Linux内核分析作业 NO.6
进程的描述和进程的创建
于佳心 原创作品转载请注明出处 《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000
实验 分析一个Linux内核创建新进程的过程
首先,按照之前学过的方法,删除menu,并克隆一个新menu
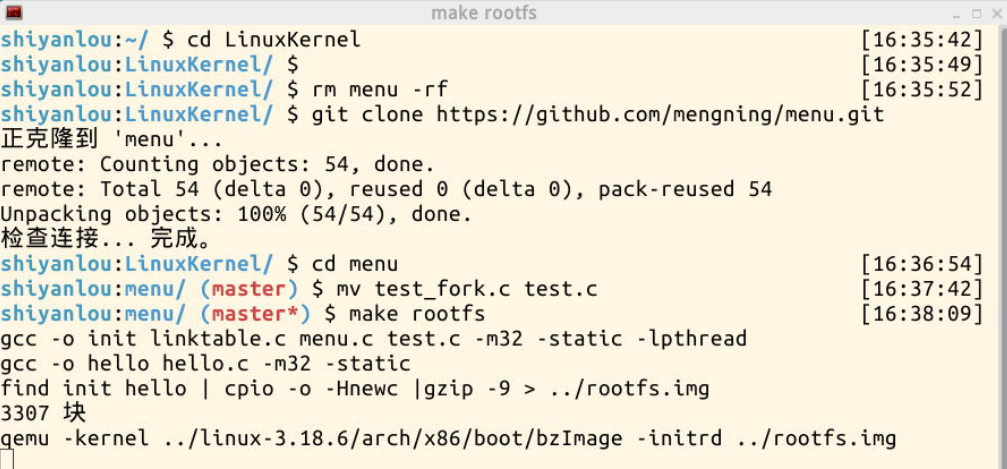
输入make rootfs之后

在qemu界面输入fork
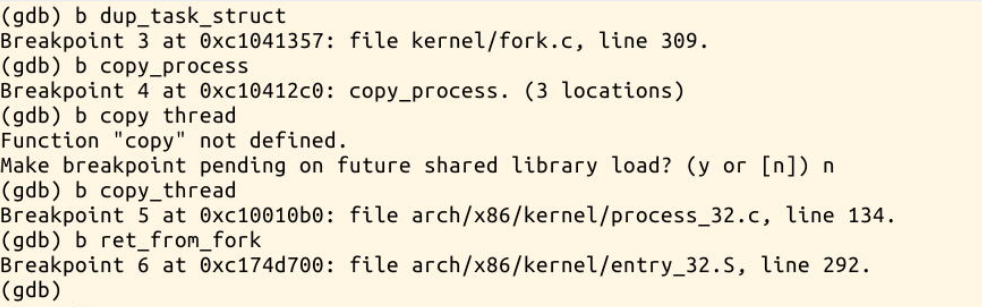
设置很多很多断点

在设置了一系列断点之后,开始一步一步的运行。
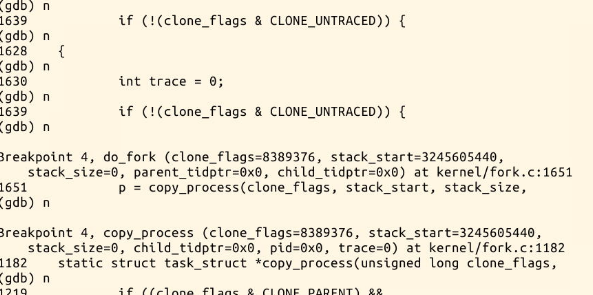
通过实验我们发现:
新进程开始的地方是ret_from_fork
在ret_from_fork之前,copy_thread()函数中
*childregs = *current_pt_regs();
父进程的regs参数赋值到子进程的内核堆栈中。
总结
一、进程的描述
操作系统有三大功能:进程管理、内存管理、文件系统,其中以进程管理为核心
操作系统有三个状态:操作态、运行态、阻塞态
但是在进程管理中不太一样,比如就绪状态和运行状态都是TASK_RUNNING
进程的状态变化如图:
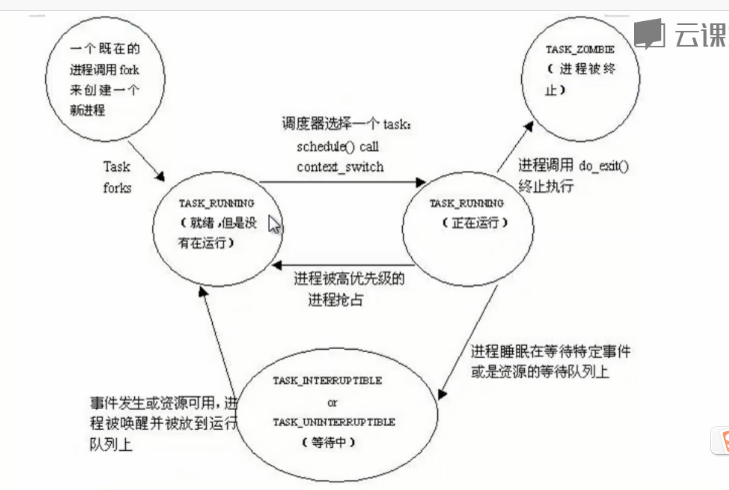
为了管理进程,内核必须对每个进程进行清晰的描述,进程描述符提供了内核所需了解的进程信息。
struct task_struct数据结构很庞大
1235 struct task_struct {
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
void *stack;
atomic_t usage;
unsigned int flags; /* per process flags, defined below */
unsigned int ptrace;
state表示运行状态
stack 进程的内核堆栈
usage、flags 进程的标识符
#ifdef CONFIG_SMP
struct llist_node wake_entry;
int on_cpu;
struct task_struct *last_wakee;
unsigned long wakee_flips;
unsigned long wakee_flip_decay_ts; int wake_cpu;
#endif
int on_rq;
SMP是条件编译,多处理器会用到
rq 运行队列
后面又有一堆和优先级、调度相关的代码,我们先不管它们。
1301struct mm_struct *mm, *active_mm;
#ifdef CONFIG_COMPAT_BRK
unsigned brk_randomized:;
#endif
