你真的会打 Log 吗
前言
工程师在日常开发工作中,更多的编码都是基于现有系统来进行版本迭代。在软件生命周期中,工程维护的比重也往往过半。当我们维护的系统出现问题时,第一时间想到的是查看日志来判断问题原因,这时候日志记录如果没有提供有效的信息,我们能做的只有深度 Code Review,耗时不说且效率低下。
日志
日志记录的好坏直接关系到系统出现问题时定位原因的速度。不少工程中都记录了挺多日志,但在实际问题排查中起到的作用却不大,开发人员还是需要打开 IDE 通过读代码来定位原因。那到底怎样的日志记录更合适呢?我们可以先思考一下这几个问题:
1.记录日志的目的?
2.什么是有效的日志?
3.记录日志的原则?
首先,日志需要用来记录用户操作、系统运行状态等信息,是一个系统的重要组成部分。然而由于日志并非系统核心功能,通常情况下并得不到开发人员的重视。在出现问题需要通过日志来定位时,才暴露中现有日志记录的很多不足。
其次,通过对日志的观察和分析,提前发现系统的潜在风险,避免线上事故的发生。
最终目标:线上系统出现问题时,通过日志就可以快速定位原因。
日志级别
这里介绍常用日志级别的同时顺带介绍一下不常见的日志级别 FATAL 和 TRACE。
FATAL - 表示需要立即被处理的系统级错误。当该错误发生时,服务已经出现了某种程度的不可用,系统管理员需要立刻处理。这是最严重的日志级别,因此该日志级别要慎用,如果这种级别的日志经常出现,那这日志也失去了意义。通常情况下,一个进程的生命周期中应该只记录一次FATAL级别的日志,即该进程遇到无法恢复的错误而退出时。
TRACE - 这个级别日志在开源框架中还挺常见,和DEBUG级别很像,主要作用是对系统每一步的运行状态进行精确的记录。通过它,可以查看某一个操作每一步的执行过程,精确定位是什么操作,有什么参数,执行顺序是怎样,最终导致了什么错误的发生。同时可以保证在不重现错误的情况下,通过分析 TRACE 级别的日志即可完成对问题的诊断。TRACE 和 DEBUG 用法相似,具体规范应该由团队自己定义,应该保证日志内容除了开发人员以外,运维、测试人员也可以通过 TRACE(或 DEBUG)日志来定位问题。
ERROR - 该级别的错误也需要马上被处理,但是紧急程度要低于FATAL。当ERROR错误发生时,已经影响了正常的业务功能。从这个意义上来说,实际上ERROR错误和FATAL错误对用户的影响是相当的。FATAL相当于整个服务已经挂了,而ERROR表示系统出现错误,但还能提供服务,只能不断地打印ERROR日志。特别需要注意的是,ERROR应当属于服务自己的异常,是需要马上得到人工介入并处理的,如果出现了ERROR日志业务上又不需要处理的就不应该记为ERROR级别,这一点是区别于INFO的明显标识。例如由于用户自己操作不当,传入非法请求参数时,是绝对不应该记为ERROR级别;还有业务处理结果为失败的情况,比如扣款操作遇到用户余额不足,也不能记为ERROR。
