微服务日志之Spring Boot Kafka实现日志收集
前言
承接上文( 微服务日志之.NET Core使用NLog通过Kafka实现日志收集 https://www.cnblogs.com/maxzhang1985/p/9522017.html ).NET/Core的实现,我们的目地是为了让微服务环境中dotnet和java的服务都统一的进行日志收集。
Java体系下Spring Boot + Logback很容易就接入了Kafka实现了日志收集。
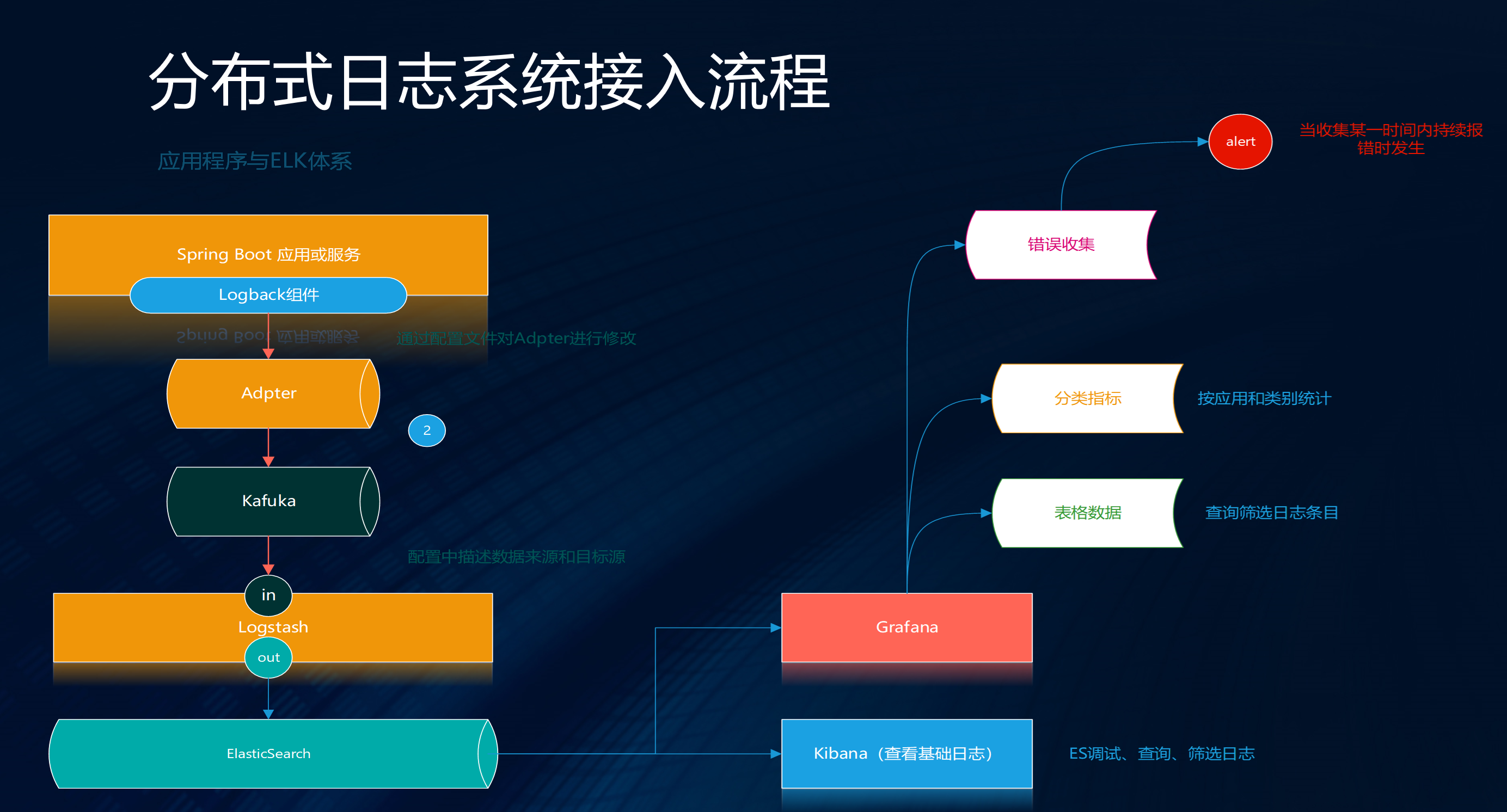
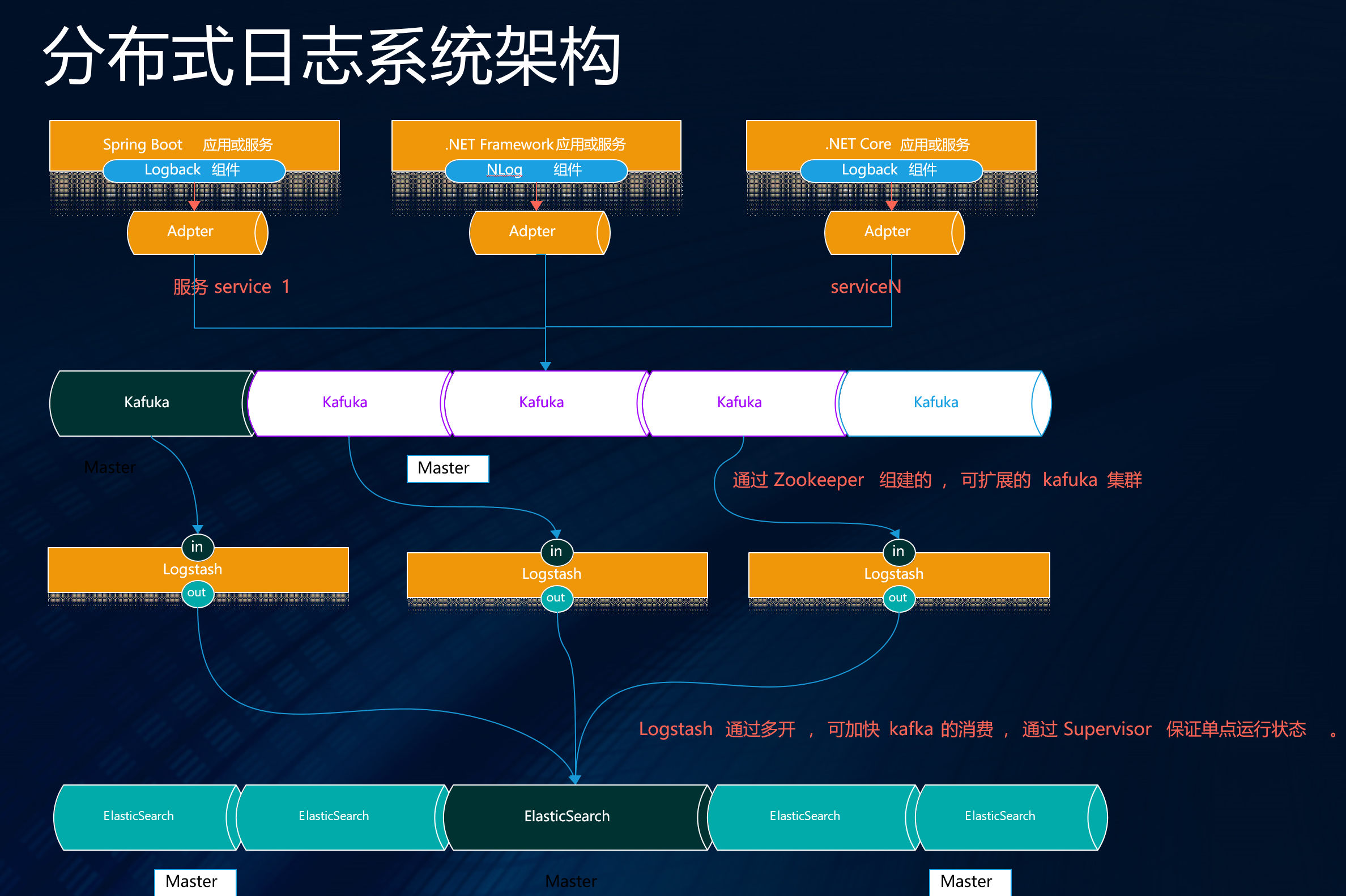
Spring Boot集成
Maven 包管理
<dependencyManagement>
<dependencies>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-core</artifactId>
<version>1.2.3</version>
</dependency>
</dependencies>
</dependencyManagement>
包依赖引用:
<dependency>
<groupId>com.github.danielwegener</groupId>
<artifactId>logback-kafka-appender</artifactId>
<version>0.2.0-RC1</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.3</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>5.0</version>
</dependency>
logback-spring.xml
在Spring Boot项目resources目录下添加logback-spring.xml配置文件,注意:一定要修改 {"appname":"webdemo"},这个值也可以在配置中设置为变量。添加如下配置,STDOUT是在连接失败时,使用的日志输出配置。所以这每个项目要根据自己的情况添加配置。在普通日志输出中使用异步策略提高性能,内容如下:
<appender name="kafkaAppender" class="com.github.danielwegener.logback.kafka.KafkaAppender">
<encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder" >
<customFields>{"appname":"webdemo"}</customFields>
<includeMdc>true</includeMdc>
<includeContext>true</includeContext>
<throwableConverter class="net.logstash.logback.stacktrace.ShortenedThrowableConverter">
<maxDepthPerThrowable>30</maxDepthPerThrowable>
<rootCauseFirst>true</rootCauseFirst>
</throwableConverter>
</encoder>
<topic>loges</topic>
