Akka源码分析-Persistence
在学习akka过程中,我们了解了它的监督机制,会发现actor非常可靠,可以自动的恢复。但akka框架只会简单的创建新的actor,然后调用对应的生命周期函数,如果actor有状态需要回复,我们需要hook对应的生命周期函数,自己恢复状态。但此时恢复的只是初始状态,如果actor在接收消息过程中,状态发生了变化,为了保证可恢复就需要我们自行把状态保存在第三方组件了。考虑到通用性以及Actor模型的特点,akka提供了持久化机制,可以帮助我们做状态恢复。
其实,actor的状态千差万别,怎么来统一恢复模型呢?比如有些场景下,actor的状态是一个整数,有些则是负责的类型。akka Persistence并没有直接保存actor的状态,而是另辟蹊径,保存了actor接收到的消息,在actor重启时,把接收到的所有消息重新发送给actor,由actor自己决定如何构建最新的状态。这其实就是事件溯源的典型应用,结合Actor模型,简直是完美。
在分析akka Persistence源码之前,我们先来介绍一下这个框架涉及到的几个重要概念。
PersistentActor。是一个持久化、有状态actor的trait。它可以持久化消息,并在actor重启时重放消息,以达到状态恢复的目的。
AtLeastOnceDelivery。至少一次机制。也就是至少发送一次消息给目标,没发成功咋办?当然是重发了啊。
AsyncWriteJournal。异步写日志。journal把发送给持久化actor的消息按照顺序存储。当然了,持久化actor是可以自定义需要存储的消息范围的。
Snapshot store。快照存储。如果actor收到的消息太多,在恢复的时候从头开始回放,会导致恢复时间过长。快照其实就是当前状态的截面,在恢复的时候,我们可以从最新的快照开始恢复,从而大大减少恢复的时间。
Event sourcing。事件溯源。akka对事件溯源应用开发提供了一个抽象,事件溯源提供了一种物化领域模型数据的持久化方式,它不直接存储最终状态,而是存储导致状态变化的事件,通过这些事件构建最终的状态。比如不直接记录账户的最终金额,而是记录账户的借贷记录(也就是+、-记录),通过这些借贷记录,计算最终的账户余额。
case class ExampleState(events: List[String] = Nil) {
def updated(evt: Evt): ExampleState = copy(evt.data :: events)
def size: Int = events.length
override def toString: String = events.reverse.toString
}
class ExamplePersistentActor extends PersistentActor {
override def persistenceId = "sample-id-1"
var state = ExampleState()
def updateState(event: Evt): Unit =
state = state.updated(event)
def numEvents =
state.size
val receiveRecover: Receive = {
case evt: Evt ⇒ updateState(evt)
case SnapshotOffer(_, snapshot: ExampleState) ⇒ state = snapshot
}
val snapShotInterval = 1000
val receiveCommand: Receive = {
case Cmd(data) ⇒
persist(Evt(s"${data}-${numEvents}")) { event ⇒
updateState(event)
context.system.eventStream.publish(event)
if (lastSequenceNr % snapShotInterval == 0 && lastSequenceNr != 0)
saveSnapshot(state)
}
case "print" ⇒ println(state)
}
}
上面是官网提供的一个持久化actor的demo。可以看到,非常简单,只需要继承PersistentActor,然后就可以调用persist持久化事件了,持久化成功之后可以进行响应的业务操作。actor重启的时候,就会把持久化的事件,发送给receiveRecover函数,进行状态恢复。那PersistentActor具体提供了哪些功能呢?又是如何实现的呢?
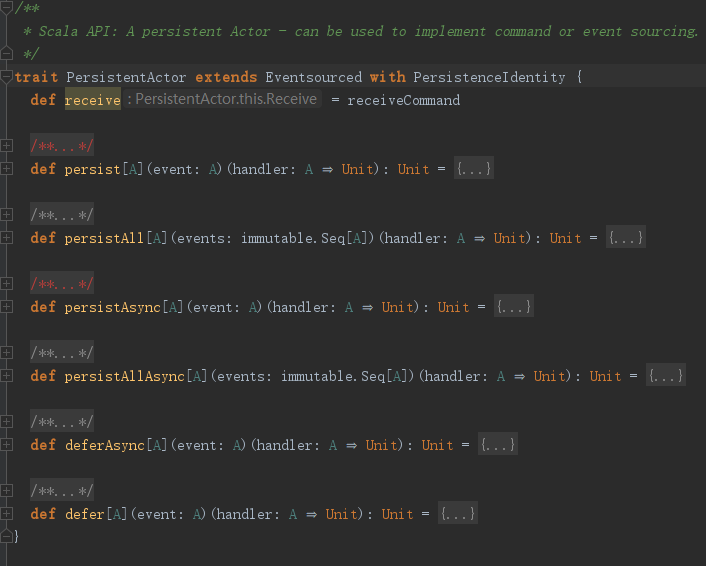
上面是PersistentActor这个trait的定义,大概有三类功能:恢复、持久化(同步、异步、同步批量、异步批量)、推迟(同步、异步)。当然这里说的同步、异步是针对持久化actor本身的,在调用persist时候,actor还是可以接收消息的,只不过会暂时被stash(可以理解成缓存),等最后一条消息持久化之后再开始处理后面的消息。
/**
* Asynchronously persists `event`. On successful persistence, `handler` is called with the
* persisted event. It is guaranteed that no new commands will be received by a persistent actor
* between a call to `persist` and the execution of its `handler`. This also holds for
* multiple `persist` calls per received command. Internally, this is achieved by stashing new
* commands and unstashing them when the `event` has been persisted and handled. The stash used
* for that is an internal stash which doesn't interfere with the inherited user stash.