INFO - 该种日志记录系统处理业务的概要信息,例如一个业务请求的入参和执行结果以及耗时等等。通过查看INFO级别的日志,可以很快地对系统中业务情况有个基本了解,有哪些业务处理成功哪些又失败了。INFO日志不宜过多,太多的话造成信息干扰不利于查问题;
WARN - 该日志表示系统可能出现问题,也可能没有,标识的是系统潜在问题,例如网络抖动造成的rpc调用时长超过阈值。对于那些目前还不是错误,然而不及时处理也会变为错误的情况,也可以记为WARN日志,例如一个存储系统的磁盘使用量超过阀值,或者系统中某个用户的存储配额快用完等等。对于WARN级别的日志,虽然不需要系统管理员马上处理,也是需要即使查看并处理的。因此此种级别的日志也不应太多,能不打WARN级别的日志,就尽量不要打;
Rule 1:整个团队(包括运维)对日志级别有明确规范。
Rule 2:绝不打印没有用的日志,防止无用日志淹没重要信息。
日志维护
通过系统出现的问题来优化日志,是一项长期的实践,不断地从日志发现系统的问题,不断地从系统错误发现日志的问题。
1.定义好整个团队记录INFO、DEBUG(或TRACE)日志规范,保证每个开发记录的日志格式统一;
2.整个团队(包括开发,运维和测试)定期对记录的日志内容进行Review;
3.通过查问题的过程来不断优化日志记录;
4.运维或测试在日志中发现的问题,需要及时向开发人员反映
在线上出现问题的时候,需要尽快发现问题并解决;同时,需要借此机会好好思考一下当前系统的日志是否合理,应该考虑以下问题:
1.如果定位问题花费了很长时间,那就说明系统日志还存在问题,需要进一步完善和优化。
2.需要思考是否可以通过优化日志,来提前预判该问题是否可能发生(如某种资源耗尽而导致的错误,可以对资源的使用情况进行记录)。
通过系统出现的问题来优化日志,是一项长期实践,需要不断从日志中发现系统的问题,同时也需要不断从系统异常中发现日志的问题。
Rule 3: 定期对日志内容进行优化更新。
日志格式
日志格式一定要统一,不能任由开发人员的喜好来。系统中日志格式不统一,不利于自动化处理。不要出现个性化的日志,否则可能只有开发人员自己才能看懂。比如 logback 中 pattern 的格式,以及日志的切分轮转策略,团队内应该有统一的标准。
这么做的好处很明显:团队内任何一个人甚至团队以外的人看到这段错误日志时,都能根据记录的有效信息来帮助快速定位问题。
