软件架构自学笔记----分享“去哪儿 Hadoop 集群 Federation 数据拷贝优化”
去哪儿 Hadoop 集群 Federation 数据拷贝优化
背景
去哪儿 Hadoop 集群随着去哪儿网的发展一直在优化改进,基本保证了业务数据存储量和计算量爆发式增长下的存储服务质量。然而,随着集群规模的发展,单组 NameNode 组成的集群也到达了新的瓶颈:因为 NameNode 内存使用和元数据量正相关,在 180GB 堆内存配置下,元数据量红线约为 7 亿,而随着集群规模和业务的发展,即使经过小文件合并与数据压缩,仍然无法阻止元数据量逐渐接近红线。而且在性能方面,随着业务的发展,集群规模的扩大,NameNode RPC 响应时间增大,QPS 逐渐降低。
HDFS Federation 是 Hadoop-0.23.0 中为解决 HDFS 单点限制而提出的 NameNode 水平扩展方案。该方案可以为 HDFS 服务创建多个 NameSpace ,从而提高集群的扩展性和隔离性,分散单个 NameNode 的负载。(在 HDFS 中 NameSpace 是指 NameNode 中负责管理文件系统中的树状目录结构以及文件与数据块的映射关系的一层逻辑结构,在 Federation 方案中,NameNode 之间相互隔离,因此社区也用一个 NameSpace 来指代 Federation 中一组独立的 NameNode 及其元数据。)
在 Federation 过程中,非常重要的一个环节就是数据的拷贝。
原来所有的数据都是从源主节点 NameNode1 下访问,例如 /user/flight,/user/hotel 等。 如果 Federation 后,/user/flight 从 NameNode1 访问,/user/hotel 从 NameNode2 访问,这样就需要将 /user/hotel 目录下所有的数据和元数据拷贝到 NameNode2 的集群中。
fastcopy 简介
如果集群数据比较少,可以直接 distcp 完成。
现在去哪儿网的数据,单个 DataNode 的使用占比中位数已经超过 80%,即,要拷贝出 70% 的数据的话,不考虑时间,磁盘空间也满足不了要求。 如果拆成多次操作,周期和运维成本会高出很多。
