百度地图API获取数据
目前,大厂的服务范围越来越广,提供的数据信息也是比较全的,在生活服务,办公领域,人工智能等方面都全面覆盖,相对来说,他们的用户基数大,通过用户获取的信息也是巨大的。除了百度提供api,国内提供免费API获取数据的还有很多,包括新浪、豆瓣电影、饿了么、阿里、腾讯等今天使用百度地图API来请求我们想要的数据。
第一步.注册百度开发者账号
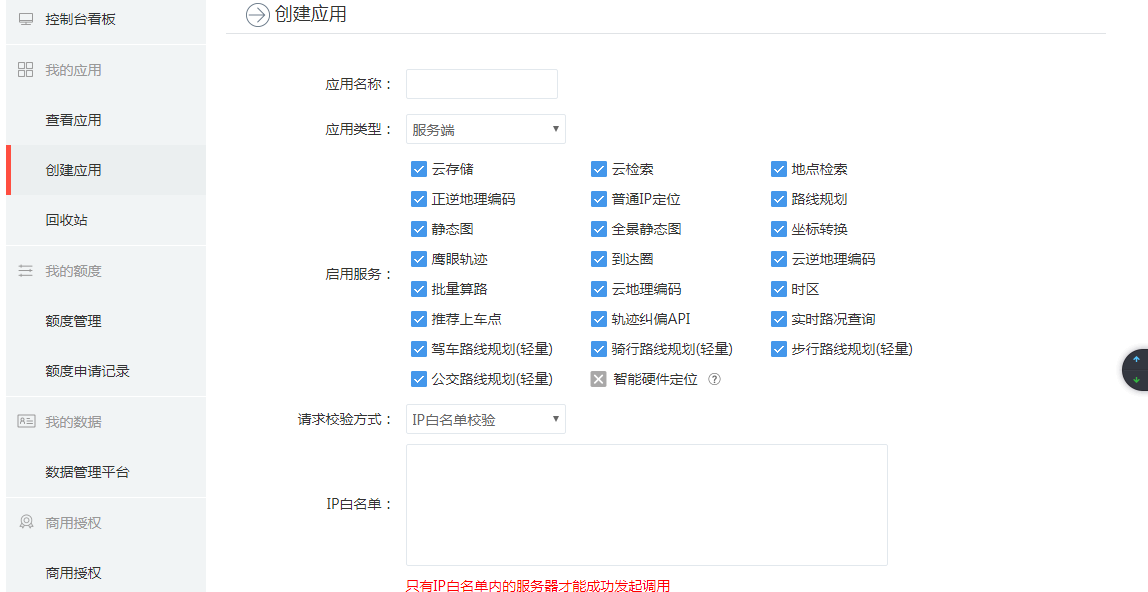
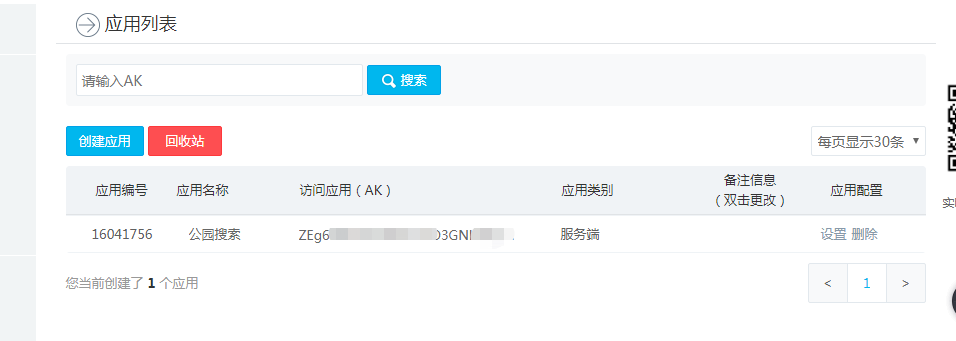
注册成功后就可以获取到应用服务AK也就是API秘钥,这个是最重要的,应用名称可以随便取,如果是普通用户一天只有2000调用限额,认证用户一天有10万次调用限额
在百度地图web服务API文档中我可以看见提供的接口和相关参数,其中就有我们要获取的AK参数,使用的GET请求

一.下面我们尝试使用API获取获取北京市的城市公园数据,需要配置参数
import requests
import json def getjson(loc):
headers = {'User-Agent' : 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
pa = {
'q': '公园',
'region': loc,
'scope': '',
'page_size': 20,
'page_num': 0,
'output': 'json',
'ak': '填写自己的AK'
}
r = requests.get("http://api.map.baidu.com/place/v2/search", params=pa, headers= headers)
decodejson = json.loads(r.text)
return decodejson getjson('北京市')

二.获取所有拥有公园的城市
import requests
import json
def getjson(loc):
headers = {'User-Agent' : 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
pa = {
'q': '公园',
'region': loc,
'scope': '',
'page_size': 20,
'page_num': 0,
'output': 'json',
'ak': '填写自己的AK'
}
r = requests.get("http://api.map.baidu.com/place/v2/search", params=pa, headers= headers)
decodejson = json.loads(r.text)
return decodejson province_list = ['江苏省', '浙江省', '广东省', '福建省', '山东省', '河南省', '河北省', '四川省', '辽宁省', '云南省',
'湖南省', '湖北省', '江西省', '安徽省', '山西省', '广西壮族自治区', '陕西省', '黑龙江省', '内蒙古自治区',
'贵州省', '吉林省', '甘肃省', '新疆维吾尔自治区', '海南省', '宁夏回族自治区', '青海省', '西藏自治区']
for eachprovince in province_list:
decodejson = getjson(eachprovince)
#print(decodejson["results"])
for eachcity in decodejson.get('results'):
print(eachcity)
city = eachcity['name']
#print(city)
num = eachcity['num']
output = '\t'.join([city, str(num)]) + '\r\n'
with open('cities.txt', "a+", encoding='utf-8') as f:
f.write(output)
f.close()
import requests
import json
def getjson(loc):
headers = {'User-Agent' : 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
pa = {
'q': '公园',
'region': loc,
'scope': '',
'page_size': 20,
'page_num': 0,
'output': 'json',
'ak': '填写自己的AK'
}
r = requests.get("http://api.map.baidu.com/place/v2/search", params=pa, headers= headers)
decodejson = json.loads(r.text)
return decodejson decodejson = getjson('全国')
six_cities_list = ['北京市','上海市','重庆市','天津市','香港特别行政区','澳门特别行政区',]
for eachprovince in decodejson['results']:
city = eachprovince['name']
num = eachprovince['num']
if city in six_cities_list:
output = '\t'.join([city, str(num)]) + '\r\n'
with open('cities789.txt', "a+", encoding='utf-8') as f:
f.write(output)
f.close()
保存到文件
三.获取所有城市的公园数据,在从各个城市获取数据之前,先在MySQL建立baidumap数据库,用来存放所有的数据
#coding=utf-8
import pymysql conn= pymysql.connect(host='localhost' , user='root', passwd='*******', db ='baidumap', charset="utf8")
cur = conn.cursor()
sql = """CREATE TABLE city (
id INT NOT NULL AUTO_INCREMENT,
city VARCHAR(200) NOT NULL,
park VARCHAR(200) NOT NULL,
location_lat FLOAT,
location_lng FLOAT,
address VARCHAR(200),