<keyingStrategy class="com.github.danielwegener.logback.kafka.keying.HostNameKeyingStrategy" />
<deliveryStrategy class="com.github.danielwegener.logback.kafka.delivery.AsynchronousDeliveryStrategy" />
<producerConfig>bootstrap.servers=127.0.0.1:9092</producerConfig>
<!-- don't wait for a broker to ack the reception of a batch. -->
<producerConfig>acks=0</producerConfig>
<!-- wait up to 1000ms and collect log messages before sending them as a batch -->
<producerConfig>linger.ms=1000</producerConfig>
<!-- even if the producer buffer runs full, do not block the application but start to drop messages -->
<!--<producerConfig>max.block.ms=0</producerConfig>-->
<producerConfig>block.on.buffer.full=false</producerConfig>
<!-- kafka连接失败后,使用下面配置进行日志输出 -->
<appender-ref ref="STDOUT" />
</appender>
注意:一定要修改 {"appname":"webdemo"} , 这个值也可以在配置中设置为变量 。对于第三方框架或库的错误和异常信息如需要写入日志,错误配置如下:
<appender name="kafkaAppenderERROR" class="com.github.danielwegener.logback.kafka.KafkaAppender">
<encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder" >
<customFields>{"appname":"webdemo"}</customFields>
<includeMdc>true</includeMdc>
<includeContext>true</includeContext>
<throwableConverter class="net.logstash.logback.stacktrace.ShortenedThrowableConverter">
<maxDepthPerThrowable>30</maxDepthPerThrowable>
<rootCauseFirst>true</rootCauseFirst>
</throwableConverter>
</encoder>
<topic>ep_component_log</topic>
<keyingStrategy class="com.github.danielwegener.logback.kafka.keying.HostNameKeyingStrategy" />
