Python爬虫之多线程下载程序类电子书
近段时间,笔者发现一个神奇的网站:http://www.allitebooks.com/ ,该网站提供了大量免费的编程方面的电子书,是技术爱好者们的福音。其页面如下:
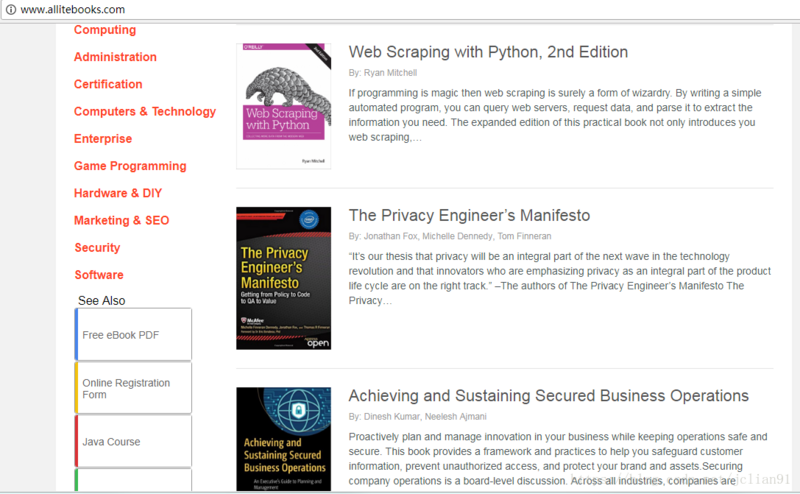
那么我们是否可以通过Python来制作爬虫来帮助我们实现自动下载这些电子书呢?答案是yes.
笔者在空闲时间写了一个爬虫,主要利用urllib.request.urlretrieve()函数和多线程来下载这些电子书。
首先呢,笔者的想法是先将这些电子书的下载链接网址储存到本地的txt文件中,便于永久使用。其Python代码(Ebooks_spider.py)如下, 该代码仅下载第一页的10本电子书作为示例:
```Python
# -*- coding:utf-8 -*-
# 本爬虫用来下载http://www.allitebooks.com/中的电子书
# 本爬虫将需要下载的书的链接写入txt文件,便于永久使用
# 网站http://www.allitebooks.com/提供编程方面的电子书
导入必要的模块
import urllib.request
from bs4 import BeautifulSoup
获取网页的源代码
def get_content(url):
html = urllib.request.urlopen(url)
content = html.read().decode('utf-8')
html.close()
return content
将762个网页的网址储存在list中
base_url = 'http://www.allitebooks.com/'
urls = [base_url]
for i in range(2, 762):
urls.append(base_url + 'page/%d/' % i)
电子书列表,每一个元素储存每本书的下载地址和书名
book_list =[]
控制urls的数量,避免书下载过多导致空间不够!!!
本例只下载前3页的电子书作为演示
读者可以通过修改url[:3]中的数字,爬取自己想要的网页书,最大值为762
for url in urls[:1]:
try:
# 获取每一页书的链接
content = get_content(url)
soup = BeautifulSoup(content, 'lxml')
book_links = soup.find_all('div', class_="entry-thumbnail hover-thumb")
book_links = [item('a')[0]['href'] for item in book_links]
print('\nGet page %d successfully!' % (urls.index(url) + 1))
except Exception:
book_links = []
print('\nGet page %d failed!' % (urls.index(url) + 1))
# 如果每一页书的链接获取成功
if len(book_links):
for book_link in book_links:
# 下载每一页中的电子书
try:
content = get_content(book_link)
soup = BeautifulSoup(content, 'lxml')
# 获取每本书的下载网址
link = soup.find('span', class_='download-links')
book_url = link('a')[0]['href']
# 如果书的下载链接获取成功
if book_url:
# 获取书名
book_name = book_url.split('/')[-1]
print('Getting book: %s' % book_name)
book_list.append(book_url)
except Exception as e:
print('Get page %d Book %d failed'
% (urls.index(url) + 1, book_links.index(book_link)))
文件夹
directory = 'E:\Ebooks\'
将书名和链接写入txt文件中,便于永久使用
with open(directory+'book.txt', 'w') as f:
for item in book_list:
f.write(str(item)+'\n')
print('写入txt文件完毕!')
