记一次有关spark动态资源分配和消息总线的爬坑经历
问题:
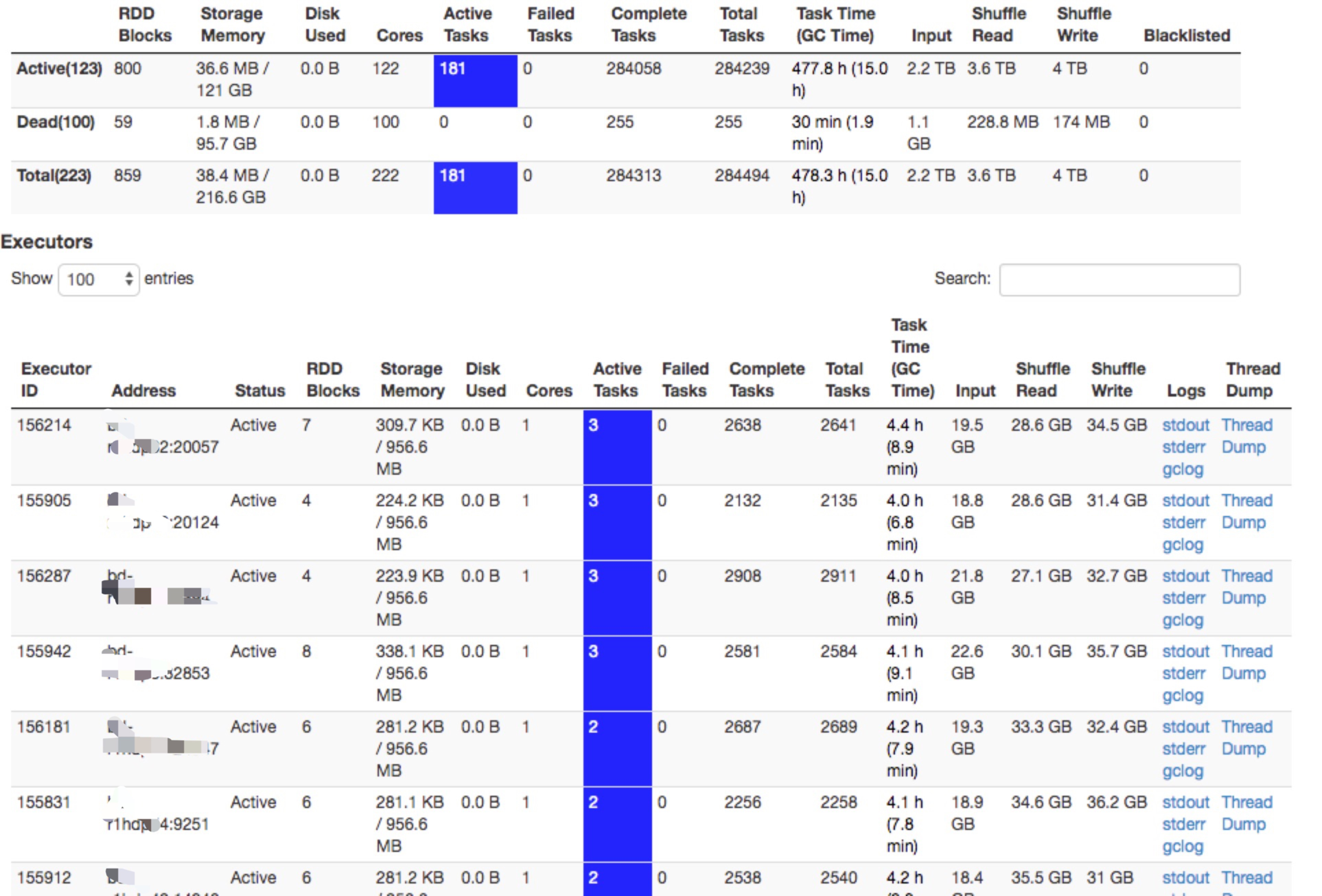
线上的spark thriftserver运行一段时间以后,ui的executor页面上显示大量的active task,但是从job页面看,并没有任务在跑。此外,由于在yarn mode下,默认情况是一个executor只能有一个active task,但是executor页面的active task却可以有多个。而且在没有任务在跑的情况下,动态资源你分配不能生效,spark thriftserver在空闲的情况下资源得不到释放。
问题排查:
1,看到某个executor有大量的active task,首先想到是不是真的是task没有结束。所以首先去对应的executor机器上,查看对应进程的cpu,发现利用率很低。与此同时,打印进程线程栈和正常的executor的线程栈进行对比,发现连行数都是一样的。初步排除了是由于task没有结束,导致task一直在忙的情况。
2,虽然是偶现,但是发现即使某个executor的active task已经很高了(比方说10,大于1),当有新的任务过来时,这个executor仍然可以调度在这个executor上。由此可以确定,在driver内部的dagscheuler和task scheduler中对资源使用情况的相关统计数据是对的。
3,通过1,2的分析,接下来的猜测就是UI显示的数据不对了。2.3以后对ui的模块进行了重新改造,难道是新引入的bug?从官方的jira上搜了一圈,没有发现类似的问题。
4,除了UI上显示的active task不对,spark的动态资源分配也确实没有生效(在没有任务时,executor资源没有释放),说明动态资源分配时获取的系统资源统计也是有误的。于是找了一圈有关动态资源分配的一些jira,还真发现了一些jira(https://issues.apache.org/jira/browse/SPARK-11334)打上补丁,但是UI页面显示的active task肯定和这个issue是没有关系的。
5,到此时,陷入了无解。后来突然想到,无论是UI页面的统计还是动态资源分配,都走的是消息总线机制,之前看源码的时候印象中,消息总线中的消息不是100%不丢的(spark Listener和Metrics机制),所以去日志中搜了一下相关消息,果然发现有消息丢失。

然后翻了一下源码,spark消息这个队列的大小是10000,超过这个值的时候,如果还没有消费掉,就会丢弃消息,然后果断调大到10w,目前已过去三四天了,线上还没有出现这个问题,应该就是这个原因了。
6,进一步思考,为啥会有这个的消息事件呢?spark官方并没有类似的jira,然后想到我们自己跑的spark自行添加了一些event到消息总线,可能是自行添加的event导致的,所以以后自行添加event事件的时候要注意一下这个队列大小的限制。另外,在100%需要对数据进行统计的准备的情况下,使用spark内部的消息总线机制来做异步处理并不是非常的恰当。
记一次有关spark动态资源分配和消息总线的爬坑经历的更多相关文章
- Spark动态资源分配-Dynamic Resource Allocation
微信搜索lxw1234bigdata | 邀请体验:数阅–数据管理.OLAP分析与可视化平台 | 赞助作者:赞助作者 Spark动态资源分配-Dynamic Resource Allocation S ...