所以选择了社区中的 fastcopy 方案, https://issues.apache.org/jira/browse/HDFS-2139 ,FastCopy 是 Facebook 开源的数据拷贝方案。主要逻辑就是,从源 NameNode 读文件信息和 block 对应关系,然后在目标 NameNode 上创建文件,添加 block ,拷贝 block 。 其中拷贝 block 的方式(最终数据块的拷贝)是使用 linux 的硬链拷贝来完成,这样就不会增加存储成本了。
fastcopy 的优点,速度快,不占存储空间。也有缺点,是没有进行文件权限和属主的拷贝,还需要再次修改,这个权属从源 NameNode 也需要读所有的文件,然后写到目标 NameNode 去,这个时间基本是拷贝时间的 1/3 到 1/2 。
fastcopy 与 distcp 测试对比
为了更直观的了解 fastcopy 的性能,我们先测试了 fastcopy 和 distcp 的比较。
测试集群环境: 2 个 NameSpace,50 个 DataNode。
测试结果
元数据量从 100 万到 1 亿,fastcopy 花费时间从 0.68 分钟到 90 分钟,distcp 从 5m 到 830m。
元数据总量与拷贝时间折线图:
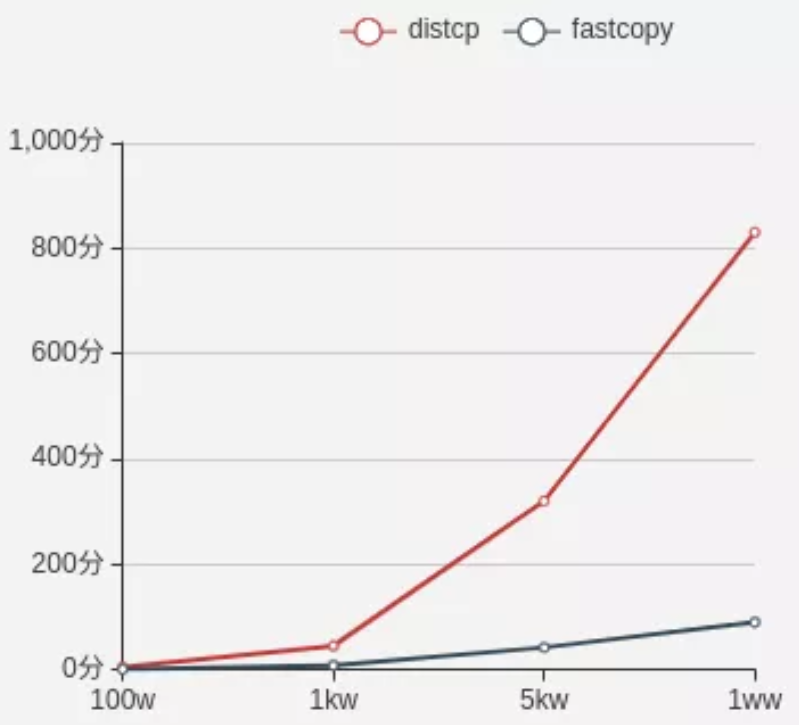
测试分析结论
根据测试结果,生产集群拷贝 5 亿元数据:
distcp 需要花费为 4 天。如果开用 distcp ,公司集群停用 4 天,业务报表统计、业务模型训练等都不可用,这是不可接受的,此方案不通。
fastcopy 需要花费 90*5/60*1.8=13.5 个小时,1.8 为一个系数,表示元数据增大到 7 亿后响应时间增大的程度。fastcopy 拷贝后,还需要对原文件的权限属主进行设置,也需要 6 个小时左右,最终 fastcopy 需要 20 个小时左右,对公司的报表等影响很大。