内存管理,进程的地址空间相关,代码段、数据段都要和它打交道
每个进程都有自己的进程地址空间
struct list_head ptraced;
调试
struct pid_link pids[PIDTYPE_MAX];
哈希表,用于查找
cputime_t utime, stime, utimescaled, stimescaled;
cputime_t gtime;
#ifndef CONFIG_VIRT_CPU_ACCOUNTING_NATIVE
struct cputime prev_cputime;
#endif
#ifdef CONFIG_VIRT_CPU_ACCOUNTING_GEN
seqlock_t vtime_seqlock;
unsigned long long vtime_snap;
enum {
VTIME_SLEEPING = ,
VTIME_USER,
VTIME_SYS,
} vtime_snap_whence;
#endif
时间相关
struct signal_struct *signal;
struct sighand_struct *sighand;
信号处理相关
struct pipe_inode_info *splice_pipe;
管道相关
进程的标识符pid
pid_t pid;
pid_t tgid;
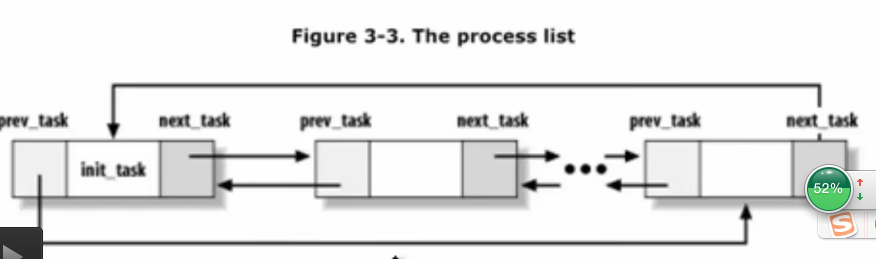
所有进程链表struct list_head tasks;
struct list_head thread_group;
struct list_head thread_node;
进程链表相关,把相关的进程链起来
内核的双向循环链表的实现方法 - 一个更简略的双向循环链表
1295struct list_head tasks;
#ifdef CONFIG_SMP
struct plist_node pushable_tasks;
struct rb_node pushable_dl_tasks;
#endif
这个结构就是双向循环的进程链表
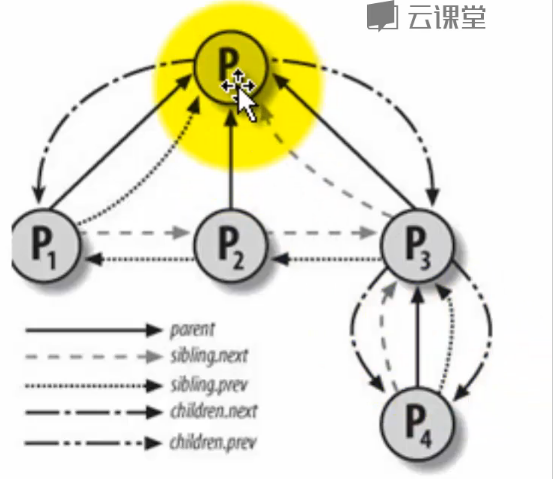
程序创建的进程具有父子关系,在编程时往往需要引用这样的父子关系。进程描述符中有几个域用来表示这样的关系
struct task_struct __rcu *real_parent; /* real parent process */
struct task_struct __rcu *parent; /* recipient of SIGCHLD, wait4() reports */
/*
1345 * children/sibling forms the list of my natural children
1346 */
struct list_head children; /* list of my children */