Rule 4: 把日志的格式、大小,切分轮转策略等作为规范建立起来。
实践
这里介绍一下账户团队在工程维护中对日志实践的一些经验。
原先日志文件有3个:info.log, error.log, sql.log,日志按天轮转保留 3 天,info、error 记录混乱没有明显区别。这里来几个教科书级别的错误示范,贴几段遗留 INFO 级别日志。
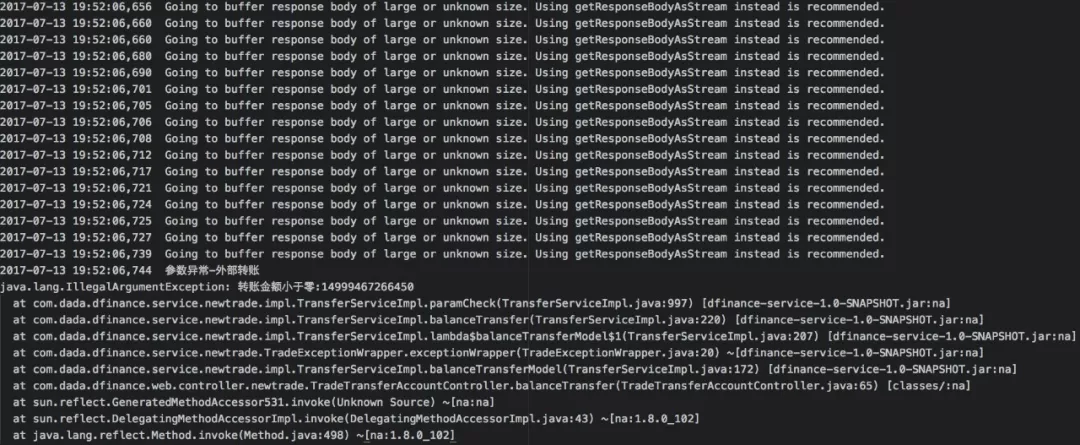
大量 "Going to buffer response body" 无效日志信息,这里只展示了一部分。
异常堆栈信息绝不应该出现在 INFO 级别日志中。
异常中一串数字 “14999467266450” 是个啥,根本看不懂,只能去看代码。
有堆栈信息却没有原始请求参数,排错无从下手。
后面定位到确实是转账金额小于零,但传入非法参数绝不应该记录为ERROR,更不应该打印堆栈信息,因为这不表示服务本身有问题。
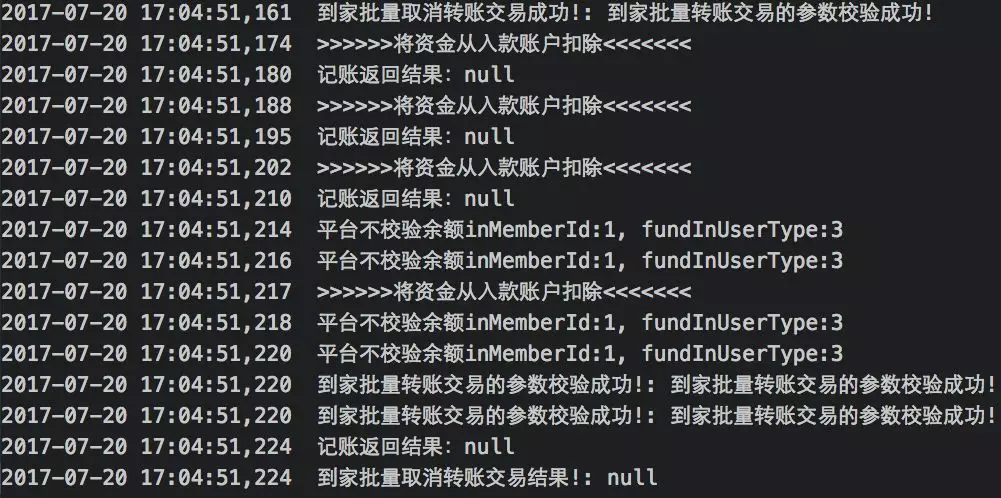
没有原始请求参数和响应返回。
日志记录区分不开是由几个请求产生。
线上出现问题时,光是寻找日志中的“蛛丝马迹”就花去不少时间,还是得靠 Code Review 来解决。开发环境联调,系统之间 rpc 调用没有日志记录,出了问题也不知道哪个环节出错。
针对上面这些情况,是时候做一些改变了,经过团队商议,对日志做了一些改造,重点解决2个问题:
系统间相互调用的入参出参必须记录。
能快速找到由一个请求产生的所有日志。
日志分类
info.log:业务关键步骤信息。 error.log:业务发生的错误以及堆栈信息。 sql_info.log:超过10ms的SQL调用。 api_info.log:api调用的关键信息。 rpc_info.log:rpc调用的信息。
这里说下api_info.log、rpc_info.log,这会是分布式系统中相互调用的关键凭证,里面记录了这些信息:
请求参数
traceId,日志追踪使用的唯一ID
请求客户端IP(rpc日志中记录目标服务端IP端口)
响应参数
处理耗时
和运维团队沟通后,统一了 logback pattern 配置:

张同学:这里说的 traceId 是个啥?
traceId 的作用是把分散在各个日志文件中的日志信息都串起来,即一个请求产生的所有日志都有同一个唯一的 traceId,这样在ELK中查询日志时,把 traceId 作为查询条件一步就把这次请求的所有日志都查出来。同时 traceId 作为响应参数之一,便于系统间排查问题。
李同学:traceId 需要侵入线程上下文,在不对业务代码做修改的情况下,有办法实现吗?