测试过程中,我们发现 fastcopy 的瓶颈是 active 主节点的并发度。在阅读 fastcopy 源码的过程中,我们发现 fastcopy 对同一个元数据有多次请求。我们准备从这点开始对源码优化。
fastcopy 优化
fastcopy 适用范围较宽,在 Federation 集群中任何一个时间节点都可以使用。
而我们现在面临的是单 NameNode 拆分多个 NameNode 时大量数据迁移时间过长问题。拆分时刻可以停止集群写服务,提前创建 Snapshot ,保证 fsimage 不变,在此前提下我们进行优化。
优化后的 fastcopy 简称 qfastcopy 。
原 fastcopy 流程以及步骤
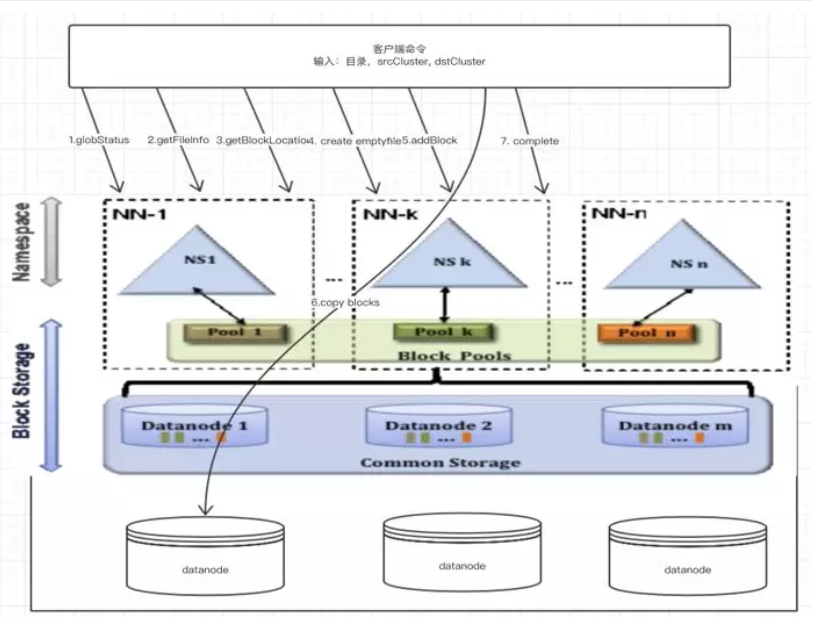

原 fastcopy 步骤所需资源与性能分析

优化方案

qfastcopy
qfastcopy 流程:
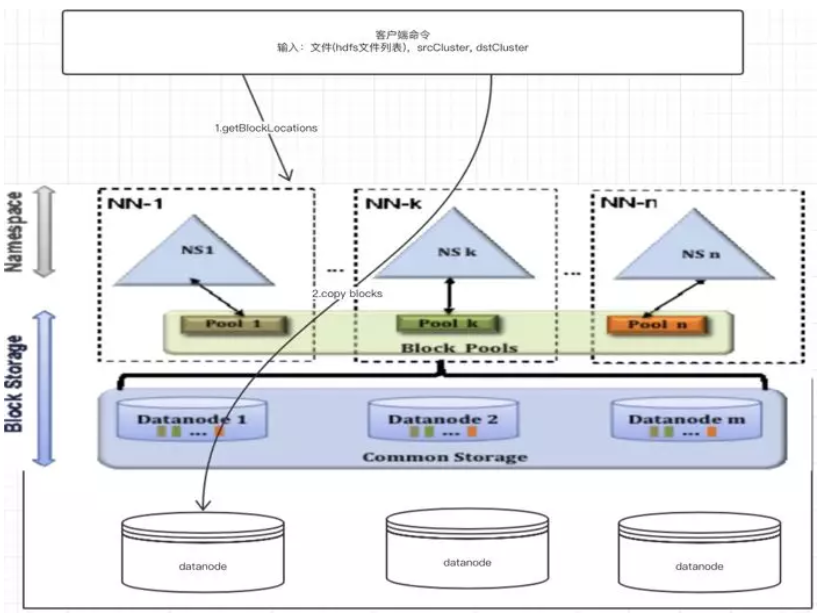
qfastcopy 具体步骤:

qfastcopy 的缺点
使用场景单一,只能在 Federation 过程中 NameNode 拆分时使用,需要提前 copy fsimage 到目标集群。
目标文件与源文件绝对路径相同。
整个流程中集群不能对外提供写操作。
qfastcopy 测试
fastcopy 和 qfastcopy 对比
元数据量与拷贝时间折线图:
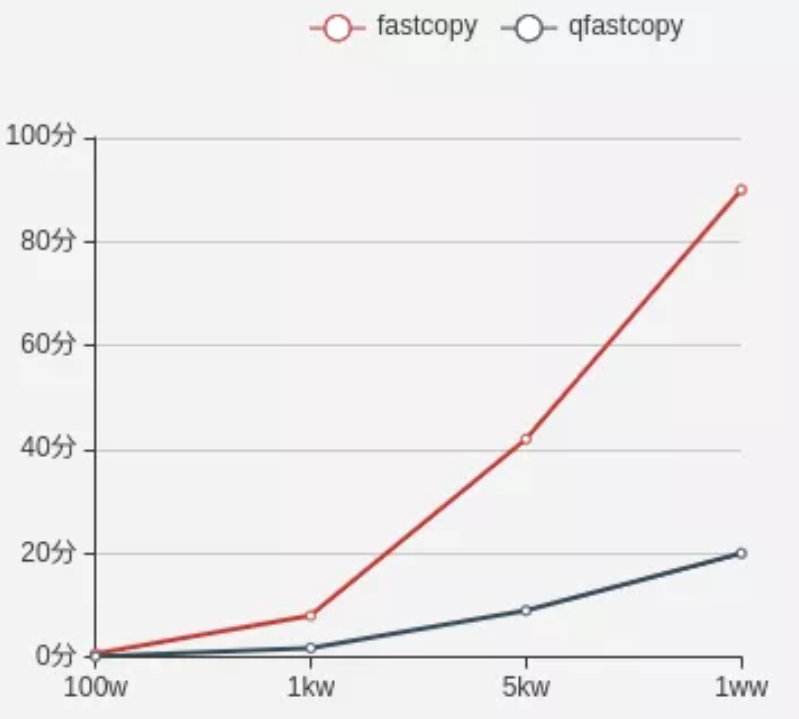
分析与结论
根据测试结果,生产集群拷贝 5 亿元数据,qfastcopy 需要花费 22*5/60*1.8=3.5 小时。
最终,我们将近集群 Federation 的 5 亿元数据拷贝时间从 20 小时优化到了 3.5 小时。
软件架构自学笔记----分享“去哪儿 Hadoop 集群 Federation 数据拷贝优化”的更多相关文章
- 本地日志数据实时接入到hadoop集群的数据接入方案
1. 概述 本手册主要介绍了,一个将传统数据接入到Hadoop集群的数据接入方案和实施方法.供数据接入和集群运维人员参考. 1.1. 整体方案 Flume作为日志收集工具,监控一个文件目录或者一个文 ...
