目标检测网络之 R-FCN
R-FCN 原理
R-FCN作者指出在图片分类网络中具有平移不变性(translation invariance),而目标在图片中的位置也并不影响分类结果;但是检测网络对目标的位置比较敏感.因此Faster R-CNN将ROI的特征提取操作放在了最后分类网络中间(靠后的位置)打破分类网络的平移不变性,而不能直接放在网络的末尾.但是这样存在的问题是ROI特征提取不共享计算,导致计算量较大.
一般来讲,网络越深,其具有的平移旋转不变性越强,这个性质对于保证分类模型的鲁棒性有积极意义。然而,在检测问题中,对物体的定位任务要求模型对位置信息有良好的感知能力,过度的平移旋转不变性会削弱这一性能。研究发现,对于较深的全卷积神经网络(Inception、ResNet 等),Faster-RCNN检测框架存在着一个明显的缺陷:检测器对物体的位置信息的敏感度下降,检测准确度降低。一般来讲最直观的解决方法是将RPN的位置向浅层移动(比如在ResNet中将RPN嵌入到conv4_x的位置),但这样做会明显增加 Fast-RCNN 部分的计算量,使得检测速度明显变慢。[1]
R-FCN正是为了解决这一问题,其采用巧妙的方式将ROI的计算部分共享,减轻了头部的大小(后来出现的Light-head R-CNN更进一步).在VOC2007测试集上mAP达83.6%,比Faster R-CNN有所提升.同时速度提高2.5~20倍.
为了引入平移敏感性,作者在全卷积网络的最后层之后添加了一个1x1卷积层输出position-sensitive score map.每张score map中存放的是所有目标的某一部位的特征图.每个目标被分成\(k\times k\)个网格区域(同Faster R-CNN的ROIPooling的参数,k通常取7或14等. score map的数量设置为\(k^2(C+1)\),对应ROI的\(k\times k\)个bin的特征图.示意图如下:
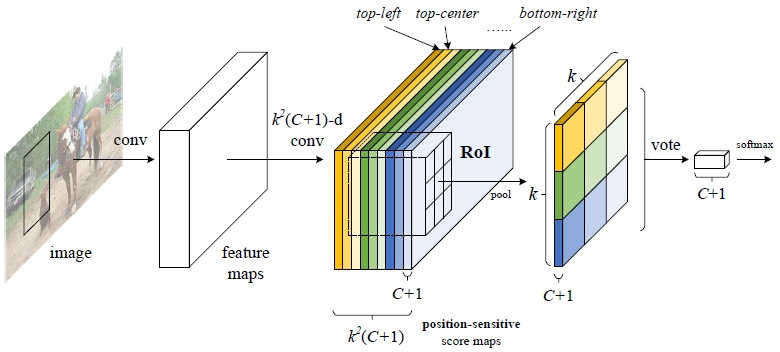
在位置敏感特征图之后接上Position-sensitive RoI pooling:
输入特征图上的第(i,j)个bin位置的值为第(i,j)个score map上该bin对应位置的均值(这里采用了average pooling 的过程,当然用 max pooling 也可以),这样得到一个通道数为C+1的\(k\times k\)大小的特征图对应C+1个类别的得分,对每个类别的得分求和(或求平均)作为每个类别的score,然后通过softmax得到最大值对应的类别作为输出.
所谓"位置敏感",其主要思想是在特征聚集时人工引入位置信息,从而有效改善较深的神经网络对物体位置信息的敏感程度。
position-sensitive regression
与Faster R-CNN类似,接上与position-sensitive score map并列的回归层(1x1卷积,输出(bg/fg)x(dx, dy, dw, dh)x(score_maps_size^2)),在经过RoI pooling后每一个RoI会得到 4 个偏移量(这里在实现时还分背景/前景,所以是8个数值)。
计算速度提升: PSROI Pooling通过对ROI共享特征图的方式, 以及通过用全局平均池化代替全连接层进行分类特征提取, 提高了计算速度.
在该网络框架下,所有可学习的层,都是卷积形式,在训练时可以很方便地进行 Online Hard Example Mining (OHEM, 在线难样本挖掘) ,几乎不会增加训练时间。[2] 相比之下OHEM Fast R-CNN方法会使训练时间加倍(A. Shrivastava, A. Gupta, and R. Girshick. Training region-based object detectors with online hard example mining. In CVPR, 2016.).
损失函数
分类的softmax损失加前景目标的回归损失.