当然是有的,在 Controller 的 AOP 中使用 slf4j MDC 把 traceId 放到线程上下文,对业务编码无入侵。traceId 的生成策略,可以有很多选择,只要在当天的日志索引中唯一即可,并没有太强的要求,账户团队最后使用的是毫秒时间戳 + 幂等ID + 6位随机数。

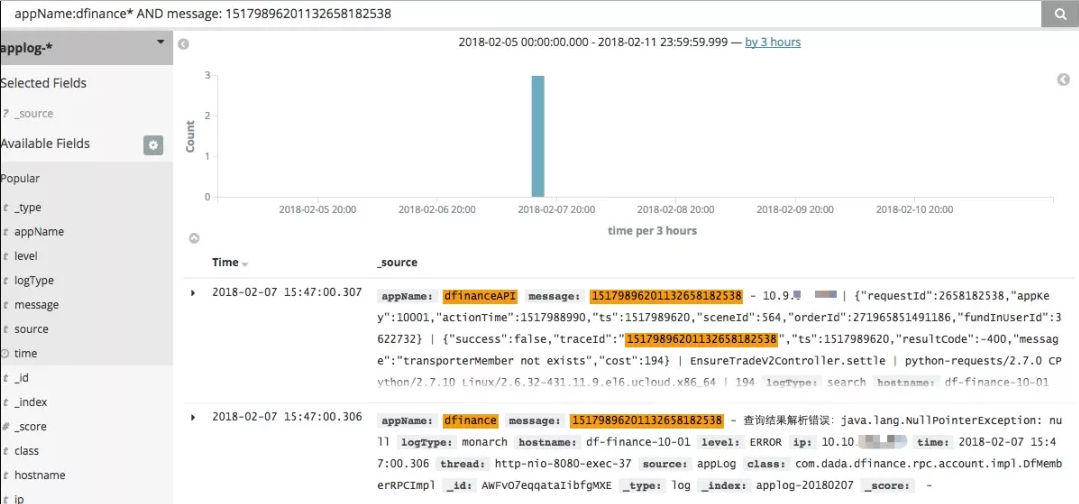
有了 traceId 之后,通过日志定位问题就只有2步:
根据业务关键字信息查询 api.log,找到原始的入参和返回值。
如果返回参数不够清楚,根据其中 traceId 可以把所有日志都查出来,能清楚看到关键步骤、 rpc 调用和异常 error 信息。
监控、报警
最后介绍一下达达运维团队提供基于日志监控的实时报警系统。
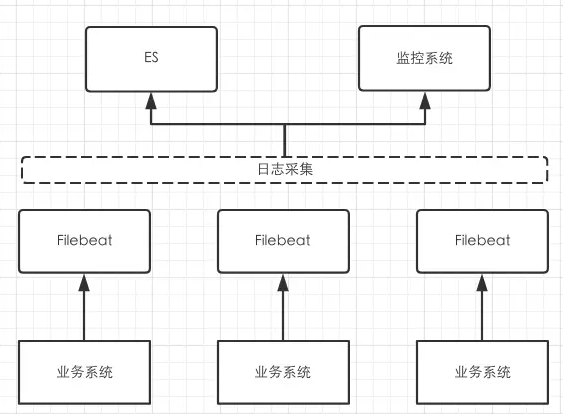
上面提到对于 ERROR 级别的日志,需要立即介入处理,所以这是日志中的重点监控对象。这套架构中 Filebeat 负责把日志实时采集到监控系统中用以分析,监控系统同时提供多种灵活的报警策略,支持邮件、短信、电话等多种报警形式。
监控报警的场景不仅限于ERROR级别,我们通过监控 INFO 级别日志可以发现一些系统的潜在风险,比如中间件或者 rpc 调用时长超过 100ms,在1分钟内出现超过 20 次,需要报警提醒。我们可以根据业务特点,和运维一块设定灵活的报警策略
规约
1.【强制】应用中不可直接使用日志系统(Log4j、Logback)中的API,而应依赖使用日志框架SLF4J中的API,使用门面模式的日志框架,有利于维护和各个类的日志处理方式统一。
import org.slf4j.Logger; import org.slf4j.LoggerFactory; private static final Logger logger = LoggerFactory.getLogger(Abc.class);
2.【强制】日志文件至少保存15天,因为有些异常具备以"周"为频次发生的特点。
3.【强制】应用中的扩展日志(如打点、临时监控、访问日志等)命名方式:
appName_logType_logName.log。
logType:日志类型,如stats/monitor/access等;logName:日志描述。这种命名的好处:通过文件名就可知道日志文件属于什么应用,什么类型,什么目的,也有利于归类查找。
正例:mppserver应用中单独监控时区转换异常,如:mppserver_monitor_timeZoneConvert.log
说明:推荐对日志进行分类,如将错误日志和业务日志分开存放,便于开发人员查看,也便于通过日志对系统进行及时监控。
4.【强制】对trace/debug/info级别的日志输出,必须使用条件输出形式或者使用占位符的方式,禁止使用String的"+"来输出字符串。
说明:logger.debug("Processing trade with id: " + id + " and symbol: " + symbol);
如果日志级别是warn,上述日志不会打印,但是会执行字符串拼接操作,如果symbol是对象,会执行toString()方法,浪费了系统资源,执行了上述操作,最终日志却没有打印。
正例:(条件)建设采用如下方式
if (logger.isDebugEnabled()) {
logger.debug("Processing trade with id: " + id + " and symbol: " + symbol);
}
正例:(占位符)
