InnoDB存储引擎--Innodb Buffer Pool(缓存池)
InnoDB存储引擎--Innodb Buffer Pool(缓存池)
Innodb Buffer Pool的概念
InnoDB的Buffer Pool主要用于缓存用户表和索引数据的数据页面。它是一块连续的内存,通过一定的算法对这块缓存做有效的管理。官方文档建议,如果此台服务器为MySQL专用数据库服务器,一般可以指定为物理内存的80%给予InnoDB Buffer Pool缓冲区。(官方推荐)
为了提高大量读操作的效率,InnoDB Buffer Pool按照页的访问方式(Page=16KB)从数据文件中读取到buffer pool中,然后从内存条取相应大小的内存容量做映射,来保证多行的数据读取。
InnoDB Buffer Pool的缓存管理,是通过继承一个链表页(Linked list of pages)来实现的。对于不经常访问的数据会被刷出缓存区。运用的算法是LRU。
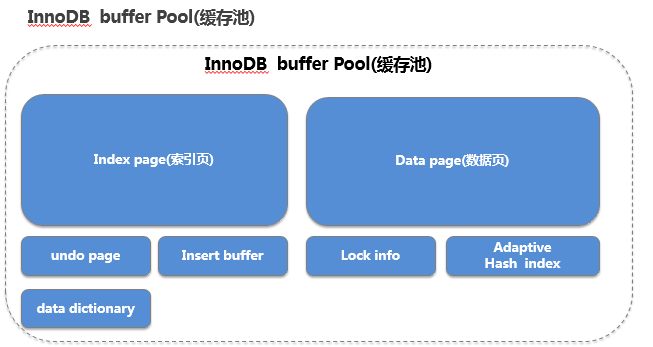
Innodb Buffer Pool的架构图
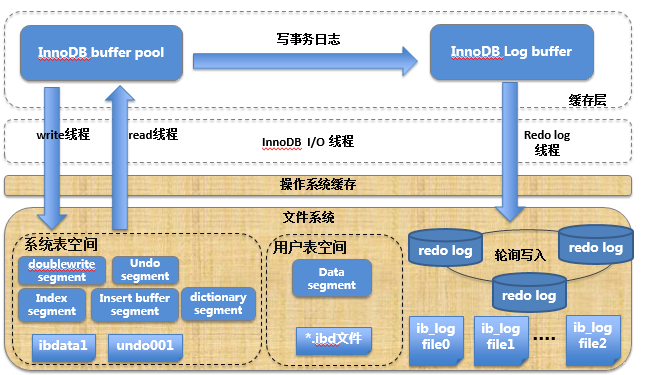
Innodb存储引擎 IO操作的架构图(补充)
Innodb Buffer Pool的内存划分
内存计算
mysql使用总内存 = global_buffers + thread_buffers
All thread buffer(会话/线程级内存分配总和) =
max_threads(当前活跃连接数) * (
read_buffer_size -- 顺序读缓冲,提高顺序读效率
+read_rnd_buffer_size -- 随机读缓冲,提高随机读效率
+sort_buffer_size -- 排序缓冲,提高排序效率
+join_buffer_size -- 表连接缓冲,提高表连接效率
+thread_stack -- 线程堆栈,暂时寄存SQL语句/存储过程
+thread_cache_size -- 线程缓存,降低多次反复打开线程开销
+binlog_cache_size -- 每个线程单独一个,用于缓存binlog日志
)
global buffer(SGA, 全局内存分配总和) =
innodb_buffer_pool_size -- InnoDB高速缓冲,行数据、索引缓冲,以及事务锁、自适应哈希等
+innodb_additional_mem_pool_size -- InnoDB数据字典额外内存,缓存所有表数据字典(在MySQL5.7.4之后,已经丢弃了)
+innodb_log_buffer_size -- InnoDB REDO日志缓冲,提高REDO日志写入效率
+key_buffer_size -- MyISAM表索引高速缓冲,提高MyISAM表索引读写效率
+query_cache_size -- 查询高速缓存,缓存查询结果,提高反复查询返回效率(在MySQL5.7.4之后,已经
+tmp_table_size
丢弃了)
实践操作
假设手头有一台8GB的服务器。
MySQL线程独享的内存就是=200×(2+2+2+2+4)= 2.3GB
其中max_threads=100
read_buffer_size=2m
read_rnd_buffer_size =2m
join_buffer_size=2m
sort_buffer_size=2m
thread_stack=128k
thread_cache_size=128k
binlog_cache_size =4m
MyISAM的key_buffer_size 给予1GB
innodb_log_buffer_size 给予32MB
系统的需要的内存给予1GB
那么,给予InnoDB buffer pool= 8-2.3-1-1 = 3.5GB左右。这个计算只是想说明内存的使用量不要一次给予太满。
适当留有空间。
我们在根据一些状态值Innodb_buffer_pool_bytes_data和Innodb_buffer_pool_pages_data,Innodb_buffer_pool_pages_total来计算buffer pool的使用状况。
mysql> show status like 'innodb_buffer_pool%';
+---------------------------------------+--------------------------------------------------+
| Variable_name | Value |
+---------------------------------------+--------------------------------------------------+
| Innodb_buffer_pool_dump_status | Dumping of buffer pool not started |