<deliveryStrategy class="com.github.danielwegener.logback.kafka.delivery.AsynchronousDeliveryStrategy" />
<deliveryStrategy class="com.github.danielwegener.logback.kafka.delivery.BlockingDeliveryStrategy">
<!-- wait indefinitely until the kafka producer was able to send the message -->
<timeout>0</timeout>
</deliveryStrategy>
<producerConfig>bootstrap.servers=127.0.0.1:9020</producerConfig>
<!-- don't wait for a broker to ack the reception of a batch. -->
<producerConfig>acks=0</producerConfig>
<!-- wait up to 1000ms and collect log messages before sending them as a batch -->
<producerConfig>linger.ms=1000</producerConfig>
<!-- even if the producer buffer runs full, do not block the application but start to drop messages -->
<producerConfig>max.block.ms=0</producerConfig>
<appender-ref ref="STDOUT" />
<filter class="ch.qos.logback.classic.filter.LevelFilter"><!-- 只打印错误日志 -->
<level>ERROR</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
</appender>
在异常日志用使用了同步策略保证,错误日志的有效收集,当然可以根据实际项目情况进行配置。
LOG配置建议:
日志root指定错误即可输出第三方框架异常日志:
<root level="INFO">
<appender-ref ref="kafkaAppenderERROR" />
</root>
建议只输出自己程序里的级别日志配置如下(只供参考):
<logger name="项目所在包" additivity="false">
<appender-ref ref="STDOUT" />
<appender-ref ref="kafkaAppender" />
</logger>
最后
GitHub:https://github.com/maxzhang1985/YOYOFx 如果觉还可以请Star下, 欢迎一起交流。
.NET Core 开源学习群:214741894
微服务日志之Spring Boot Kafka实现日志收集的更多相关文章
- 第二章 微服务构建:Spring Boot
此处介绍Spring Boot的目的除了它是Spring Cloud的基础外,也由于其自身的各项优点,如自动化配置.快速开发.轻松部署等,非常适合用作微服务架构中各项具体微服务的开发框架. 本章内容: ...
