的结果,返回第2步
结果与评价
下面这幅图表示出了Policy-Improvement策略进化的过程,直到第5次迭代,动作策略最终稳定为最优策略。在这幅图中,横轴表示2号租车点的车辆保有量,纵轴表示1号租车点的车辆保有量,图上的颜色由蓝到绿到黄表示了车辆调配的策略,正负号分别表示从1号调出车辆到2号,从2号调出车辆到1号。
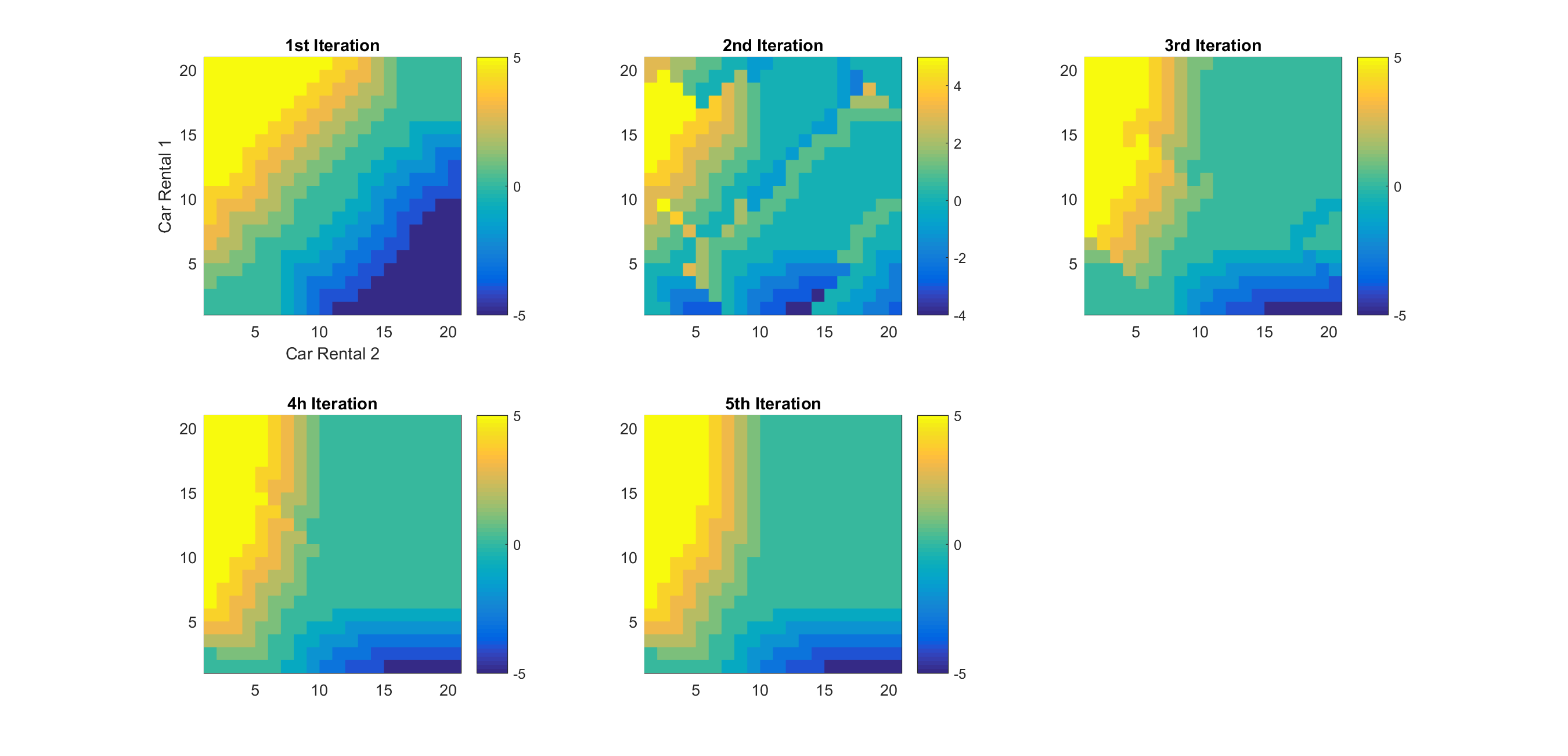
从第1次迭代的策略到第5次迭代的策略分别去测试Jack平均每日的实际收益,测试以10000日为基准(我并不是很清楚这里的第三次迭代的结果为何比第四次还要好,但最终的稳定后的策略是最优的):
| 迭代次数 | 实际每日收益 |
| 0(无策略) | $38 |
| 1 | $42.5 |
| 2 | $43.7 |
| 3 | $44.9 |
| 4 | $44.3 |
| 5 | $45.2 |
【RL系列】马尔可夫决策过程——Jack‘s Car Rental的更多相关文章
- 【RL系列】马尔可夫决策过程——状态价值评价与动作价值评价
请先阅读上两篇文章: [RL系列]马尔可夫决策过程中状态价值函数的一般形式 [RL系列]马尔可夫决策过程与动态编程 状态价值函数,顾名思义,就是用于状态价值评价(SVE)的.典型的问题有“格子世界(G ...
