hdfs深入:03、hdfs的架构以及副本机制和block块存储
HDFS分布式文件系统设计目标
1、 硬件错误 由于集群很多时候由数量众多的廉价机组成,使得硬件错误成为常态
2、 数据流访问 所有应用以流的方式访问数据,设置之初便是为了用于批量的处理数据,而不是低延时的实时交互处理
3、 大数据集 典型的HDFS集群上面的一个文件是以G或者T数量级的,支持一个集群当中的文件数量达到千万数量级
4、 简单的相关模型 假定文件是一次写入,多次读取的操作
5、 移动计算比移动数据便宜 一个应用请求的计算,离它操作的数据越近,就越高效
6、 多种软硬件的可移植性
3、HDFS的来源
HDFS起源于Google的GFS论文(GFS,Mapreduce,BigTable为google的旧的三驾马车)
发表于2003年10月
HDFS是GFS的克隆版
Hadoop Distributed File system
易于扩展的分布式文件系统
运行在大量普通廉价机器上,提供容错机制
为大量用户提供性能不错的文件存取服务
4、HDFS的架构图之基础架构
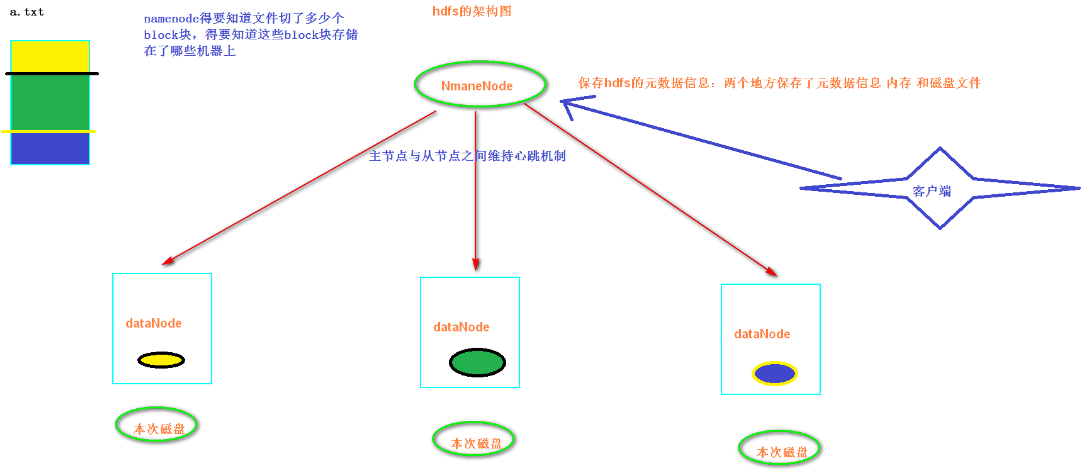
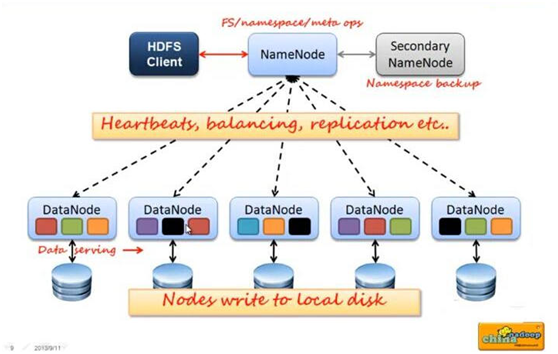
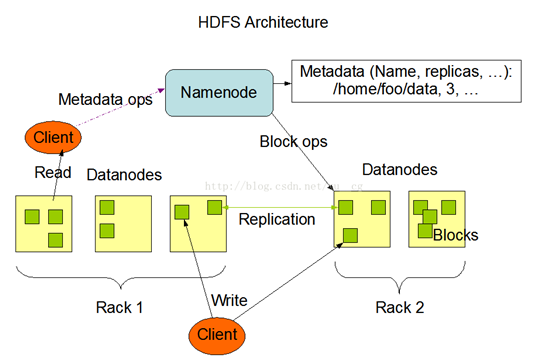
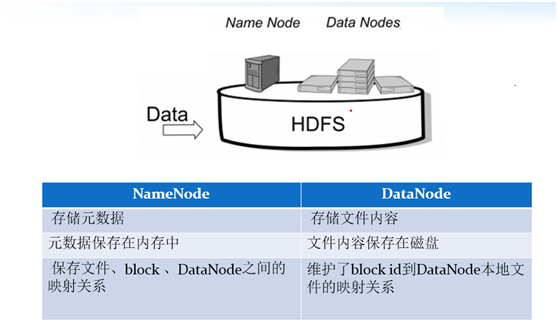
1、NameNode是一个中心服务器,单一节点(简化系统的设计和实现),负责管理文件系统的名字空间(namespace)以及客户端对文件的访问
2、文件操作,namenode是负责文件元数据的操作,datanode负责处理文件内容的读写请求,跟文件内容相关的数据流不经过Namenode,只询问它跟哪个dataNode联系,否则NameNode会成为系统的瓶颈
3、副本存放在哪些Datanode上由NameNode来控制,根据全局情况作出块放置决定,读取文件时NameNode尽量让用户先读取最近的副本,降低读取网络开销和读取延时
4、NameNode全权管理数据库的复制,它周期性的从集群中的每个DataNode接收心跳信号和状态报告,接收到心跳信号意味着DataNode节点工作正常,块状态报告包含了一个该DataNode上所有的数据列表
注:元数据不仅保存在内存中,还保存一份在磁盘中,防止意外断电等导致数据丢失。