- 微服务构建: Spring Boot
在展开 Spring Cloud 的微服务架构部署之前, 我们先了解一下用于构建微服务的基础框架-Spring Boot. 由于 Spring Cloud 的构建基于 Spring Boot 实现, ...
- Spring Boot (九): 微服务应用监控 Spring Boot Actuator 详解
1. 引言 在当前的微服务架构方式下,我们会有很多的服务部署在不同的机器上,相互是通过服务调用的方式进行交互,一个完整的业务流程中间会经过很多个微服务的处理和传递,那么,如何能知道每个服务的健康状况就 ...
- 手撕面试官系列(三):微服务架构Dubbo+Spring Boot+Spring Cloud
文章首发于今日头条:https://www.toutiao.com/i6712696637623370248/ 直接进入主题 Dubbo (答案领取方式见侧边栏) Dubbo 中 中 zookeepe ...
- 微服务架构之spring boot admin
Spring boot admin是可视化的监控组件,依赖spring boot actuator收集各个服务的运行信息,通过spring boot actuator可以非常方便的查看每个微服务的He ...
- SpringCloud 微服务一:spring boot 基础项目搭建
spring cloud是建立在spring boot的基础上的,而之前虽然听说过,也随便看了一下spring boot,却没有真正使用,因此还必须先花时间学一下spring boot. spring ...
- 微服务学习笔记——Spring Boot特性
1. 创建独立的Spring应用程序 2. 嵌入的Tomcat,无需部署WAR文件 3. 简化Maven配置 4. 自动配置Spring 5. 提供生产就绪型功能,如指标,健康检查和外部配置 6. 开 ...
- 微服务架构-选择Spring Cloud,放弃Dubbo
Spring Cloud 在国内中小型公司能用起来吗?从 2016 年初一直到现在,我们在这条路上已经走了一年多. 在使用 Spring Cloud 之前,我们对微服务实践是没有太多的体会和经验的.从 ...
- Spring Cloud与微服务构建:Spring Cloud简介
Spring Cloud简介 微服务因该具备的功能 微服务可以拆分为"微"和"服务"二字."微"即小的意思,那到底多小才算"微&q ...
随机推荐
- SecureCR 改变背景色和文字颜色
1.打开SecureCR链接Linux服务器,Options->Session Options->Emulation->Terminal 选择Linux (相应的服务器系统)ANSI ...
- python 在window 系统 连接并操作远程 oracle 数据库
1,python 连接 oracle 需要 oracle 自身的客户端 instantclient,可以去官网下载自己需要的版本, https://www.oracle.com/technetwor ...
- django 数据库查询的几个知识点
django查询db过程中遇到的几个问题: 1. 数据库切换,用using products = models.TProductCredit.objects.using(') 2.查询结构集是Quer ...
- HTML-全局属性 / 事件属性(转)
拷贝自:< http://www.runoob.com > HTML 全局属性 New : HTML5 新属性. 属性 描述 accesskey 设置访问元素的键盘快捷键. class 规 ...
- 深入浅出PF 学习笔记---TypeConverter
StringToHumanTypeConverter类(从TypeConverter继承 using System; using System.Collections.Generic; using S ...
- python的if条件判断
python的条件判断书写格式: 基本格式 if 条件判断: #条件判断通过,则执行下面的语句 执行语句 执行语句 ... else: #条件判断不通过,则执行下面的语句 执行语句 执行语 ...
- Aspose.word
http://my.oschina.net/dancefires/blog/217858
- Django的rest_framework的分页组件源码分析
前言: 分页大家应该都很清楚,今天我来给大家做一下Django的rest_framework的分页组件的分析:我的讲解的思路是这样的,分别使用APIview的视图类和基于ModelViewSet的视图 ...
- Java15-java语法基础(十五)——内部类
java16-java语法基础(十五)内部类 一.内部类: 可以在一个类的内部定义另一个类,这种类称为内部类. 二.内部类分为两种类型: 1.静态内部类: 静态内部类是一个具有static修饰词的类, ...
- android的事件分发传递机制
事件的分发与传递最重要的三个处理方法是 dispatchTouchEvent onInterceptTouchEvent onTouchEvent 综合来说事件的 传递是由外层向里层传递,而处理是从里 ...