*
* An event `handler` may close over persistent actor state and modify it. The `sender` of a persisted
* event is the sender of the corresponding command. This means that one can reply to a command
* sender within an event `handler`.
*
* Within an event handler, applications usually update persistent actor state using persisted event
* data, notify listeners and reply to command senders.
*
* If persistence of an event fails, [[#onPersistFailure]] will be invoked and the actor will
* unconditionally be stopped. The reason that it cannot resume when persist fails is that it
* is unknown if the event was actually persisted or not, and therefore it is in an inconsistent
* state. Restarting on persistent failures will most likely fail anyway, since the journal
* is probably unavailable. It is better to stop the actor and after a back-off timeout start
* it again.
*
* @param event event to be persisted
* @param handler handler for each persisted `event`
*/
def persist[A](event: A)(handler: A ⇒ Unit): Unit = {
internalPersist(event)(handler)
}
官方注释对persist方法解释的特别清楚,这个方法会异步的持久化消息,持久化成功之后会调用handler这个函数。在persist执行与handler调用之间,可以保证没有新的命令接收。持久化机制内部有一个stash机制,当然了,这不是继承的stash。在handler这个代码块中,sender还是原来命令的发送者,并不会因为异步的原因导致失效。为啥?接收到的所有命令都被stash了,你说为啥。
@InternalApi
final private[akka] def internalPersist[A](event: A)(handler: A ⇒ Unit): Unit = {
if (recoveryRunning) throw new IllegalStateException("Cannot persist during replay. Events can be persisted when receiving RecoveryCompleted or later.")
pendingStashingPersistInvocations += 1
pendingInvocations addLast StashingHandlerInvocation(event, handler.asInstanceOf[Any ⇒ Unit])
eventBatch ::= AtomicWrite(PersistentRepr(event, persistenceId = persistenceId,
sequenceNr = nextSequenceNr(), writerUuid = writerUuid, sender = sender()))
}
internalPersist创建StashingHandlerInvocation把它加入到pendingInvocations这列表尾部,然后又创建AtomicWrite添加到eventBatch这个list头部。从StashingHandlerInvocation这个命令来看,这是一个挂起的handler调用,也就是说会在合适的时间调用。AtomicWrite代表原子写入,表示事件要么全写入成功、要么全都写入失败,不存在中间状态,当然了,这在批量时比较有用,有点事务的概念,但并不是所有的持久化机制都支持。persist好像只是操作了几个list,那么handler什么时候会被调用呢?
@InternalApi
final private[akka] def internalPersistAll[A](events: immutable.Seq[A])(handler: A ⇒ Unit): Unit = {
if (recoveryRunning) throw new IllegalStateException("Cannot persist during replay. Events can be persisted when receiving RecoveryCompleted or later.")
if (events.nonEmpty) {
events.foreach { event ⇒
pendingStashingPersistInvocations += 1
pendingInvocations addLast StashingHandlerInvocation(event, handler.asInstanceOf[Any ⇒ Unit])
}
eventBatch ::= AtomicWrite(events.map(PersistentRepr.apply(_, persistenceId = persistenceId,
sequenceNr = nextSequenceNr(), writerUuid = writerUuid, sender = sender())))
}
}
internalPersistAll与internalPersist比较类似,就放一块分析了,internalPersistAll只不过一次性加入了多个元素而已。但我们还是不知道handler啥时候会被调用啊。其实这一点确实有点绕,需要我们仔细认真的通读源码才能找到蛛丝马迹。
override protected[akka] def aroundReceive(receive: Receive, message: Any): Unit =
currentState.stateReceive(receive, message)
在Eventsourced这个trait的方法列表中,有上面这段代码,我们知道aroundReceive是actor的一个钩子,在receive方法调用之前调用。
/**
* INTERNAL API.
*
* Can be overridden to intercept calls to this actor's current behavior.
*
* @param receive current behavior.
* @param msg current message.