可以看到,上述代码主要爬取的是静态页面,因此效率非常高!运行该程序,显示结果如下:
<center>

</center>
在book.txt文件中储存了这10本电子书的下载地址,如下:
<center>
</center>
  接着我们再读取这些下载链接,用urllib.request.urlretrieve()函数和多线程来下载这些电子书。其Python代码(download_ebook.py)如下:
-- coding:utf-8 --
本爬虫读取已写入txt文件中的电子书的链接,并用多线程下载
import time
from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED
import urllib.request
利用urllib.request.urlretrieve()下载PDF文件
def download(url):
# 书名
book_name = 'E:\Ebooks\'+url.split('/')[-1]
print('Downloading book: %s'%book_name) # 开始下载
urllib.request.urlretrieve(url, book_name)
print('Finish downloading book: %s'%book_name) #完成下载
def main():
start_time = time.time() # 开始时间
file_path = 'E:\\Ebooks\\book.txt' # txt文件路径
# 读取txt文件内容,即电子书的链接
with open(file_path, 'r') as f:
urls = f.readlines()
urls = [_.strip() for _ in urls]
# 利用Python的多线程进行电子书下载
# 多线程完成后,进入后面的操作
executor = ThreadPoolExecutor(len(urls))
future_tasks = [executor.submit(download, url) for url in urls]
wait(future_tasks, return_when=ALL_COMPLETED)
# 统计所用时间
end_time = time.time()
print('Total cost time:%s'%(end_time - start_time))
main()
运行上述代码,结果如下:
<center>

</center>
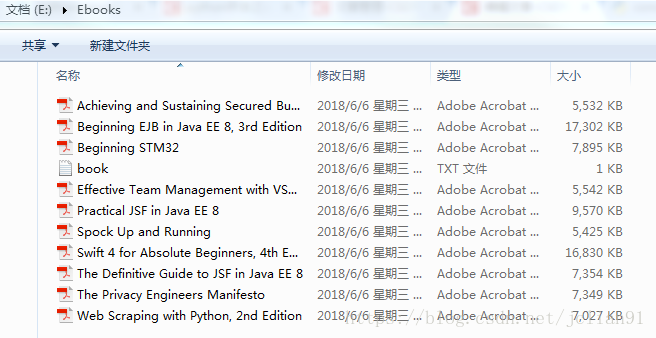
再去文件夹中查看文件:
<center>
</center>
可以看到这10本书都已成功下载,总共用时327秒,每本书的平均下载时间为32.7,约半分钟,而这些书的大小为87.7MB,可见效率相当高的!
  怎么样,看到爬虫能做这些多有意思的事情,不知此刻的你有没有心动呢?心动不如行动,至理名言~~
  本次代码已上传github, 地址为: https://github.com/percent4/Examples-of-Python-Spiders .
***注意:***本人现已开通两个微信公众号: 用Python做数学(微信号为:python_math)以及轻松学会Python爬虫(微信号为:easy_web_scrape), 欢迎大家关注哦~~Python爬虫之多线程下载程序类电子书的更多相关文章
- Python爬虫之多线程下载豆瓣Top250电影图片
爬虫项目介绍 本次爬虫项目将爬取豆瓣Top250电影的图片,其网址为:https://movie.douban.com/top250, 具体页面如下图所示: 本次爬虫项目将分别不使用多线程和使 ...
- python爬虫之多线程、多进程+代码示例
python爬虫之多线程.多进程 使用多进程.多线程编写爬虫的代码能有效的提高爬虫爬取目标网站的效率. 一.什么是进程和线程 引用廖雪峰的官方网站关于进程和线程的讲解: 进程:对于操作系统来说,一个任 ...
- Python之FTP多线程下载文件之分块多线程文件合并
Python之FTP多线程下载文件之分块多线程文件合并 欢迎大家阅读Python之FTP多线程下载系列之二:Python之FTP多线程下载文件之分块多线程文件合并,本系列的第一篇:Python之FTP ...
- Python之FTP多线程下载文件之多线程分块下载文件
Python之FTP多线程下载文件之多线程分块下载文件 Python中的ftplib模块用于对FTP的相关操作,常见的如下载,上传等.使用python从FTP下载较大的文件时,往往比较耗时,如何提高从 ...