- DistCp 集群之间数据拷贝工具
DistCp(分布式拷贝)是用于大规模集群内部和集群之间拷贝的工具.可以将数据拷贝到另个一集群,也可以将另一个集群的数据拷贝到本集群.
- [hadoop读书笔记] 第九章 构建Hadoop集群
P322 运行datanode和tasktracker的典型机器配置(2010年) 处理器:两个四核2-2.5GHz CPU 内存:16-46GN ECC RAM 磁盘存储器:4*1TB SATA 磁 ...
- (转)hadoop 集群间数据迁移
hadoop集群之间有时候需要将数据进行迁移,如将一些保存的过期文档放置在一个小集群中进行保存. 使用的是社区提供的功能,distcp.用法非常简单: hadoop distcp hdfs://nn1 ...
- Hadoop学习笔记(4)hadoop集群模式安装
具体的过程参见伪分布模式的安装,集群模式的安装和伪分布模式的安装基本一样,只有细微的差别,写在下面: 修改masers和slavers文件: 在hadoop/conf文件夹中的配置文件中有两个文件ma ...
- hadoop 集群中数据块的副本存放策略
HDFS采用一种称为机架感知(rack-aware)的策略来改进数据的可靠性.可用性和网络带宽的利用率.目前实现的副本存放策略只是在这个方向上的第一步.实现这个策略的短期目标是验证它在生产环境下的有效 ...
- [hadoop读书笔记] 第十章 管理Hadoop集群
P375 Hadoop管理工具 dfsadmin - 查询HDFS状态信息,管理HDFS. bin/hadoop dfsadmin -help 查询HDFS基本信息 fsck - 检查HDFS中文件的 ...
- hadoop系列一:hadoop集群安装
转载请在页首明显处注明作者与出处 http://www.cnblogs.com/zhuxiaojie/p/6384393.html 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据 ...
- hadoop集群故障排除
故障一:某个datanode节点无法启动 我是以用户名centos安装和搭建了一个测试用的hadoop集群环境,也配置好了有关的权限,所有者.所属组都配成centos:centos [故障现象] 名称 ...
随机推荐
- Scala解析Json格式
Scala解析Json格式 代码块 Scala原生包 导入包 import scala.util.parsing.json._ def main(args: Array[String]): Unit ...
- 微信小程序初探(二):阅读官方demo源码
阅读demo有助于理解逻辑,而且demo源码中应该包含了框架开发人员想要表达的意思的精华,先从app.js着手来阅读. 附带贴下说明: https://mp.weixin.qq.com/debug/w ...
- Django Rest FrameWork再练习
可能有重构目前应用的需求,rest framework是值得有必要深入去了解的. 所以,这应该是第三次看官方文档来练习, 希望能获取更深入的记忆. __author__ = 'CHENGANG882' ...
- 复习es6-解构赋值+字符串的扩展
1. 数组的解构赋值 从数组中获得变量的值,给对应的声明变量赋值,,有次序和对应位置赋值 解构赋值的时候右边必须可以遍历 解构赋值可以使用默认值 惰性求值,当赋值时候为undefined时候,默认是个 ...
- 1.3-动态路由协议RIP①
Dynamic Routing Protocol:动态路由协议 现代IP网络中,主要的动态路由协议: AD/管理距离: 1:DV/距离向量协议:RIP(120)/IGRP(100) 2:LS/链路状态 ...
- [miniApp] WeChat user login code
in client/app.js, we put user login logic inside here, so that other module can reuse those code by ...
- 我所未知的 typeof 现象
一.一些基本使用测试 从上述可以看出: 1.判断一个 变量 是不是对象类型,不能只用 typeof 运算符: 2.它的返回值一直是一个字符串: 3.尽管 typeof null === 'object ...
- 并行运维工具pssh的安装及实战应用
并行运维工具pssh的安装及实战应用 - CSDN博客 https://blog.csdn.net/field_yang/article/details/68066468
- Linux ALSA声卡驱动之八:ASoC架构中的Platform
1. Platform驱动在ASoC中的作用 前面几章内容已经说过,ASoC被分为Machine,Platform和Codec三大部件,Platform驱动的主要作用是完成音频数据的管理,最终通过C ...
- 【总结】设备树语法及常用API函数【转】
本文转载自:http://blog.csdn.net/fengyuwuzu0519/article/details/74352188 一.DTS编写语法 二.常用函数 设备树函数思路是:uboot ...