| Innodb_buffer_pool_load_status | Buffer pool(s) load completed at 180615 11:52:38 |
| Innodb_buffer_pool_resize_status | |
| Innodb_buffer_pool_pages_data | 122786 |
| Innodb_buffer_pool_bytes_data | 2011725824 |
| Innodb_buffer_pool_pages_dirty | 2598 |
| Innodb_buffer_pool_bytes_dirty | 42565632 |
| Innodb_buffer_pool_pages_flushed | 1308659 |
| Innodb_buffer_pool_pages_free | 8131 |
| Innodb_buffer_pool_pages_misc | 155 |
| Innodb_buffer_pool_pages_total | 131072 |
| Innodb_buffer_pool_read_ahead_rnd | 0 |
| Innodb_buffer_pool_read_ahead | 0 |
| Innodb_buffer_pool_read_ahead_evicted | 0 |
| Innodb_buffer_pool_read_requests | 209287578 |
| Innodb_buffer_pool_reads | 2630 |
| Innodb_buffer_pool_wait_free | 0 |
| Innodb_buffer_pool_write_requests | 62241578 |
+---------------------------------------+--------------------------------------------------+
18 rows in set (0.00 sec)
Innodb_buffer_pool_bytes_data/Innodb_buffer_pool_pages_data=16384B=16KB 可以验证官方文档给予的一个page为16KB。
Innodb_buffer_pool_pages_total =(Innodb_buffer_pool_pages_misc +Innodb_buffer_pool_pages_free+Innodb_buffer_pool_bytes_data)
验证:131072=122786+8131+155,可以看到哪些页数free状态,哪些页是有数据的,哪些页是用于管理的。
Innodb_buffer_pool_bytes_data/ Innodb_buffer_pool_pages_total =122786/131072=93.67%,可以看出有96%的页面缓存在buffer pool page中。
InnoDB log buffer size的参数对应的一些状态变量如下:
mysql> show status like 'innodb_log%';
+---------------------------+----------+
| Variable_name | Value |
+---------------------------+----------+
| Innodb_log_waits | 0 |
| Innodb_log_write_requests | 60021944 |
| Innodb_log_writes | 58181467 |
InnoDB存储引擎--Innodb Buffer Pool(缓存池)的更多相关文章
- InnoDB 存储引擎的线程与内存池
InnoDB 存储引擎的线程与内存池 InnoDB体系结构如下: 后台线程: 1.后台线程的主要作用是负责刷新内存池中的数据,保证缓冲池中的内存缓存的是最近的数据: 2.另外,将以修改的数据文件刷 ...
- 1009MySQL数据库InnoDB存储引擎Log漫游
00 – Undo Log Undo Log 是为了实现事务的原子性,在MySQL数据库InnoDB存储引擎中,还用Undo Log来实现多版本并发控制(简称:MVCC). - 事务的原子性(Atom ...
- MySQL之InnoDB存储引擎 - 读书笔记
1. MySQL 的存储引擎 MySQL 数据库的一大特色是有插件式存储引擎概念.日常使用频率最高的两种存储引擎: InnoDB 存储引擎支持事务,其特点是行锁设计.支持外键.非锁定读(默认读取操作不 ...
- MySQL技术内幕读书笔记(二)——InnoDB存储引擎
目录 InnoDB存储引擎 InnoDB存储架构 Checkpoint技术 Master Thread 工作方式 InnoDB关键特性(放一下,感觉看后面,再看总结吧) InnoDB存储引擎 Inno ...