- 【RL系列】马尔可夫决策过程中状态价值函数的一般形式
请先阅读上一篇文章:[RL系列]马尔可夫决策过程与动态编程 在上一篇文章里,主要讨论了马尔可夫决策过程模型的来源和基本思想,并以MAB问题为例简单的介绍了动态编程的基本方法.虽然上一篇文章中的马尔可夫 ...
- [Reinforcement Learning] 马尔可夫决策过程
在介绍马尔可夫决策过程之前,我们先介绍下情节性任务和连续性任务以及马尔可夫性. 情节性任务 vs. 连续任务 情节性任务(Episodic Tasks),所有的任务可以被可以分解成一系列情节,可以看作 ...
- 增强学习(二)----- 马尔可夫决策过程MDP
1. 马尔可夫模型的几类子模型 大家应该还记得马尔科夫链(Markov Chain),了解机器学习的也都知道隐马尔可夫模型(Hidden Markov Model,HMM).它们具有的一个共同性质就是 ...
- 【cs229-Lecture16】马尔可夫决策过程
之前讲了监督学习和无监督学习,今天主要讲“强化学习”. 马尔科夫决策过程:Markov Decision Process(MDP) 价值函数:value function 值迭代:value iter ...
- 强化学习-MDP(马尔可夫决策过程)算法原理
1. 前言 前面的强化学习基础知识介绍了强化学习中的一些基本元素和整体概念.今天讲解强化学习里面最最基础的MDP(马尔可夫决策过程). 2. MDP定义 MDP是当前强化学习理论推导的基石,通过这套框 ...
- David Silver强化学习Lecture2:马尔可夫决策过程
课件:Lecture 2: Markov Decision Processes 视频:David Silver深度强化学习第2课 - 简介 (中文字幕) 马尔可夫过程 马尔可夫决策过程简介 马尔可夫决 ...
- 马尔可夫决策过程MDP
1. 马尔可夫模型的几类子模型 马尔科夫链(Markov Chain),了解机器学习的也都知道隐马尔可夫模型(Hidden Markov Model,HMM).它们具有的一个共同性质就是马尔可夫性(无 ...
- 转:增强学习(二)----- 马尔可夫决策过程MDP
1. 马尔可夫模型的几类子模型 大家应该还记得马尔科夫链(Markov Chain),了解机器学习的也都知道隐马尔可夫模型(Hidden Markov Model,HMM).它们具有的一个共同性质就是 ...
随机推荐
- 25条提高iOS App性能的技巧和诀窍
25条提高iOS App性能的技巧和诀窍 当我们开发iOS应用时,好的性能对我们的App来说是很重要的.你的用户也希望如此,但是如果你的app表现的反应迟钝或者很慢也会伤害到你的审核. 然而,由于IO ...
- 【mySQL】 - 主键
什么是主键? 对于表中的每一行数据,都会有一个字段或一组字段,用于标识自己的唯一性,这样的一个或一组字段,就叫主键 如果没有这个主键,那么对于表中的每一行的管理,会陷入混乱,我要更新某一特定行的数值, ...
- C++练习 | 在递增序列中查找最后一个小于等于指定数的元素
#include <iostream> using namespace std; int mid,l0; int solve(int a1[],int l,int r,int x) { & ...
- 网络的可靠性nyoj170
网络的可靠性 时间限制:3000 ms | 内存限制:65535 KB 难度:3 描述 A公司是全球依靠的互联网解决方案提供商,也是2010年世博会的高级赞助商.它将提供先进的网络协作技术,展 ...
- 【postgresql的使用】
#安装: #初始化: #允许远程登录: #创建数据库并指定用户 #创建用户 #列出数据库 #进入数据库 #查询数据 #or(或)查询 #and ,or(和,或查询) #表连接 #内,外(左右),交叉连 ...
- 【JVM】TroubleShooting之内存溢出异常(OOM)与调优
1. OOM概述 If your application's execution time becomes longer and longer, or if the operating system ...
- 使用HtmlAgilityPack将HtmlTable填入DataTable
HtmlAgilityPack.HtmlWeb hw = new HtmlAgilityPack.HtmlWeb(); HtmlAgilityPack.HtmlDocument doc = hw.Lo ...
- 20155224 2016-2017-2 《Java程序设计》第3周学习总结
20155224 2016-2017-2 <Java程序设计>第3周学习总结 教材学习内容总结 本周学习量比前两周大,代码量也比较多,还出现了挺多术语,都要慢慢查. 第四章 第四章主要学习 ...
- 20155235 2016-2017-2 《Java程序设计》第十周学习总结
20155235 2016-2017-2 <Java程序设计>第十周学习总结 教材学习内容总结 计算机网络 计算机网络由若干结点和连接这些结点的链路组成.网络中的结点可以是计算机.集线器. ...
- 2016-2017-2 20155339《 java面向对象程序设计》实验四Android程序设计
2016-2017-2 20155339< java面向对象程序设计>实验四Android程序设计 实验内容 1.Android Stuidio的安装测试: 参考<Java和Andr ...