street_id VARCHAR(200),
uid VARCHAR(200),
created_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (id)
);"""
cur.execute(sql)
cur.close()
conn.commit()
conn.close()
city_list = list()
with open("cities.txt", 'r', encoding='utf-8') as txt_file:
for eachLine in txt_file:
if eachLine != "" and eachLine != "\n":
fields = eachLine.split("\t")
city = fields[0]
city_list.append(city)
txt_file.close() #接下来爬取每个城市的数据,并将其加入city数据表中
import requests
import json
import pymysql conn= pymysql.connect(host='localhost' , user='root', passwd='********', db ='baidumap', charset="utf8")
cur = conn.cursor() def getjson(loc,page_num):
headers = {'User-Agent' : 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
pa = {
'q': '公园',
'region': loc,
'scope': '',
'page_size': 20,
'page_num': page_num,
'output': 'json',
'ak': '填写自己的AK'
}
r = requests.get("http://api.map.baidu.com/place/v2/search", params=pa, headers= headers)
decodejson = json.loads(r.text)
return decodejson for eachcity in city_list:
not_last_page = True
page_num = 0
while not_last_page:
decodejson = getjson(eachcity, page_num)
#print (eachcity, page_num)
if decodejson['results']:
for eachone in decodejson['results']:
try:
park = eachone['name']
except:
park = None
try:
location_lat = eachone['location']['lat']
except:
location_lat = None
try:
location_lng = eachone['location']['lng']
except:
location_lng = None
try:
address = eachone['address']
except:
address = None
try:
street_id = eachone['street_id']
except:
street_id = None
try:
uid = eachone['uid']
except:
uid = None
sql = """INSERT INTO baidumap.city
(city, park, location_lat, location_lng, address, street_id, uid)
VALUES
(%s, %s, %s, %s, %s, %s, %s);""" cur.execute(sql, (eachcity, park, location_lat, location_lng, address, street_id, uid,))
conn.commit()
page_num += 1
else:
not_last_page = False
cur.close()
conn.close()
四.获取所有公园的详细信息
baidumap数据库已经有了city这个表格,存储了所有城市的公园数据,但是这个数据比较粗糙,接下来我们使用百度地图检索服务获取没一个公园的详情
#coding=utf-8
import pymysql conn= pymysql.connect(host='localhost' , user='root', passwd='*******', db ='baidumap', charset="utf8")
cur = conn.cursor()
sql = """CREATE TABLE park (
id INT NOT NULL AUTO_INCREMENT,
park VARCHAR(200) NOT NULL,
location_lat FLOAT,
location_lng FLOAT,
address VARCHAR(200),
street_id VARCHAR(200),
telephone VARCHAR(200),
detail INT,
uid VARCHAR(200),
tag VARCHAR(200),
type VARCHAR(200),
detail_url VARCHAR(800),
price INT,
overall_rating FLOAT,
image_num INT,
comment_num INT,
shop_hours VARCHAR(800),
alias VARCHAR(800),
keyword VARCHAR(800),
scope_type VARCHAR(200),
scope_grade VARCHAR(200),
description VARCHAR(9000),
created_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (id)
);"""
cur.execute(sql)
cur.close()
conn.commit()
conn.close()
import requests
import json
import pymysql conn= pymysql.connect(host='localhost' , user='root', passwd='********', db ='baidumap', charset="utf8")
cur = conn.cursor()
sql = "Select uid from baidumap.city where id > 0;" cur.execute(sql)