分类
R-FCN分类分支中支持两种不同的方法: 类敏感和类无关: class-aware and agnostic, 这两者的区别: [3]
class-agnostic 方法对每个目标框输出8个数值(2类fg/bg x 4坐标), 而class-aware输出(cls+1)x4个.agnostic 方法占用内存更少,运行速度更快. mAP跟训练有关,可能会有些差别.
class-agnostic 方法通常作为预处理器,后边需要接上分类器进一步对目标框进行分类.
Atrous 技巧
作者将最后1个池化层的步长从2减小到1,那么图像将从缩小32倍变成只缩小16倍,这样就提高了共享卷积层的输出分辨率。而这样做就要使用Atrous Convolution算法,具体参见论文Semantic Image Segmentation With Deep Convolutional Nets and Fully Connnected CRFS
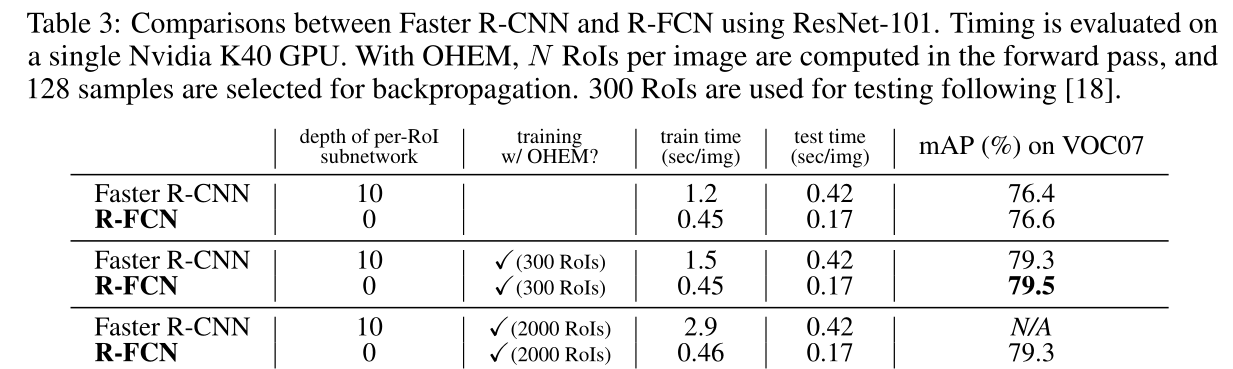
实验结果,通过下表可以看出训练时RPN产生300个ROI, 结果就已经足够好,沿用Faster R-CNN的2000的设置,反而有所下降. 另外可看出OHEM可以将结果提高3个百分点, 并且使用 OHEM 不会给训练带来额外的时间消耗.
R-FCN C++版
R-FCN C++版代码取自原作者的官方PR: Microsoft/caffe/pull/107 ,
我将其集成到了我的C++版目标检测caffe框架中: https://github.com/makefile/frcnn
RFCN OHEM 代码理解
训练时在前向传播得到所有N个proposal的loss,从大到小排序后选择前B个ROI进行反向传播,其它的则忽略.而测试时和原来一样,不做改变. 核心实现为BoxAnnotatorOHEM层, 使用方式如下:
layer {
bottom: "rois"
bottom: "per_roi_loss"
bottom: "labels"
bottom: "bbox_inside_weights"
top: "labels_ohem"
top: "bbox_loss_weights_ohem"
name: "annotator_detector"
type: "BoxAnnotatorOHEM"
box_annotator_ohem_param {
roi_per_img: 128
ignore_label: -1
}
propagate_down: false
propagate_down: false
propagate_down: false
propagate_down: false
}
注意到bottom里边有个per_roi_loss 是每个roi的loss(SmoothL1Loss+SoftmaxWithLoss), 参数roi_per_img表示最大的 top N 个 RoI 用于反向传播。 实现中使用std::sort(sorted_idx.begin(), sorted_idx.end(), [bottom_loss](int i1, int i2){return bottom_loss[i1] > bottom_loss[i2]; });对loss值排序取前roi_per_img个作为输出, 而其它roi被设置成被忽略的label(ignore_label=-1)和loss_weight=0.
另外,在设置上OHEM的一个区别是将bg_thresh_lo 设置为0, 不使用OHEM时设置为0.1(正样本周围的负样本,这也算是一种简单的难样本挖掘方式,但是设置为0.1可能导致没有样本被选中,因此也可以设置成0). 将bg_thresh_lo 设置为0使得可以从更宽泛的样本中选择难样本.
目标检测网络之 R-FCN的更多相关文章
- 目标检测网络之 Mask R-CNN
Mask R-CNN 论文Mask R-CNN(ICCV 2017, Kaiming He,Georgia Gkioxari,Piotr Dollár,Ross Girshick, arXiv:170 ...