- Python爬虫实战 批量下载高清美女图片
彼岸图网站里有大量的高清图片素材和壁纸,并且可以免费下载,读者也可以根据自己需要爬取其他类型图片,方法是类似的,本文通过python爬虫批量下载网站里的高清美女图片,熟悉python写爬虫的基本方法: ...
- 利用python爬虫关键词批量下载高清大图
前言 在上一篇写文章没高质量配图?python爬虫绕过限制一键搜索下载图虫创意图片!中,我们在未登录的情况下实现了图虫创意无水印高清小图的批量下载.虽然小图能够在一些移动端可能展示的还行,但是放到pc ...
- Python爬虫之多线程
详情点我跳转 关注公众号"轻松学编程"了解更多. 多线程 在介绍Python中的线程之前,先明确一个问题,Python中的多线程是假的多线程! 为什么这么说,我们先明确一个概念,全 ...
- Python爬虫开发与项目实战pdf电子书|网盘链接带提取码直接提取|
Python爬虫开发与项目实战从基本的爬虫原理开始讲解,通过介绍Pthyon编程语言与HTML基础知识引领读者入门,之后根据当前风起云涌的云计算.大数据热潮,重点讲述了云计算的相关内容及其在爬虫中的应 ...
- Python爬虫入门教程 11-100 行行网电子书多线程爬取
行行网电子书多线程爬取-写在前面 最近想找几本电子书看看,就翻啊翻,然后呢,找到了一个 叫做 周读的网站 ,网站特别好,简单清爽,书籍很多,而且打开都是百度网盘可以直接下载,更新速度也还可以,于是乎, ...
随机推荐
- 使用fabric2打包部署文件
一直以来都是复制粘贴或者拖动文件完成部署,实在是低效得很!学了学fabric,写个了脚本.如下: from fabric import Connection import shutil HOST = ...
- 《Miracle_House团队》第一次作业:团队亮相
Our Team:Miracle_House part 1 团队成员组成: NO.1 汝春瑞 201571030125 (组长) Style:乐观开朗,认真踏实,责任心强,还有就是爱笑.随和 ...
- 11.5 vmstat:虚拟内存统计
vmstat vmstat是Virtual Memory Statistics(虚拟内存统计)的缩写,利用vmstat命令可以对操作系统的内存信息.进程状态和CPU活动等进行监视.但是只能对系统的整体 ...
- 125 open source Big Data architecture papers for data professionals
https://www.linkedin.com/pulse/100-open-source-big-data-architecture-papers-anil-madan
- 一个自己实现的js表单验证框架。
经常要做一些表单验证的操作,每次都是用现成的框架,比如jquery,bootstrap等的验证插件,虽然也很强大,也很好用,可就是用起来需要引入许多js库,还有里面功能太多,感觉不太符合自己的需求.最 ...
- Nginx+Django搭建
本机环境介绍 虚拟机操作系统版本如下 [root@node1 ~]# cat /etc/redhat-release CentOS Linux release 7.2.1511 (Core) IP地址 ...
- Java并发编程:CountDownLatch、CyclicBarrier和 Semaphore
原文出处: 海子 在java 1.5中,提供了一些非常有用的辅助类来帮助我们进行并发编程,比如CountDownLatch,CyclicBarrier和Semaphore,今天我们就来学习一下这三个辅 ...
- Codeforces Round #514 (Div. 2) C. Sequence Transformation
题目大意:给你一个n 从1,2,3......n这个序列中 依次进行以下操作:1 .求所有数的最大公因数,放入a序列里面 2 .任意删去一个元素 一直到序列为空 根据删除元素的不同,导致序列a的字典序 ...
- Eclipse运行时发生An internal error occurred during:“**************” 的解决办法
2015-05-20 原因分析: 当前工作目录下的 .project 文件 不一致 例如1: 南京大学 Mooctest 提交考试试卷时出现的:An internal error occurred d ...
- while循环 格式化输出 密码本 编码的初识
第二天课程整理 while 循环 why : while ' 循环' 的意思 what : while 无限循环 how : 1.基本结构 while + 条件 循环的代码 初识循环 while tr ...