struct list_head sibling; /* linkage in my parent's children list */
struct task_struct *group_leader; /* threadgroup leader */
Linux为每个进程分配一个8KB大小的内存区域,用于存放该进程两个不同的数据结构:Thread_info和进程的内核堆栈
进程处于内核态时使用, 不同于用户态堆栈,即PCB中指定了内核栈
内核控制路径所用的堆栈 很少,因此对栈和Thread_info 来说,8KB足够了
struct thread_struct thread; //CPU-specific state of this task cpu相关,进行上下文切换
打开thread具体代码,其中有一个thread_struct,esp和eip就存在这里
文件系统和文件描述符
struct fs_struct *fs;
文件相关,进程地址空间,内存管理空间
struct files_struct *files;
打开的文件描述符列表
进程的创建
复习:
0号进程是我们自己写入的
1号进程复制0号进程的PCB,再加入可执行文件
1号进程是所有用户态进程的祖先
2号进程是所有内核线程的祖先
于是我们明白,进程的创建即是从父进程复制一份子进程,并做合理的修改
那么用shell命令行怎么创建一个子进程呢?
fork() 是在用户态用于创建一个子进程的系统调用
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(int argc, char * argv[])
{
int pid;
/* fork another process */
pid = fork();
if (pid < )
{
/* error occurred */
fprintf(stderr,"Fork Failed!");
exit(-1);
}
else if (pid == 0)
{
/* child process */
printf("This is Child Process!\n");
}
else
{
/* parent process*/
printf("This is Parent Process!\n");
/* parent will wait for the child to complete*/
wait(NULL);
printf("Child Complete!\n");
}
}
如代码中的英文注释所说,当返回值<0时,出错处理,返回值==0时,子程序执行,这里需要注意的是,else后面的内容也一起执行
这是因为fork系统调用是在父进程和子进程各返回一次的
子程序的返回值是0,父进程的返回值是子进程的ID
系统调用的过程回顾:
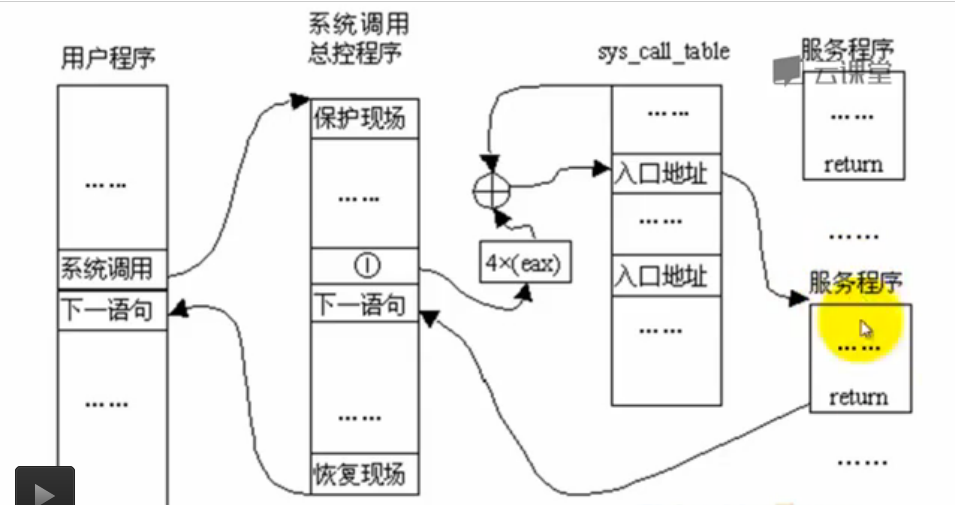
子进程是从哪里开始执行的?