conn.commit()
results = cur.fetchall()
cur.close()
conn.close()
import requests
import json
import pymysql conn= pymysql.connect(host='localhost' , user='root', passwd='********', db ='baidumap', charset="utf8")
cur = conn.cursor()
sql = "Select uid from baidumap.city where id > 0;" cur.execute(sql)
conn.commit()
results = cur.fetchall()
#print(results) def getjson(uid):
headers = {'User-Agent' : 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
pa = {
'uid': uid,
'scope': '',
'output': 'json',
'ak': '填写自己的AK'
}
r = requests.get("http://api.map.baidu.com/place/v2/search", params=pa, headers= headers)
decodejson = json.loads(r.text)
return decodejson for row in results:
print(row)
uid = row[0]
decodejson = getjson(uid)
#print (uid)
info = decodejson['result']
try:
park = info['name']
except:
park = None
try:
location_lat = info['location']['lat']
except:
location_lat = None
try:
location_lng = info['location']['lng']
except:
location_lng = None
try:
address = info['address']
except:
address = None
try:
street_id = info['street_id']
except:
street_id = None
try:
telephone = info['telephone']
except:
telephone = None
try:
detail = info['detail']
except:
detail = None
try:
tag = info['detail_info']['tag']
except:
tag = None
try:
detail_url = info['detail_info']['detail_url']
except:
detail_url = None
try:
type = info['detail_info']['type']
except:
type = None
try:
overall_rating = info['detail_info']['overall_rating']
except:
overall_rating = None
try:
image_num = info['detail_info']['image_num']
except:
image_num = None
try:
comment_num = info['detail_info']['comment_num']
except:
comment_num = None
try:
key_words = ''
key_words_list = info['detail_info']['di_review_keyword']
for eachone in key_words_list:
key_words = key_words + eachone['keyword'] + '/'
except:
key_words = None
try:
shop_hours = info['detail_info']['shop_hours']
except:
shop_hours = None
try:
alias = info['detail_info']['alias']
except:
alias = None
try:
scope_type = info['detail_info']['scope_type']
except:
scope_type = None
try:
scope_grade = info['detail_info']['scope_grade']
except:
scope_grade = None
try:
description = info['detail_info']['description']
except:
description = None
sql = """INSERT INTO baidumap.park
(park, location_lat, location_lng, address, street_id, uid, telephone, detail, tag, detail_url, type, overall_rating, image_num,
comment_num, keyword, shop_hours, alias, scope_type, scope_grade, description)
VALUES
(%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s);""" cur.execute(sql, (park, location_lat, location_lng, address, street_id, uid, telephone, detail, tag, detail_url,
type, overall_rating, image_num, comment_num, key_words, shop_hours, alias, scope_type, scope_grade, description,))
conn.commit()
cur.close()
conn.close()
百度地图API获取数据的更多相关文章
- HTML5调用百度地图API获取当前位置并直接导航目的地的方法
<!DOCTYPE html> <html lang="zh-cmn-Hans"> <meta charset="UTF-8&quo ...