logger.debug("Processing trade with id: {} and symbol : {} ", id, symbol);
5.【强制】避免重复打印日志,浪费磁盘空间,务必在 log4j.xml中设置additivity=false。
正例:<logger name="com.taobao.dubbo.config" additivity="false">
6. 【强制】异常信息应该包括两类信息:案发现场信息和异常堆栈信息。如果不处理,那么通过关键字throws往上抛出。
不要在引号里面加上{},这样就可以输出整个异常栈,更利于定位问题
正例:logger.error(各类参数或者对象 toString() + "_" + e.getMessage(), e);
7. 【推荐】谨慎地记录日志。生产环境禁止输出debug日志;有选择地输出info日志;如果使用warn来记录刚上线时的业务行为信息,一定要注意日志输出量的问题,避免把服务器磁盘撑爆,并记得及时删除这些观察日志。
说明:大量地输出无效日志,不利于系统性能提升,也不利于快速定位错误点。记录日志时请思考:这些日志真的有人看吗?看到这条日志你能做什么?能不能给问题排查带来好处?
8. 【推荐】可以使用warn日志级别来记录用户输入参数错误的情况,避免用户投诉时,无所适从。如非必要,请不要在此场景打出error级别,避免频繁报警。
说明:注意日志输出的级别,error级别只记录系统逻辑出错、异常或者重要的错误信息。
9. 【推荐】尽量用英文来描述日志错误信息,如果日志中的错误信息用英文描述不清楚的话使用中文描述即可,否则容易产生歧义。国际化团队或海外部署的服务器由于字符集问题,【强制】使用全英文来注释和描述日志错误信息。
PS:打印日志的时候最好把入参和响应打印到一条日志里面,这样更容易定位问题。
LOGGER.info("XXXXX execute complete , params:{} , result:{}", JsonUtil.toJson(YYYYY), JsonUtil.toJson(ZZZZZZ));
总结
为了实现仅通过日志信息就能定位问题的最终目标,更为了有效提高工程质量,我们最后再回顾一下日志记录的几个标准操作。
团队(包括运维)对日志级别有明确规范。
绝不打印没有用的日志。
定期对日志内容进行优化更新。
日志格式、大小,切分轮转策略需要形成规范。
你真的会打 Log 吗的更多相关文章
- Java日志框架中真的需要判断log.isDebugEnabled()吗?
在项目中我们经常可以看到这样的代码: if (logger.isDebugEnabled()) { logger.debug(message); } 简单来说,就是用isDebugEnabled方法判 ...
- Log4j2 - 日志框架中isDebugEnabled()的作用
为什么要使用isDebugEnabled() 之前在系统的代码中发现有时候会在打印日志的时候先进行一次判断,如下: if (LOGGER.isDebugEnabled()) { LOGGER.debu ...
- 重识线段树——Let's start with the start.
声明 本文为 Clouder 原创,在未经许可情况下请不要随意转载.原文链接 前言 一般地,这篇文章是给学习过线段树却仍不透彻者撰写的,因此在某些简单的操作上可能会一笔带过. 当然了,入门线段树后也可 ...
- console.log出来的信息不一定是真的
一.问题 拿接口取值,明明this.props.chartsValue[0]已经返回json数据,结果this.props.chartsValue[0].history报错:无法获得undefined ...