5、hdfs的架构之文件的文件副本机制以及block块存储
block块的大小可以通过hdfs-site.xml当中的配置文件进行指定:
<property>
<name>dfs.blocksize</name>
<value>块大小 以Byte字节为单位</value>//只写数值就可以 默认:134217728B,即128MB
</property>
<property>
<name>dfs.replication</name>
<value>3</value> //block的副本数量设置
</property>
5.1、抽象成数据块的好处
- 一个文件有可能大于集群中任意一个磁盘
10T*3/128 = xxx块 2T,2T,2T 文件方式存—–>多个block块,这些block块属于一个文件 - 使用块抽象而不是文件可以简化存储子系统
- 块非常适合用于数据备份进而提供数据容错能力和可用性
5.2、块缓存
block块缓存:可以将我们的block块缓存到内存当中,我们在执行一些MR计算的时候,可以直接从内存当中获取数据,比较快,特别适用于一些小表join大表的情况。
5.3、hdfs的文件权限验证
hdfs的权限验证:采用的是linux类似的权限校验机制,防止好人做错事,不能阻止坏人干干事,hdfs相信你告诉我你是谁,你就是谁。
hdfs深入:03、hdfs的架构以及副本机制和block块存储的更多相关文章
- 大数据:Hadoop(HDFS 的设计思路、设计目标、架构、副本机制、副本存放策略)
一.HDFS 的设计思路 1)思路 切分数据,并进行多副本存储: 2)如果文件只以多副本进行存储,而不进行切分,会有什么问题 缺点 不管文件多大,都存储在一个节点上,在进行数据处理的时候很难进行并行处 ...
- HDFS 02 - HDFS 的机制:副本机制、机架感知机制、负载均衡机制
目录 1 - HDFS 的副本机制 2 - HDFS 的机架感知机制 3 - HDFS 的负载均衡机制 参考资料 版权声明 1 - HDFS 的副本机制 HDFS 中的文件,在物理上都是以分块(blo ...
- HDFS副本机制&负载均衡&机架感知&访问方式&健壮性&删除恢复机制&HDFS缺点
副本机制 1.副本摆放策略 第一副本:放置在上传文件的DataNode上:如果是集群外提交,则随机挑选一台磁盘不太慢.CPU不太忙的节点上:第二副本:放置在于第一个副本不同的机架的节点上:第三副本:与 ...