在内核里开始执行,fork返回。新进程执行的起点是我们设立的。
理解复杂的事物要预设一个大致的框架。
创建进程框架:
创建新进程是通过复制当前进程来实现的,大多数地方都一样,但是父子进程的pid不一样,内核堆栈也不一样,thread也不一样
虚拟设想:
复制进程PCB,修改复制完的PCB,分配新的内核堆栈,内核堆栈的一部分也需要拷贝,根据状况设定eip、esp的位置
创建一个新进程在内核中的执行过程
fork、vfork和clone三个系统调用都可以创建一个新进程,而且都是通过调用do_fork来实现进程的创建;
Linux通过复制父进程来创建一个新进程,那么这就给我们理解这一个过程提供一个想象的框架:
复制一个PCB——task_struct
err = arch_dup_task_struct(tsk, orig);
要给新进程分配一个新的内核堆栈
ti = alloc_thread_info_node(tsk, node);
tsk->stack = ti;
setup_thread_stack(tsk, orig); //这里只是复制thread_info,而非复制内核堆栈要修改复制过来的进程数据,比如pid、进程链表等等都要改改吧,见copy_process内部。
从用户态的代码看fork();函数返回了两次,即在父子进程中各返回一次,父进程从系统调用中返回比较容易理解,子进程从系统调用中返回,那它在系统调用处理过程中的哪里开始执行的呢?这就涉及子进程的内核堆栈数据状态和task_struct中thread记录的sp和ip的一致性问题,这是在哪里设定的?copy_thread in copy_process
*childregs = *current_pt_regs(); //复制内核堆栈
childregs->ax = ; //为什么子进程的fork返回0,这里就是原因!
p->thread.sp = (unsigned long) childregs; //调度到子进程时的内核栈顶
p->thread.ip = (unsigned long) ret_from_fork; //调度到子进程时的第一条指令地址这一次的新内容好多,越来越难了,对代码的理解越来越吃力,不是老师讲的不好,但是我一听到代码的部分就快睡着了,宝宝心好累。
求高分!
Linux内核分析作业 NO.6的更多相关文章
- linux内核分析作业8:理解进程调度时机跟踪分析进程调度与进程切换的过程
1. 实验目的 选择一个系统调用(13号系统调用time除外),系统调用列表,使用库函数API和C代码中嵌入汇编代码两种方式使用同一个系统调用 分析汇编代码调用系统调用的工作过程,特别是参数的传递的方 ...
- Linux内核分析作业7:Linux内核如何装载和启动一个可执行程序
1.可执行文件的格式 在 Linux 平台下主要有以下三种可执行文件格式: 1.a.out(assembler and link editor output 汇编器和链接编辑器的输出) ...
- linux内核分析作业6:分析Linux内核创建一个新进程的过程
task_struct结构: struct task_struct { volatile long state;进程状态 void *stack; 堆栈 pid_t pid; 进程标识符 u ...
- linux内核分析作业5:分析system_call中断处理过程
1.增加 Menu 内核命令行 调试系统调用. 步骤:删除menu git clone (tab) make rootfs 这就是我们将 fork 函数写入 Menu 系统内核后的效果, ...