*/
@InternalApi
protected[akka] def aroundReceive(receive: Actor.Receive, msg: Any): Unit = {
// optimization: avoid allocation of lambda
if (receive.applyOrElse(msg, Actor.notHandledFun).asInstanceOf[AnyRef] eq Actor.NotHandled) {
unhandled(msg)
}
}
默认实现就是调用receive方法,如果receive无法匹配对应的消息,则调用unhandled来处理。既然Eventsourced覆盖了aroundReceive,那就意味着aroundReceive在持久化过程中很重要,但是又简单的调用了currentState.stateReceive方法,说明currentState就很重要了。
// safely null because we initialize it with a proper `waitingRecoveryPermit` state in aroundPreStart before any real action happens
private var currentState: State = null
override protected[akka] def aroundPreStart(): Unit = {
require(persistenceId ne null, s"persistenceId is [null] for PersistentActor [${self.path}]")
require(persistenceId.trim.nonEmpty, s"persistenceId cannot be empty for PersistentActor [${self.path}]")
// Fail fast on missing plugins.
val j = journal;
val s = snapshotStore
requestRecoveryPermit()
super.aroundPreStart()
}
注释中说的也比较清楚,这个变量是在aroundPreStart中最先赋值的,而aroundPreStart又是Actor的一个生命周期hook。其实吧这个j和s变量的赋值,我是不喜欢的,居然用简单的赋值来初始化一个lazy val变量,进而判断对应的插件是否存在,真是恶心。
private def requestRecoveryPermit(): Unit = {
extension.recoveryPermitter.tell(RecoveryPermitter.RequestRecoveryPermit, self)
changeState(waitingRecoveryPermit(recovery))
}
这个方法给recoveryPermitter发送了一个RequestRecoveryPermit消息,然后修改状态为waitingRecoveryPermit。通过分析源码得知recoveryPermitter是一个RecoveryPermitter,这个actor在收到RequestRecoveryPermit消息后,会返回一个RecoveryPermitGranted消息。
/**
* Initial state. Before starting the actual recovery it must get a permit from the
* `RecoveryPermitter`. When starting many persistent actors at the same time
* the journal and its data store is protected from being overloaded by limiting number
* of recoveries that can be in progress at the same time. When receiving
* `RecoveryPermitGranted` it switches to `recoveryStarted` state
* All incoming messages are stashed.
*/
private def waitingRecoveryPermit(recovery: Recovery) = new State { override def toString: String = s"waiting for recovery permit" override def recoveryRunning: Boolean = true override def stateReceive(receive: Receive, message: Any) = message match {
case RecoveryPermitter.RecoveryPermitGranted ⇒
startRecovery(recovery) case other ⇒
stashInternally(other)
}
}
waitingRecoveryPermit返回了一个新的State,这个state的stateReceive有重新定义,我们知道当前持久化actor收到消息后会首先调用state的stateReceive,此时也就是调用waitingRecoveryPermit的stateReceive。所以RecoveryPermitGranted会按照上面源码的逻辑进行处理。此时recovery是默认的Recovery
/**
* Recovery mode configuration object to be returned in [[PersistentActor#recovery]].
*
* By default recovers from latest snapshot replays through to the last available event (last sequenceId).
*
* Recovery will start from a snapshot if the persistent actor has previously saved one or more snapshots
* and at least one of these snapshots matches the specified `fromSnapshot` criteria.
* Otherwise, recovery will start from scratch by replaying all stored events.
*
* If recovery starts from a snapshot, the persistent actor is offered that snapshot with a [[SnapshotOffer]]
* message, followed by replayed messages, if any, that are younger than the snapshot, up to the
* specified upper sequence number bound (`toSequenceNr`).
*
* @param fromSnapshot criteria for selecting a saved snapshot from which recovery should start. Default
* is latest (= youngest) snapshot.
* @param toSequenceNr upper sequence number bound (inclusive) for recovery. Default is no upper bound.
* @param replayMax maximum number of messages to replay. Default is no limit.
*/
@SerialVersionUID(1L)
final case class Recovery(
fromSnapshot: SnapshotSelectionCriteria = SnapshotSelectionCriteria.Latest,
toSequenceNr: Long = Long.MaxValue,
replayMax: Long = Long.MaxValue)
Recovery就是给状态恢复提供状态,其实吧,这应该改一个名字,叫RecoveryConfig比较合适。
private def startRecovery(recovery: Recovery): Unit = {
val timeout = {
val journalPluginConfig = this match {
case c: RuntimePluginConfig ⇒ c.journalPluginConfig
case _ ⇒ ConfigFactory.empty
}
extension.journalConfigFor(journalPluginId, journalPluginConfig).getMillisDuration("recovery-event-timeout")
}
changeState(recoveryStarted(recovery.replayMax, timeout))
loadSnapshot(snapshotterId, recovery.fromSnapshot, recovery.toSequenceNr)
}
startRecovery大概做了两件事,修改状态为recoveryStarted,然后调用loadSnapshot。recoveryStarted不分析,先来看看loadSnapshot。
/**
* Instructs the snapshot store to load the specified snapshot and send it via an [[SnapshotOffer]]
* to the running [[PersistentActor]].
*/
def loadSnapshot(persistenceId: String, criteria: SnapshotSelectionCriteria, toSequenceNr: Long): Unit =
snapshotStore ! LoadSnapshot(persistenceId, criteria, toSequenceNr)
就是给snapshotStore发送了一个LoadSnapshot消息,LoadSnapshot又是啥呢?