- HDFS原理解析(总体架构,读写操作流程)
前言 HDFS 是一个能够面向大规模数据使用的,可进行扩展的文件存储与传递系统.是一种允许文件通过网络在多台主机上分享的文件系统,可让多机器上的多用户分享文件和 存储空间.让实际上是通过网络来访问文件 ...
- HDFS原理解析(整体架构,读写操作流程及源代码查看等)
前言 HDFS 是一个能够面向大规模数据使用的.可进行扩展的文件存储与传递系统.是一种同意文件通过网络在多台主机上分享的文件系统,可让多机器上的多用户分享文件和存储空间.让实际上是通过网络来訪问文件的 ...
- HDFS之四:HDFS原理解析(总体架构,读写操作流程)
前言 HDFS 是一个能够面向大规模数据使用的,可进行扩展的文件存储与传递系统.是一种允许文件通过网络在多台主机上分享的文件系统,可让多机器上的多用户分享文件和 存储空间.让实际上是通过网络来访问文件 ...
- HDFS怎样检測并删除多余副本块
前言 在HDFS中,每时每刻都在进行着大量block块的创建和删除操作,这些庞大的block块构建起了这套复杂的分布式系统.普通block的读写删除操作一般人都或多或少了解过一些,可是过量的副本清理机 ...
- 03 HDFS的客户端操作
服务器和客户端的概念 hdfs的客户端有多种形式 1.网页形式 2.命令行形式 3.客户端在哪里运行,没有约束,只要运行客户端的机器能够跟hdfs集群联网 参数配置 文件的切块大小和存储的副本数量,都 ...
- HDFS Federation与HDFS High Availability详解
HDFS Federation NameNode在内存中保存文件系统中每个文件和每个数据块的引用关系,这意味着对于一个拥有大量文件的超大集群来说,内存将成为限制系统横向扩展的瓶颈.在2.0发行版本系列 ...
随机推荐
- [转]json.dumps和json.loads区别
原文json.dumps loads 终于区分出来了 原来每次遇到json loads/dumps始终搞不清方向,写段代码试下: [python] view plain copy print? imp ...
- 【练习】Java实现的杨辉三角形控制台输出
import java.util.Scanner; /** * YangHui_tst01 * @author HmLy * @version 000 * - - - - - - - * 练习代码.( ...
- 进击的Python【第十一章】:消息队列介绍、RabbitMQ&Redis的重点介绍与简单应用
消息队列介绍.RabbitMQ.Redis 一.什么是消息队列 这个概念我们百度Google能查到一大堆文章,所以我就通俗的讲下消息队列的基本思路. 还记得原来写过Queue的文章,不管是线程queu ...
- ROS学习笔记十:URDF详解
Unified Robot Description Format,简称为URDF(标准化机器人描述格式),是一种用于描述机器人及其部分结构.关节.自由度等的XML格式文件. 一.URDF语法规范 参见 ...
- ACboy needs your help HDU - 1712
ACboy needs your help HDU - 1712 ans[i][j]表示前i门课共花j时间最大收益.对于第i门课,可以花k(0<=k<=j)时间,那么之前i-1门课共花j- ...
- 链表中用标兵结点简化代码 分类: c/c++ 2014-09-29 23:10 475人阅读 评论(0) 收藏
标兵结点(头结点)是在链表中的第一个结点,不存放数据,仅仅是个标记 利用标兵结点可以简化代码.下面实现双向链表中的按值删除元素的函数,分别实现 带标兵结点和不带标兵结点两版本,对比可见标兵结点的好处. ...
- string.Format 中不能包含{}字符串
string scss = @"<style type=""text/css""> body{ margin-left: {0}px; m ...
- andorid IOS 判断APP下载
<?phpif(strpos($_SERVER['HTTP_USER_AGENT'], 'iPhone')||strpos($_SERVER['HTTP_USER_AGENT'], 'iPad' ...
- js类、原型——学习笔记
js 内置有很多类,我们用的,都是从这些类实例化出来的. function Object () {} function Array () {} function String () {} functi ...
- EditText自动弹出软键盘
editText.requestFocus() editText.isFocusable = true editText.isFocusableInTouchMode = true val timer ...