- linux内核分析作业:以一简单C程序为例,分析汇编代码理解计算机如何工作
一.实验 使用gcc –S –o main.s main.c -m32 命令编译成汇编代码,如下代码中的数字请自行修改以防与他人雷同 int g(int x) { return x + 3; } in ...
- linux内核分析作业:操作系统是如何工作的进行:完成一个简单的时间片轮转多道程序内核代码
计算机如何工作 三个法宝:存储程序计算机.函数调用堆栈.中断机制. 堆栈 函数调用框架 传递参数 保存返回地址 提供局部变量空间 堆栈相关的寄存器 Esp 堆栈指针 (stack pointer) ...
- linux内核分析作业3:跟踪分析Linux内核的启动过程
内核源码目录 1. arch:录下x86重点关注 2. init:目录下main.c中的start_kernel是启动内核的起点 3. ipc:进程间通信的目录 实验 使用实验楼的虚拟机打开shell ...
- linux内核分析作业4:使用库函数API和C代码中嵌入汇编代码两种方式使用同一个系统调用
系统调用:库函数封装了系统调用,通过库函数和系统调用打交道 用户态:低级别执行状态,代码的掌控范围会受到限制. 内核态:高执行级别,代码可移植性特权指令,访问任意物理地址 为什么划分级别:如果全部特权 ...
- Linux内核分析作业 NO.8 完结撒花~~~
进程的切换和系统的一般执行过程 于佳心 原创作品转载请注明出处 <Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC-10000 ...
- Linux内核分析作业 NO.7
可执行程序的装载 于佳心 原创作品转载请注明出处 <Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC-1000029000 实 ...
随机推荐
- ST_Geometry效率的测试与分析
测试环境 数据库:Oracle11g R1(11.1.0.6) 64Bit 中间件:ArcSDE10 (64Bit) 数据情况:点数据(point,231772条记录),面数据(poly,12条记录) ...
- android 布局文件中xmlns:android="http://schemas.android.com/apk/res/android"
http://blog.163.com/benben_long/blog/static/199458243201411394624170/ xmlns:android="http://sch ...
- JS操作DOM节点大全
1.Javascript删除节点 在Javascript中,只提供了一种删除节点的方法:removeChild(). removeChild() 方法用来删除父节点的一个子节点. 语法:parent. ...
- Find a multiple POJ - 2356 (抽屉原理)
抽屉原理: 形式一:设把n+1个元素划分至n个集合中(A1,A2,…,An),用a1,a2,…,an分别表示这n个集合对应包含的元素个数,则:至少存在某个集合Ai,其包含元素个数值ai大于或等于2. ...
- JavaWeb界面在线配置代码生成器
关于直接main方法运行生成代码可参考我的这篇文章:MP实战系列(六)之代码生成器讲解 在线配置主要参考jeesite和jeecg,gun等开源项目,但是与它们相比又有很多不同? 与jeesite相比 ...
- Java相关框架资料及其基础资料、进阶资料、测试资料之分享
个人说明:只为分享,不为其他,愿所有的程序员们在编程的世界自由翱翔吧! 在我看来,只有不断实战,不断学习,不断积累,不断归纳总结,形成自己的核心竞争力,方能在未来竞争中脱颖而出! 程序员谨记!重要的事 ...
- shell编程之循环
一.for循环 for循环是Shelll中最常见的循环结构,根据书写习惯又分为列表for循环.不带列表的for循环以及类C的for循环.for循环是一种运行前的测试语句,也就是在运行任何循环体之前先要 ...
- 1115 洛谷luogu最大子段和
题目描述 给出一段序列,选出其中连续且非空的一段使得这段和最大. 输入输出格式 输入格式: 第一行是一个正整数NNN,表示了序列的长度. 第二行包含NNN个绝对值不大于100001000010000的 ...
- 20175310 《Java程序设计》第5周学习总结
20175310 <Java程序设计>第5周学习总结 本周博客: <20175310 迭代和JDB - 20175310xcy - 博客园> https://www.cnblo ...
- PAT A1115 Counting Nodes in a BST (30 分)——二叉搜索树,层序遍历或者dfs
A Binary Search Tree (BST) is recursively defined as a binary tree which has the following propertie ...