/** Snapshot store plugin actor. */
private[persistence] def snapshotStore: ActorRef
居然是一个ActorRef,上面只是snapshotStore的定义,那具体在哪里实现的呢?这个,,,你猜一下?哈哈。
private[persistence] lazy val snapshotStore = {
val snapshotPluginConfig = this match {
case c: RuntimePluginConfig ⇒ c.snapshotPluginConfig
case _ ⇒ ConfigFactory.empty
}
extension.snapshotStoreFor(snapshotPluginId, snapshotPluginConfig)
}
我们可以在Eventsourced找到一个同名的定义,嗯,没错就是在这里实现并赋值的。从这段代码来看,snapshotStoreFor肯定就是根据配置创建了一个Actor,并返回了它的ActorRef。那么snapshotPlugin是如何配置的呢?下面是官方demo的一个配置。
# Absolute path to the default journal plugin configuration entry.
akka.persistence.journal.plugin = "akka.persistence.journal.inmem"
# Absolute path to the default snapshot store plugin configuration entry.
akka.persistence.snapshot-store.plugin = "akka.persistence.snapshot-store.local"
而akka.persistence.snapshot-store.local的配置如下:
akka.persistence.snapshot-store.local {
# Class name of the plugin.
class = "akka.persistence.snapshot.local.LocalSnapshotStore"
# Dispatcher for the plugin actor.
plugin-dispatcher = "akka.persistence.dispatchers.default-plugin-dispatcher"
# Dispatcher for streaming snapshot IO.
stream-dispatcher = "akka.persistence.dispatchers.default-stream-dispatcher"
# Storage location of snapshot files.
dir = "snapshots"
# Number load attempts when recovering from the latest snapshot fails
# yet older snapshot files are available. Each recovery attempt will try
# to recover using an older than previously failed-on snapshot file
# (if any are present). If all attempts fail the recovery will fail and
# the persistent actor will be stopped.
max-load-attempts = 3
}
很显然对应的class是akka.persistence.snapshot.local.LocalSnapshotStore,LocalSnapshotStore收到LoadSnapshot之后如何应答的呢?
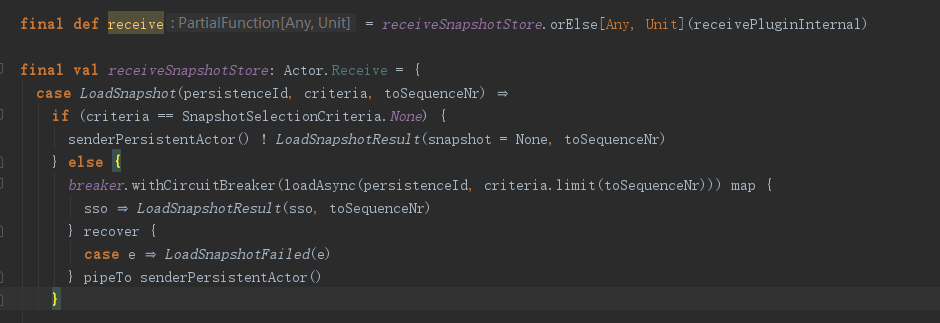
上面代码显示,LocalSnapshotStore会先调用loadAsync进行加载快照,然后返回加载结果给sender。
/**
* Response message to a [[LoadSnapshot]] message.
*
* @param snapshot loaded snapshot, if any.
*/
final case class LoadSnapshotResult(snapshot: Option[SelectedSnapshot], toSequenceNr: Long)
extends Response
具体如何加载的,这里先略过,反正是返回了LoadSnapshotResult消息。recoveryStarted是如何对这个消息响应的呢?
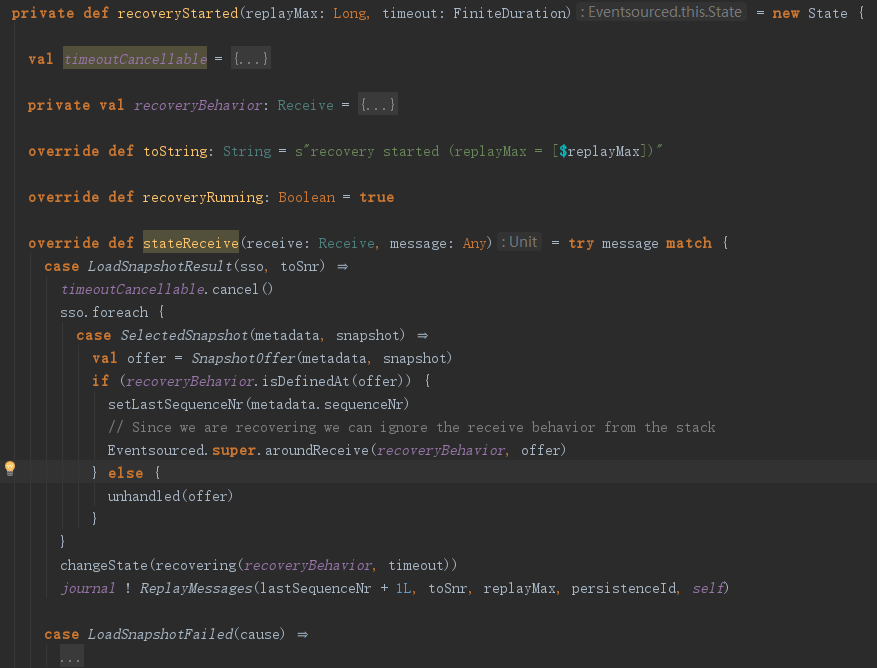
上面代码显示,如果快照加载成功会调用recoveryBehavior来处理,
private val recoveryBehavior: Receive = {
val _receiveRecover = try receiveRecover catch {
case NonFatal(e) ⇒
try onRecoveryFailure(e, Some(e))
finally context.stop(self)
returnRecoveryPermit()
Actor.emptyBehavior
}
{