- spark动态资源(executor)分配
spark动态资源调整其实也就是说的executor数目支持动态增减,动态增减是根据spark应用的实际负载情况来决定. 开启动态资源调整需要(on yarn情况下) 1.将spark.dynamic ...
- VueRouter爬坑第二篇-动态路由
VueRouter系列的文章示例编写时,项目是使用vue-cli脚手架搭建. 项目搭建的步骤和项目目录专门写了一篇文章:点击这里进行传送 后续VueRouter系列的文章的示例编写均基于该项目环境. ...
- spark on yarn 动态资源分配报错的解决:org.apache.hadoop.yarn.exceptions.InvalidAuxServiceException: The auxService:spark_shuffle does not exist
组件:cdh5.14.0 spark是自己编译的spark2.1.0-cdh5.14.0 第一步:确认spark-defaults.conf中添加了如下配置: spark.shuffle.servic ...
- 利用动态资源分配优化Spark应用资源利用率
背景 在某地市开展项目的时候,发现数据采集,数据探索,预处理,数据统计,训练预测都需要很多资源,现场资源不够用. 目前该项目的资源3台旧的服务器,每台的资源 内存为128G,cores 为24 (co ...
- Spark如何进行动态资源分配
一.操作场景 对于Spark应用来说,资源是影响Spark应用执行效率的一个重要因素.当一个长期运行的服务,若分配给它多个Executor,可是却没有任何任务分配给它,而此时有其他的应用却资源紧张,这 ...
- spark提交至yarn的的动态资源分配
1.为什么开启动态资源分配 ⽤户提交Spark应⽤到Yarn上时,可以通过spark-submit的num-executors参数显示地指定executor 个数,随后,ApplicationMast ...
- 「Spark从精通到重新入门(二)」Spark中不可不知的动态资源分配
前言 资源是影响 Spark 应用执行效率的一个重要因素.Spark 应用中真正执行 task 的组件是 Executor,可以通过spark.executor.instances 指定 Spark ...
- Spark动态加载外部资源文件
Spark动态加载外部资源文件 1.spark-submit --files 动态加载外部资源文件 之前做一个关于Spark的项目时,因项目中需要读取某个静态资源文件,然后在本地IDEA测试一切皆正常 ...
随机推荐
- django rest_framework swagger使用案例
环境准备 环境要求: python3 django2 pip3 模块安装: pip3 install django-rest-framework pip3 install django-rest-sw ...
- Oracle:imp导入imp-00000问题
现场环境:window2008 . oracle11.2g .客户端安装的是oracle10g一个简洁版 34M的. 在imp导入时,提示 Message 100 not found; No mes ...
- 蒟蒻的HNOI2017滚粗记
蒟蒻的第一次省选,然而并没有RP爆发... Day 1: 8:00开考,(然而密码错误是什么鬼).跌跌撞撞,8:40终于拿到纸质试题. { T1:作为一名没有学过Splay的蒟蒻,考场上真的被出题人感 ...
- 一题多解 —— linux 日志文件(log)reload 重新载入
1. tail -F 等同于–follow=name –retry,根据文件名进行追踪,并保持重试,即该文件被删除或改名后,如果再次创建相同的文件名,会继续追踪 也即可以间接实现从日志文件末尾,不断载 ...
- python之路,day7-面向对象变成
本篇内容: 面向对象.类方法.属性方法 类的特殊方法 反射 异常处理 Socket开发基础 一.面向对象高级语法部分 静态方法: #@staticmethod只是名义上归类管理,实际上跟类没什么关系 ...
- JS两个数组比较,删除重复值巧妙方法
//方法一 var arr1 = [1,2,3,4,5,6,7,8]; //数组A var arr2 = [1,2,3,11,12,13,14];//数组B var temp = []; //临时数组 ...
- C. Vanya and Scales
time limit per test 1 second memory limit per test 256 megabytes input standard input output standar ...
- sourceTree 的使用
一.拉取其他分支代码 1.git clone 代码是下载master分支 2.在未做修改的情况下,合并分支 二.提交代码到其他分支 1.创建分支(名称可以与远程不同) 2.(正常提交步骤)将作出的修改 ...
- hdoj5813【构造】
2016 Multi-University Training Contest 7 05 真的真的好菜哇... 思路: 暴力. 我对那些到达目的地少的点做硬性规定就是去比他要到达目的地更少的点,这样一来 ...
- poj2229【完全背包-规律Orz...】
挑战DP 题意: 被组合数只能是2的整数幂,然后给出一个数问有多少种组合(mod1e10): 思路: 完全背包做啊-还是蛮简单的-(这里取膜要改成加法,省时间-) dp[i]代表对于j的方案数 贴一发 ...