- HTML5页面直接调用百度地图API,获取当前位置,直接导航目的地
<!DOCTYPE html> <html lang="zh-cmn-Hans"> <meta charset="UTF-8"&g ...
- Python 读取照片的信息:拍摄时间、拍摄设备、经纬度等,以及根据经纬度通过百度地图API获取位置
通过第三方库exifread读取照片信息.exifread官网:https://pypi.org/project/ExifRead/ 一.安装exifreadpip install exifread ...
- 批量调用百度地图API获取地址经纬度坐标
1 申请密匙 注册百度地图API:http://lbsyun.baidu.com/index.php?title=webapi 点击左侧 “获取密匙” ,经过填写个人信息.邮箱注册等,成功之后在开放平 ...
- 通过netty把百度地图API获取的地理位置从Android端发送到Java服务器端
本篇记录我在实现时的思考过程,写给之后可能遇到困难的我自己也给到需要帮助的人. 写的比较浅显,见谅. 在写项目代码的时候,需要把Android端的位置信息传输到服务器端,通过Netty达到连续传输的效 ...
- PhoneGap Geolocation结合百度地图api获取地理位置api
一.使用百度地图API 1.地址:http://developer.baidu.com/map/ 2.在js DEMO中获取反地址解析的DEMO 3.修改这个DEMO的密钥,去创建应用就能创建密钥,然 ...
- vue项目使用百度地图API获取经纬度
一.首先在百度api注册获得ak密钥 二.进行引入 (1).第一种方式: 直接在vue中index.html中用script标签引入. //你的ak密钥需要替换真实的你的ak码 <script ...
- 通过百度地图API获取经纬度以及两点间距离
package com.baidumap; import java.io.BufferedReader; import java.io.IOException; import java.io.Inpu ...
- 百度统计api获取数据
需求场景 想要了解每天多少人访问了网站,多少个新增用户,地域分布,点击了哪些页面,停留了多久,等等... 国内用的最多的就是百度统计吧,傻瓜式的注册然后插一段代码到项目里就行了. 最近也在自己的博客里 ...
随机推荐
- VMWare中的Host-only、NAT、Bridge的比較
VMWare有Host-only(主机模式).NAT(网络地址转换模式)和Bridged(桥接模式)三种工作模式. 1.bridged(桥接模式) 在这样的模式下.VMWare虚拟出来的操作系统就像是 ...
- 打印二叉树中距离根节点为k的所有节点
package tree; public class Printnodesatkdistancefromroot { /** * Given a root of a tree, and an inte ...
- FastText 分析与实践
一. 前言 自然语言处理(NLP)是机器学习,人工智能中的一个重要领域.文本表达是 NLP中的基础技术,文本分类则是 NLP 的重要应用.在 2016 年, Facebook Research 开源了 ...
- SQLAlchemy框架---ORM思想
- window安装Elasticsearch
下载,https://www.elastic.co/cn/downloads/elasticsearch 下载后解压,进入解压目录,运行./elasticsearch.bat 运行成功如下 (运行需要 ...
- 如何给mysql用户分配权限+增、删、改、查mysql用户
在mysql中用户权限是一个很重析 参数,因为台mysql服务器中会有大量的用户,每个用户的权限需要不一样的,下面我来介绍如何给mysql用户分配权限吧,有需要了解的朋友可参考. 1,Mysql下创建 ...
- Vue Router过渡动效
<router-view> 是基本的动态组件,所以我们可以用 <transition> 组件给它添加一些过渡效果: <transition> <router- ...
- java笔记线程电影院卖票改进版
通过加入延迟后,就产生了连个问题: * A:相同的票卖了多次 * CPU的一次操作必须是原子性的 * B:出现了负数票 * 随机性和延迟导致的 public class SellTicketD ...
- P3258[JLOI2014]松鼠的新家(LCA 树上差分)
P3258 [JLOI2014]松鼠的新家 题目描述 松鼠的新家是一棵树,前几天刚刚装修了新家,新家有n个房间,并且有n-1根树枝连接,每个房间都可以相互到达,且俩个房间之间的路线都是唯一的.天哪,他 ...
- sql 数据库建表
1. 需求 打分和备注是两条记录显示,打分和备注应该放到一张里面吗?放到一张表里面,展示好一些,自己一张表搞定,如果再创建一张表存储备注,需要union all 来进行关联, 感觉性能上有些影响,但是 ...