case PersistentRepr(payload, _) if recoveryRunning && _receiveRecover.isDefinedAt(payload) ⇒
_receiveRecover(payload)
case s: SnapshotOffer if _receiveRecover.isDefinedAt(s) ⇒
_receiveRecover(s)
case RecoveryCompleted if _receiveRecover.isDefinedAt(RecoveryCompleted) ⇒
_receiveRecover(RecoveryCompleted)
}
}
而recoveryBehavior又把消息转发给了receiveRecover,receiveRecover是用户自定义的,状态恢复的函数。状态恢复之后又修改了当前状态为recovering,修改之后给journal发送ReplayMessages消息,请读者注意这个消息的几个参数的实际值。

其实吧,根据快照的加载过程来分析上面的代码,就简单了,我们可以先猜一下,它估计就是给journal发送状态恢复的消息,包括从哪里恢复,恢复后的消息发送给谁(当然是self了),journal会把反序列化后的消息以ReplayedMessage的形式返回给self,self去调用recoveryBehavior函数。这个函数哪里定义的呢?从源码上下文来看,居然是从上一个状态(recoveryStarted)定义然后传过来的,这实现,真尼玛醉了。
# In-memory journal plugin.
akka.persistence.journal.inmem {
# Class name of the plugin.
class = "akka.persistence.journal.inmem.InmemJournal"
# Dispatcher for the plugin actor.
plugin-dispatcher = "akka.actor.default-dispatcher"
}
与查找快照相关actor的方法一样,我们找到了默认配置,InmemJournal是不是像我们猜测的那样实现的呢?
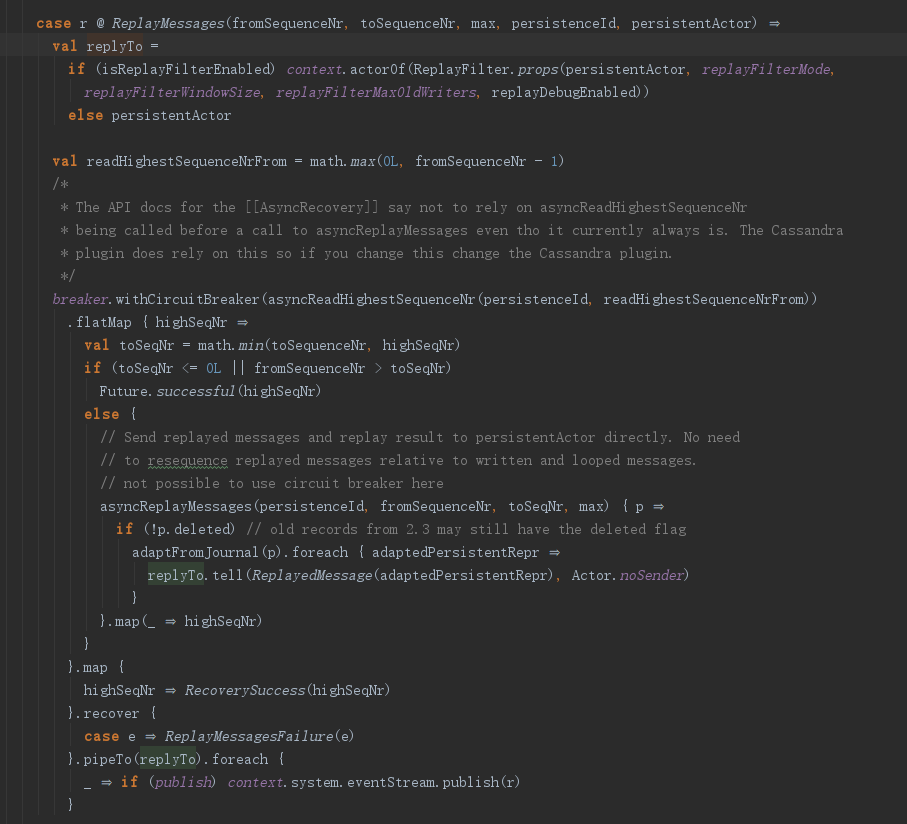
上面是InmemJournal收到ReplayMessages消息之后的逻辑,其实概括来说就是asyncReplayMessages从某个序号开始,读取并构造恢复后的数据,然后发送给replyTo。不过需要提醒读者adaptFromJournal,这个在官网也说过,是用来做消息适配的,可以对历史消息进行适配,当然了这主要是在版本升级过程中特别有用。有时候,随着系统的升级,存储的消息跟现在的消息不一定能很好的兼容,而adaptFromJournal作为一个可配置的插件机制,来动态的混入特定的类,对旧消息进行适配,转换成新版本的消息类型,再进行状态恢复。请记住这种神一样的操作,我还是非常喜欢这种设计的。
还要一点需要注意,那就是RecoverySuccess,这只有在所有的消息都发送完之后发送,也就是说,历史消息处理完之后,会发送给一个RecoverySuccess标志结束状态。ReplayedMessage这个消息忽略,反正它就是调用我们自定义的receiveRecover函数恢复状态。我们先来看如何处理RecoverySuccess,就是调用transitToProcessingState修改了当前状态,然后调用returnRecoveryPermit消息。
private def returnRecoveryPermit(): Unit =
extension.recoveryPermitter.tell(RecoveryPermitter.ReturnRecoveryPermit, self)
returnRecoveryPermit又给recoveryPermitter发送了ReturnRecoveryPermit,真是麻烦。而recoveryPermitter还记得是干啥的么?其实就是控制并发读取jounal的数量,如果太多,就先把需要状态恢复的actor推迟一段时间,因为需要恢复状态的actor可能很多,若不加限制则会导致IO飙升。这样做还是很有好处的,比如leveldb是不太适合高并发的读取的,jdbc也是不太适合大量链接的,反正限制一下并行总是有好处的嘛,毕竟这需要跟存储打交道,不能把存储搞挂了。
recoveryPermitter是如何处理ReturnRecoveryPermit消息的,这里就不贴源码分析了,反正就是释放并发度的,感兴趣的可以自行阅读。
private def transitToProcessingState(): Unit = {
if (eventBatch.nonEmpty) flushBatch()
if (pendingStashingPersistInvocations > 0) changeState(persistingEvents)
else {
changeState(processingCommands)
internalStash.unstashAll()
}
}
transitToProcessingState就显得比较重要了,它又改变了当前的行为。我们假设actor刚启动,还没有收到任何command,上面这段代码会走第二个if语句的else部分。又修改了状态,然后调用了internalStash.unstashAll()
/**
* Command processing state. If event persistence is pending after processing a
