Kettle学习系列之数据仓库、数据整合、ETL、ELT和EII之间的区别?
不多说,直接上干货!
在数据仓库领域里,的一个重要概念就是数据整合(data intergration)。数据整合它就是把不同数据库中的数据整合到一起,对外提供统一的数据视图。
数据整合最典型的案例就是整合存货数据和订单数据。数据整合的另一个案例就是把各个部门的客户关系管理系统中的客户信息整合到公司客户关系管理系统中。
数据整合是一个比ETL更加广泛的概念,ETL是指从一个或多个数据源抽取数据,经过一个或多个转换步骤后,物理地存储到目标环境中,目标环境通常是数据仓库。
ETL是data integration中的一种而已。
1、抽取:一般抽取过程需要连接到不同的数据源,以便为随后的步骤提供数据。这一部分看上去简单而繁琐,实际上它是ETL解决方案成功实施的一个主要障碍。
2、转换:在抽取和加载之间的,任何对数据的处理过程都是需要转换。这些处理过程通常包括(但不局限于)下面的这些操作:
移动数据
根据规则验证数据
数据内容和数据结构的修改
集成多个数据源的数据
根据处理后的数据计算派生值和聚集值
3、加载:将数据加载到目标系统的所有操作。
一图胜千言!
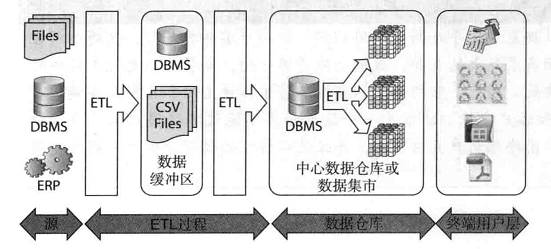
数据仓库典型架构图
在上图中,有多个业务源系统,一个数据中转区,一个保存了所有历史数据的数据仓库和多个可以由终端用户访问的数据集市。
这些组成部分都是由数据整合过程来完成的,就是上图中显示的ETL。
在源系统和数据仓库之间,有一个数据中转区,也可以叫做数据缓冲区。它仅用来快速地从源数据系统中获取数据,并暂时保留这些数据。它不一定是一个数据仓库,在很多情况下,将数据保存在ASCII文件中比插入数据库表中还要快。
ELT和ETL的区别
ELT,(即抽取、加载和转换的简称),在同ETL在数据整合的方法上有略微不同。在ETL的情况下,数据首先从源数据(可能是多个)进行抽取、加载到目标数据库中,再转换为所需的格式。所有大数据量处理全部放在目标数据库中进行。这种做法的好处在于,一般情况下,数据库系统更适合处理负荷在百万级以上的数据集成。
ELT工具需要知道,如何使用目标数据库平台和相应的SQL语言。这就是在市面ELT解决方案较少的原因,类似Kettle这样的通用ETL工具也同样缺少这些功能。
EII是虚拟数据整合,为什么要提出呢?因为啊,ETL和ELT都属于物理数据整合。即都是以物理方式将数据从OLTP移动或复制到数据仓库。
有些情况啊,没有必要移动或复制数据。实际上,大多数用户并不关心ETL过程和数据仓库:他们只是想获得他们想要的数据!好比,我把上图比喻成饭店的厨房吧,我作为一个顾客并不关心饭菜是如何做出的,我只是希望能准时并且味道口可就行,什么厨房里发生事情跟我顾客身份无关。
那么,这个生活里的道路,也适合在数据仓库里:即有些用户并不关心数据是如何处理的,他们紫红色想快速而容易访问到数据就行。
即,除了属于物理数据集成方式里的ETL和ELT外,还有属于虚拟数据集成方式的EII。
虚拟数据集成和物理数据集成的比较

当然,我这系列博客,是定位于Kettle,目前最流行、功能最强大的数据整合工具是Kettle,也被称为Pentaho Data Integration。
同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/ http://www.cnblogs.com/sunnyDream/
详情请见:http://www.cnblogs.com/zlslch/p/7473861.html
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
对应本平台的讨论和答疑QQ群:大数据和人工智能躺过的坑(总群)(161156071)![]()
![]()
![]()
![]()
![]()



Kettle学习系列之数据仓库、数据整合、ETL、ELT和EII之间的区别?的更多相关文章
- 大数据学习系列之九---- Hive整合Spark和HBase以及相关测试
前言 在之前的大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 中介绍了集群的环境搭建,但是在使用hive进行数据查询的时候会非常的慢,因为h ...