- [C#] C# 知识回顾 - 你真的懂异常(Exception)吗?
你真的懂异常(Exception)吗? 目录 异常介绍 异常的特点 怎样使用异常 处理异常的 try-catch-finally 捕获异常的 Catch 块 释放资源的 Finally 块 一.异常介 ...
- 您真的理解了SQLSERVER的日志链了吗?
您真的理解了SQLSERVER的日志链了吗? 先感谢宋沄剑给本人指点迷津,还有郭忠辉童鞋今天在QQ群里抛出的问题 这个问题跟宋沄剑讨论了三天,再次感谢宋沄剑 一直以来,SQLSERVER提供了一个非常 ...
- 你真的了解DOM事件么?
你真的了解DOM事件么? 我们大家都知道,人与人之间的交流可以通过语言,文字,肢体动作,面部微表情等,但是你知道Javascript和HTML之间是通过什么进行交互的么?你又知道Javascript和 ...
- MYSQL 5.7 无法启动(Could not open error log file errno 2)
前两天电脑中毒, 病毒好像把mysql的 log.err 文件给删掉了.然后服务一直启动不了:Could not open error log file errno 2. 然后疯狂百度,搜索的结果大多 ...
- oc swizzling 真的好用
Objective-C的hook方案(一): Method Swizzling 在没有一个类的实现源码的情况下,想改变其中一个方法的实现,除了继承它重写.和借助类别重名方法暴力抢先之外,还有更加灵活 ...
随机推荐
- 牛客挑战赛30 小G砍树 树形dp
小G砍树 dfs两次, dp出每个点作为最后一个点的方案数. #include<bits/stdc++.h> #define LL long long #define fi first # ...
- python--smtp邮件使用
#构建对象时,第一个是邮件正文,第二个发送类型,plain表示纯文本,最后使用utf-8保证多语言兼容 #如果需要发送html的话,就把plain改为html------>内容使用html构造便 ...
- TopCoder SRM500 Div1 1000 其他
原文链接https://www.cnblogs.com/zhouzhendong/p/SRM500-1000.html SRM500 Div1 1000 设 \(v_1,v_2,\cdots ,v_9 ...
- IISExpress运行网站时,Service Fabric报Could not load file or assembly 'Microsoft.ServiceFabric.Data' or one of its dependencies. An attempt was made to load a program with an incorrect format.
打开VS TOOLS > OPTIONS > Projects and Solutions > WEB PROJECTS,选中 "Use the 64 bit vers ...
- web发展阶段简介
web1.0.web2.0和web3.0的区别前言: 其实并没有什么所谓的2.0.3.0,因为你没法准确的界定它是什么样的应用,也没法界定它是什么时候开始的,什么时候结束,它只是互联网本身发展的一种 ...
- Http和RPC区别
本文转自:https://blog.csdn.net/mou_it/article/details/79873612 RPC(即Remote Procedure Call,远程过程调用)和HTTP(H ...
- 解决UnicodeEncodeError: ‘ascii’ codec can’t encode characters in position
最近用Python写了些爬虫,在爬取一个gb2312的页面时,抛出异常: UnicodeEncodeError: 'ascii' codec can't encode characters in po ...
- BOM 和 DOM
目录 一.BOM 1.什么是BOM 2. 浏览器内容划分 归BOM管的: 归DOM管的: 3. BOM常见方法 二.DOM 1 什么是DOM 2. DOM常见方法 一.BOM 1.什么是BOM BOM ...
- SpringMvc请求处理流程与源码探秘
流程梳理 dispatcherServlet作为前端控制器的主要作用就是接受请求与处理响应. 不过它不是传统意义上的servlet,它在接受到请求后采用转发的方式,将具体工作交给专业人士去做. 参与角 ...
- JAVAScript:前端模块化开发
目录 一:前端模块化概要 1.1.模块化概要 1.2.函数封装 1.3.对象封装 1.4.立即执行函数表达式(IIFE) 1.5.模块化规范 1.5.1.CommonJS 1.5.2.AMD((Asy ...