* command, event persistence is triggered and state changes to `persistingEvents`.
*/
private val processingCommands: State = new ProcessingState {
override def toString: String = "processing commands" override def stateReceive(receive: Receive, message: Any) =
if (common.isDefinedAt(message)) common(message)
else try {
Eventsourced.super.aroundReceive(receive, message)
aroundReceiveComplete(err = false)
} catch {
case NonFatal(e) ⇒ aroundReceiveComplete(err = true); throw e
} private def aroundReceiveComplete(err: Boolean): Unit = {
if (eventBatch.nonEmpty) flushBatch() if (pendingStashingPersistInvocations > 0) changeState(persistingEvents)
else unstashInternally(all = err)
} override def onWriteMessageComplete(err: Boolean): Unit = {
pendingInvocations.pop()
unstashInternally(all = err)
}
}
processingCommands很重要,这里贴出了完整的源码。
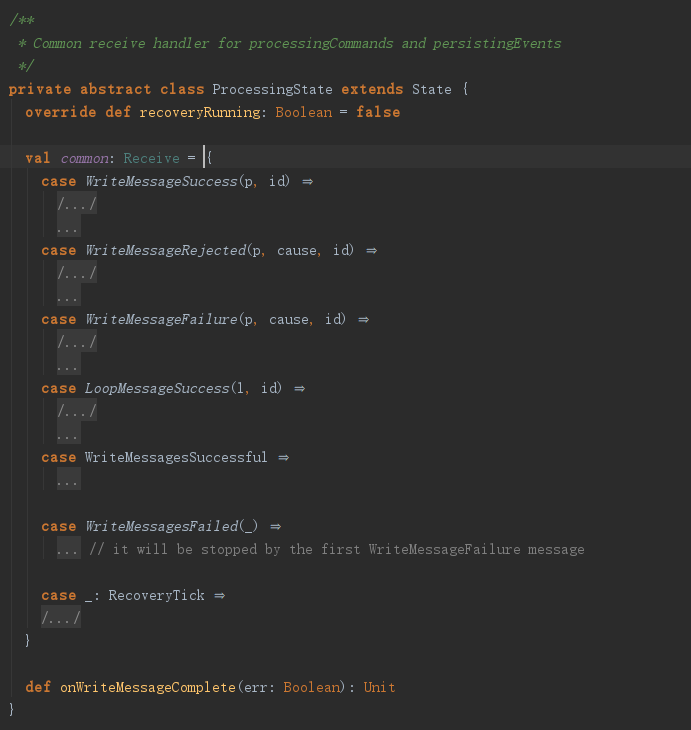
它继承了ProcessingState这个抽象类,收到消息后,先判断common这个Receive能否处理,不能处理则调用用户自定义的receive方法,其实就是receiveCommand。简单来说就是,判断是不是系统消息,如果是系统消息就拦截处理一下,不是就直接调用用户定义的方法。aroundReceiveComplete这方法非常重要,因为它是在用户自定义处理函数之后调用的,为啥在后面调用就重要?因为调用receiveCommand之后,eventBatch和pendingStashingPersistInvocations就有值了啊。
private def aroundReceiveComplete(err: Boolean): Unit = {
if (eventBatch.nonEmpty) flushBatch()
if (pendingStashingPersistInvocations > 0) changeState(persistingEvents)
else unstashInternally(all = err)
}
根据之前persist的分析,eventBatch此时已经有值了,所以会调用flushBatch
private def flushBatch() {
if (eventBatch.nonEmpty) {
journalBatch ++= eventBatch.reverse
eventBatch = Nil
}
flushJournalBatch()
}
请注意journalBatch的赋值逻辑,它居然把用户的eventBatch反转了。
private def flushJournalBatch(): Unit =
if (!writeInProgress && journalBatch.nonEmpty) {
journal ! WriteMessages(journalBatch, self, instanceId)
journalBatch = Vector.empty
writeInProgress = true
}
很显然,flushJournalBatch把用户的eventBatch的值,用WriteMessages封装一下发送给了journal,journal收到WriteMessages消息肯定是把消息序列换然后存起来了啊,根据common的定义,存成功之后肯定还会返回WriteMessagesSuccess消息的喽。参照journal状态恢复的机制来看,全都保存成功后,还应该发送WriteMessagesSuccessful消息喽,收到WriteMessagesSuccessful消息后就会把writeInProgress设置成false。
case WriteMessageSuccess(p, id) ⇒
// instanceId mismatch can happen for persistAsync and defer in case of actor restart
// while message is in flight, in that case we ignore the call to the handler
if (id == instanceId) {
updateLastSequenceNr(p)
try {
peekApplyHandler(p.payload)
onWriteMessageComplete(err = false)
} catch {
case NonFatal(e) ⇒ onWriteMessageComplete(err = true); throw e