- mysql之innodb存储引擎
mysql之innodb存储引擎 innodb和myisam区别 1>.InnoDB支持事物,而MyISAM不支持事物 2>.InnoDB支持行级锁,而MyISAM支持表级锁 3>. ...
- [转帖]mysql常用存储引擎(InnoDB、MyISAM、MEMORY、MERGE、ARCHIVE)介绍与如何选择
mysql常用存储引擎(InnoDB.MyISAM.MEMORY.MERGE.ARCHIVE)介绍与如何选择原创web洋仔 发布于2018-06-28 15:58:34 阅读数 1063 收藏展开 h ...
- InnoDB存储引擎
[InnoDB和MyISAM区别][ http://jeck2046.blog.51cto.com/184478/90499] InnoDB和MyISAM是许多人在使用MySQL时最常用的两个表类型, ...
- 浅谈MySQL存储引擎-InnoDB&MyISAM
存储引擎在MySQL的逻辑架构中位于第三层,负责MySQL中的数据的存储和提取.MySQL存储引擎有很多,不同的存储引擎保存数据和索引的方式是不同的.每一种存储引擎都有它的优势和劣势,本文只讨论最常见 ...
- 剑指架构师系列-InnoDB存储引擎、Spring事务与缓存
事务与锁是不同的.事务具有ACID属性: 原子性:持久性:由redo log重做日志来保证事务的原子性和持久性,一致性:undo log用来保证事务的一致性隔离性:一个事务在操作过程中看到了其他事务的 ...
随机推荐
- 【Mybatis】MyBatis对表执行CRUD操作(三)
本例在[Mybatis]MyBatis配置文件的使用(二)基础上继续学习对表执行CRUD操作 使用MyBatis对表执行CRUD操作 1.定义sql映射xml文件(EmployeeMapper.xml ...
- Java中equals方法简略描述
所有类都从Object中继承了equals方法,源码:public boolean equals(Object o){return this == o;} 直接判断this与o本身是否为同一对象(是否 ...
- Python开发——2.基本数据类型之数字和字符串
一.基本数据类型 基本数据类型包括:数字(int).字符串(str).列表(list).元祖(tuple).字典(dict).布尔值(bool). 查看输出数据的类型 a = "123&qu ...
- JSON笔记整理
JSON简介: JSON: JavaScript Object Notation(JavaScript 对象表示法) JSON 是存储和交换文本信息的语法.类似 XML. JSON 比 XML ...
- 解决eclipse部署maven时,src/main/resources里面配置文件加载不到webapp下classes路径下的问题
解决eclipse部署maven时,src/main/resources里面配置文件加载不到webapp下classes路径下的问题. 有时候是src/main/resources下面的,有时候是sr ...
- JDK、JRE、JVM之间的关系
JDK.JRE.JVM之间的关系 1.JDK下载地址 http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads ...
- 背水一战 Windows 10 (68) - 控件(控件基类): UIElement - Pointer 相关事件, Tap 相关事件, Key 相关事件, Focus 相关事件
[源码下载] 背水一战 Windows 10 (68) - 控件(控件基类): UIElement - Pointer 相关事件, Tap 相关事件, Key 相关事件, Focus 相关事件 作者: ...
- Objective-C优缺点
优点: 1:Category,使用category可以在不改变原来类的同时为类增加新的方法或者重写原来类的方法实现(使用runtime方法还可以在分类中实现方法交换和添加属性操作) 2:运行时 动态识 ...
- PHP 生成验证码(+图片没有显示的解决办法)
今天有需要用到验证码,就敲了个,毕竟用途比较广,所以打算把代码留下来,以后肯定用得上的.当然,今天在做的时候也是有一些问题的,分享出来吧,记录自己所犯的错误,避免以后再掉坑里. 先给个效果图(下面的真 ...
- jvm-垃圾回收gc简介+jvm内存模型简介
gc是jvm自动执行的,自动清除jvm内存垃圾,无须人为干涉,虽然方便了程序员的开发,但同时增加了开发人员对内存的不可控性. 1.jvm内存模型简介 jvm是在计算机系统上又虚拟出来的一个伪计算机系统 ...