- 目标检测网络之 YOLOv2
YOLOv1基本思想 YOLO将输入图像分成SxS个格子,若某个物体 Ground truth 的中心位置的坐标落入到某个格子,那么这个格子就负责检测出这个物体. 每个格子预测B个bounding b ...
- 目标检测网络之 YOLOv3
本文逐步介绍YOLO v1~v3的设计历程. YOLOv1基本思想 YOLO将输入图像分成SxS个格子,若某个物体 Ground truth 的中心位置的坐标落入到某个格子,那么这个格子就负责检测出这 ...
- 使用Caffe完成图像目标检测 和 caffe 全卷积网络
一.[用Python学习Caffe]2. 使用Caffe完成图像目标检测 标签: pythoncaffe深度学习目标检测ssd 2017-06-22 22:08 207人阅读 评论(0) 收藏 举报 ...
- 目标检测之R-CNN系列
Object Detection,在给定的图像中,找到目标图像的位置,并标注出来. 或者是,图像中有那些目标,目标的位置在那.这个目标,是限定在数据集中包含的目标种类,比如数据集中有两种目标:狗,猫. ...
- 目标检测(四)Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
作者:Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun SPPnet.Fast R-CNN等目标检测算法已经大幅降低了目标检测网络的运行时间. ...
- 目标检测-Faster R-CNN
[目标检测]Faster RCNN算法详解 Ren, Shaoqing, et al. “Faster R-CNN: Towards real-time object detection with r ...
- 深度学习笔记之目标检测算法系列(包括RCNN、Fast RCNN、Faster RCNN和SSD)
不多说,直接上干货! 本文一系列目标检测算法:RCNN, Fast RCNN, Faster RCNN代表当下目标检测的前沿水平,在github都给出了基于Caffe的源码. • RCNN RCN ...
- 【目标检测】SSD:
slides 讲得是相当清楚了: http://www.cs.unc.edu/~wliu/papers/ssd_eccv2016_slide.pdf 配合中文翻译来看: https://www.cnb ...
随机推荐
- SpringBoot笔记
官网: http://springboot.fun/ 收集到一个比较全的: https://blog.csdn.net/xiaoyu411502/article/details/52474037 Id ...
- awk技巧(如取某一行数据中的倒数第N列等)
使用awk取某一行数据中的倒数第N列:$(NF-(n-1))比如取/etc/passwd文件中的第2列.倒数第1.倒数第2.倒数第4列(以冒号为分隔符) [root@ipsan-node06 ~]# ...
- 总结几个常用的系统安全设置(含DenyHosts)
1)禁止系统响应任何从外部/内部来的ping请求攻击者一般首先通过ping命令检测此主机或者IP是否处于活动状态如果能够ping通 某个主机或者IP,那么攻击者就认为此系统处于活动状态,继而进行攻击或 ...
- Python-集合-17
''' 集合:可变的数据类型,他里面的元素必须是不可变的数据类型,无序,不重复. {} ''' set1 = set({1,2,3}) # set2 = {1,2,3,[2,3],{'name':'a ...
- rabbitMq与spring boot搭配实现监听
在我前面有一篇博客说到了rabbitMq实现与zk类似的watch功能,但是那一篇博客没有代码实例,后面自己补了一个demo,便于理解.demo中主要利用spring boot的配置方式, 一.消费者 ...
- Scrum Meeting NO.8
Scrum Meeting No.8 1.会议内容 2.任务清单 徐越 序号 近期的任务 进行中 已完成 1 代码重构:前端通讯模块改为HttpClient+Json √ 2 添加对cookies的支 ...
- “数学口袋精灵”App的第三个Sprint计划----开发日记(第一天12.7~第十天12.16)
“数学口袋精灵”第三个Sprint计划----第一天 项目进度: 基本完成一个小游戏,游戏具有:随机产生算式,判断对错功能.通过轻快的背景音乐,音效,给玩家提供一个良好的氛围. 任务分配: 冯美欣: ...
- Atlas & mysql-proxy
Atlas https://github.com/Qihoo360/Atlas https://github.com/Qihoo360/Atlas/wiki/Installing-Atlas Atla ...
- Failed while installing JAX-RS (REST Web Services) 1.1. org.osgi.service.prefs.BackingStoreException: Resource '/.settings' does not exist.
https://issues.jboss.org/browse/JBIDE-10039?_sscc=t https://stackoverflow.com/questions/16836832/fai ...
- No input file specified ci
1. php.ini(/etc/php5/cgi/php.ini)的配置中这两项cgi.fix_pathinfo=1 (这个是自己添加的)