}
}
上面是对写入成功后的处理逻辑。注意peekApplyHandler,根据它的定义以及参数来看,这个就是在调用之前的handler。
private def peekApplyHandler(payload: Any): Unit =
try pendingInvocations.peek().handler(payload)
finally flushBatch()
确实,它从pendingInvocations中peek,然后调用了handler,之后调用了onWriteMessageComplete。请注意在flushBatch之后,又调用了changeState(persistingEvents),此时的状态是persistingEvents,所以onWriteMessageComplete源码如下。
override def onWriteMessageComplete(err: Boolean): Unit = {
pendingInvocations.pop() match {
case _: StashingHandlerInvocation ⇒
// enables an early return to `processingCommands`, because if this counter hits `0`,
// we know the remaining pendingInvocations are all `persistAsync` created, which
// means we can go back to processing commands also - and these callbacks will be called as soon as possible
pendingStashingPersistInvocations -= 1
case _ ⇒ // do nothing
}
if (pendingStashingPersistInvocations == 0) {
changeState(processingCommands)
unstashInternally(all = err)
}
}
可以看到它从pendingInvocations中pop了一个元素,如果pendingInvocations为空,则重新进入processingCommands状态。
override def stateReceive(receive: Receive, message: Any) =
if (common.isDefinedAt(message)) common(message)
else stashInternally(message)
而在persistingEvents状态下,对于用户的普通消息会调用stashInternally进行缓存的,也就是说在pendingInvocations调用完之后,用户的消息是直接缓存而不处理的。当重新进入processingCommands状态时,才会把原来缓存的命令unstash,进行后续的处理。这就是同步的概念,同步其实是针对持久化actor的,而不针对存数据等一系列内部操作。这种设计我还是很喜欢的。
其实分析到这里,我们对持久化actor的persist就分析完了。概括来说就是,PersistentActor会创建两个Actor:journal、snapshotStore。分别用来持久化、恢复用户消息和当前状态快照。PersistentActor重写aroundReceive,先调用用户的自定义事件逻辑,之后把需要持久化的消息发送给journal,这期间收到的所有命令先缓存,持久化成功后,调用对应的handler,然后把缓存的消息在发出来,进行下一步处理。当然了,这期间使用changeState维护当前状态,这一点我非常不喜欢,既然是维护状态那为啥不用FSM来实现,非要自己写呢?!!
有一点我觉得设计的非常好,也非常巧妙,当然也非常自然。那就是journal和snapshotStore都是两个普通的actor,读者可能会问了,这有啥好值得提的呢?其实你仔细想想就知道为啥了,好像如果这两个组件不用actor来封装,就是单纯的读写存储,也是很正常的一件事呢。至于并发嘛,通过线程池也是可以控制的,用个actor就值得吹嘘了?值得,很值得。为啥呢?因为灵活和自构建(akka的很多高级特性都是基于最基本的actor实现的),而且试想在remote和cluster模式下,这有啥好处呢?如果这就是简单的actor,你是不是可以把journal、snapshotStore放到远程呢?而这个远程节点是不是可以使用一个SSD硬盘的节点呢?这两个actor既然有并发的限制,那它能不能是一个router呢?能不能有一组journal、snapshotStore来处理某些actor(persistId的hash值相同)的持久化呢?我实在不敢想下去了,有了actor简直就是完美啊,简直就是牛逼出了天际啊。^_^
最后啰嗦一点,刚才你一定注意到journalBatch是逆序的了。下面是PersistentActor内部的stash的逻辑,加上官方的注释你一定就知道为啥了,我就不再具体分析啦。
/**
* Enqueues `envelope` at the first position in the mailbox. If the message contained in
* the envelope is a `Terminated` message, it will be ensured that it can be re-received
* by the actor.