- Kettle学习系列之Kettle能做什么?(三)
不多说,直接上干货! PDI(Kettle) 都能做什么? 可以说凡是有数据整合.转换.迁移的场景都可以使用PDI,他代替了完成数据转换任务的手工编码,降低了开发难度. 同时,我们可以在自己实际业务里 ...
- PyQt(Python+Qt)学习随笔:QTextEdit的setText、setHtml、setPlainText之间的区别
专栏:Python基础教程目录 专栏:使用PyQt开发图形界面Python应用 专栏:PyQt入门学习 老猿Python博文目录 QTextEdit中提供了三个设置编辑器文本的方法,分别是setTex ...
- Kettle学习系列之Kettle的起源
不多说,直接上干货! Kettle起源于十年以前,本世纪初.当时啊,ETL工具千姿百态,比较流行的工具有50个左右,ETL框架数量比工具还要多些. 根据这些工具的各自起源和功能可以分为以下4种类型,如 ...
- Kettle学习系列之kettle的下载、安装和初步使用(windows平台下)(图文详解)
不多说,直接上干货! kettle的下载 Kettle可以在http://kettle.pentaho.org/网站下载 http://sourceforge.n ...
- Caffe学习系列(13):数据可视化环境(python接口)配置
caffe程序是由c++语言写的,本身是不带数据可视化功能的.只能借助其它的库或接口,如opencv, python或matlab.大部分人使用python接口来进行可视化,因为python出了个比较 ...
- ClickHouse学习系列之八【数据导入迁移&同步】
背景 在介绍了一些ClickHouse相关的系列文章之后,大致对ClickHouse有了比较多的了解.它是一款非常优秀的OLAP数据库,为了更好的来展示其强大的OLAP能力,本文将介绍一些快速导入大量 ...
- Caffe学习系列(2):数据层及参数
要运行caffe,需要先创建一个模型(model),如比较常用的Lenet,Alex等, 而一个模型由多个屋(layer)构成,每一屋又由许多参数组成.所有的参数都定义在caffe.proto这个文件 ...
- 转 Caffe学习系列(2):数据层及参数
http://www.cnblogs.com/denny402/p/5070928.html 要运行caffe,需要先创建一个模型(model),如比较常用的Lenet,Alex等, 而一个模型由多个 ...
随机推荐
- Visual Studio2013下Magick++配置方法
声明:本文系作者原创,如需转载请保持文章完整并注明出处(http://blog.csdn.net/u010281174/article/details/52224829). ImageMagick是一 ...
- MS SQL 获取数据字典的经典sql语句
select [表名]=c.Name, [表说明]=isnull(f.[value],''), [列名]=a.Name, [列序号]=a.Column_id, [标识]=case when is_id ...
- 用endnote导入bib
首先一般时候需要把IEEE的style包导入. https://endnote.com/downloads/styles/ 具体方法可参考http://muchong.com/html/201006/ ...
- Kattis - How Many Digits?
How Many Digits? Often times it is sufficient to know the rough size of a number, rather than its ex ...
- Linux基础、常用命令
Linux作为IT程序员必知必会知识,将自己学习到的和最近工作常用的一些命令进行总结,作为我结束过去生活和开始类程序员的序吧! 如果你想系统性学习的话,还是建议看书(鸟哥的Linux私房菜)或网上视频 ...
- CF949A Zebras 构造
是一道不错的构造题. 我们观察,一个 111 的前后必须都有 000. 那么,我们开一个二维数组 (vector)(vector)(vector),这样每遇到一个 000 就将 000 加入到当前的 ...
- jq——css类
1 addClass(classname) 添加类 <script type="text/javascript"> $("input").clic ...
- [转载] Linux新手必看:浅谈如何学习linux
本文转自 https://www.cnblogs.com/evilqliang/p/6247496.html 本文在Creative Commons许可证下发布 一.起步 首先,应该为自己创造一个学习 ...
- C/C++中的段错误(Segmentation fault)[转]
Segment fault 之所以能够流行于世,是与Glibc库中基本所有的函数都默认型参指针为非空有着密切关系的. 来自:http://oss.lzu.edu.cn/blog/article.php ...
- Python-基础-day6
1.二进制 前言:计算机一共就能做两件事:计算和通信 2.字符编码 生活中的数字要想让计算机理解就必须转换成二进制.十进制到二进制的转换只能解决计算机理解数字的问题,那么文字要怎么让计算机理解呢? 于 ...