*/
private def enqueueFirst(envelope: Envelope): Unit = {
mailbox.enqueueFirst(self, envelope)
envelope.message match {
case Terminated(ref) ⇒ actorCell.terminatedQueuedFor(ref)
case _ ⇒
}
}
Akka源码分析-Persistence的更多相关文章
- Akka源码分析-Persistence Query
Akka Persistence Query是对akka持久化的一个补充,它提供了统一的.异步的流查询接口.今天我们就来研究下这个Persistence Query. 前面我们已经分析过Akka Pe ...
- Akka源码分析-Akka Typed
对不起,akka typed 我是不准备进行源码分析的,首先这个库的API还没有release,所以会may change,也就意味着其概念和设计包括API都会修改,基本就没有再深入分析源码的意义了. ...
- Akka源码分析-Akka-Streams-概念入门
今天我们来讲解akka-streams,这应该算akka框架下实现的一个很高级的工具.之前在学习akka streams的时候,我是觉得云里雾里的,感觉非常复杂,而且又难学,不过随着对akka源码的深 ...
- Akka源码分析-Cluster-Metrics
一个应用软件维护的后期一定是要做监控,akka也不例外,它提供了集群模式下的度量扩展插件. 其实如果读者读过前面的系列文章的话,应该是能够自己写一个这样的监控工具的.简单来说就是创建一个actor,它 ...
- Akka源码分析-Cluster-Distributed Publish Subscribe in Cluster
在ClusterClient源码分析中,我们知道,他是依托于“Distributed Publish Subscribe in Cluster”来实现消息的转发的,那本文就来分析一下Pub/Sub是如 ...
- Akka源码分析-Cluster-Singleton
akka Cluster基本实现原理已经分析过,其实它就是在remote基础上添加了gossip协议,同步各个节点信息,使集群内各节点能够识别.在Cluster中可能会有一个特殊的节点,叫做单例节点. ...
- Akka源码分析-local-DeathWatch
生命周期监控,也就是死亡监控,是akka编程中常用的机制.比如我们有了某个actor的ActorRef之后,希望在该actor死亡之后收到响应的消息,此时我们就可以使用watch函数达到这一目的. c ...
- Akka源码分析-Cluster-ActorSystem
前面几篇博客,我们依次介绍了local和remote的一些内容,其实再分析cluster就会简单很多,后面关于cluster的源码分析,能够省略的地方,就不再贴源码而是一句话带过了,如果有不理解的地方 ...
- Akka源码分析-Persistence-AtLeastOnceDelivery
使用过akka的应该都知道,默认情况下,消息是按照最多一次发送的,也就是tell函数会尽量把消息发送出去,如果发送失败,不会重发.但有些业务场景,消息的发送需要满足最少一次,也就是至少要成功发送一次. ...
随机推荐
- python3返回值中的none
浏览器返回null,python3返回none,懵了. google了很多资料,不明就里,这就是没基础的后果啊呀呀呀. 上阮一峰的截图,就这么理解下凑合吧:
- js之条件判断
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- String与StringBuffer,StringBuilder
在java中有3个类来负责字符的操作. 1.Character 是进行单个字符操作的, 2.String 对一串字符进行操作.不可变类. 3.StringBuffer 也是对一串字符进行操作,但是可变 ...
- C#中的定制特性(Attributes)
C#中的定制特性(Attributes) 介绍 Attributes是一种新的描述信息,我们既可以使用attributes来定义设计期信息(例如:帮助文件.文档的URL),还可能用attributes ...
- 程序员节QWQ
据$lc$说,今天是程序员节QWQ 过节啦QWQ
- poj 1562 简单深搜
//搜八个方向即可 #include<stdio.h> #include<string.h> #define N 200 char ma[N][N]; int n,m,vis[ ...
- zoj——3557 How Many Sets II
How Many Sets II Time Limit: 2 Seconds Memory Limit: 65536 KB Given a set S = {1, 2, ..., n}, n ...
- Bestcoder #92
A =w= B 计数题,枚举A.C,算B.D的个数,注意减去重复的 我当时是f[1][n]->f[2][n]->f[3][n]->f[4][n]递推的 C 题意:长为n的字符串仅由' ...
- JAVA和C语言的区别
java语言和c语言的区别: 1 un 公司推出的Java 是面向对象程序设计语言,其适用于Internet 应用的开发,称为 ...
- Spring Boot配置文件规则以及使用方法官方文档查找以及Spring项目的官方文档查找方法
比如要使用Spring Boot实现一个功能,最直接的方式是Google,但是往往搜索出来的都比较乱,关键是乱在不同的版本上,比如1.x版本和2.x版本的配置是不一样的.最明显区别是在使用Thymel ...