MapRdeuce&Yarn的工作机制(YarnChild是什么)
MapRdeuce&Yarn的工作机制
那天在集群中跑一个MapReduce的程序时,在机器上jps了一下发现了每台机器中有好多个YarnChild。困惑什么时YarnChild,当程序跑完后就没有了,神奇。后来百度了下,又问问了别的大佬。原来是这样
什么是YarnChild:
答:MrAppmaster运行程序时向resouce manager 请求的maptask/reduceTask。也是运行程序的容器。其实它就是一个运行程序的进程。
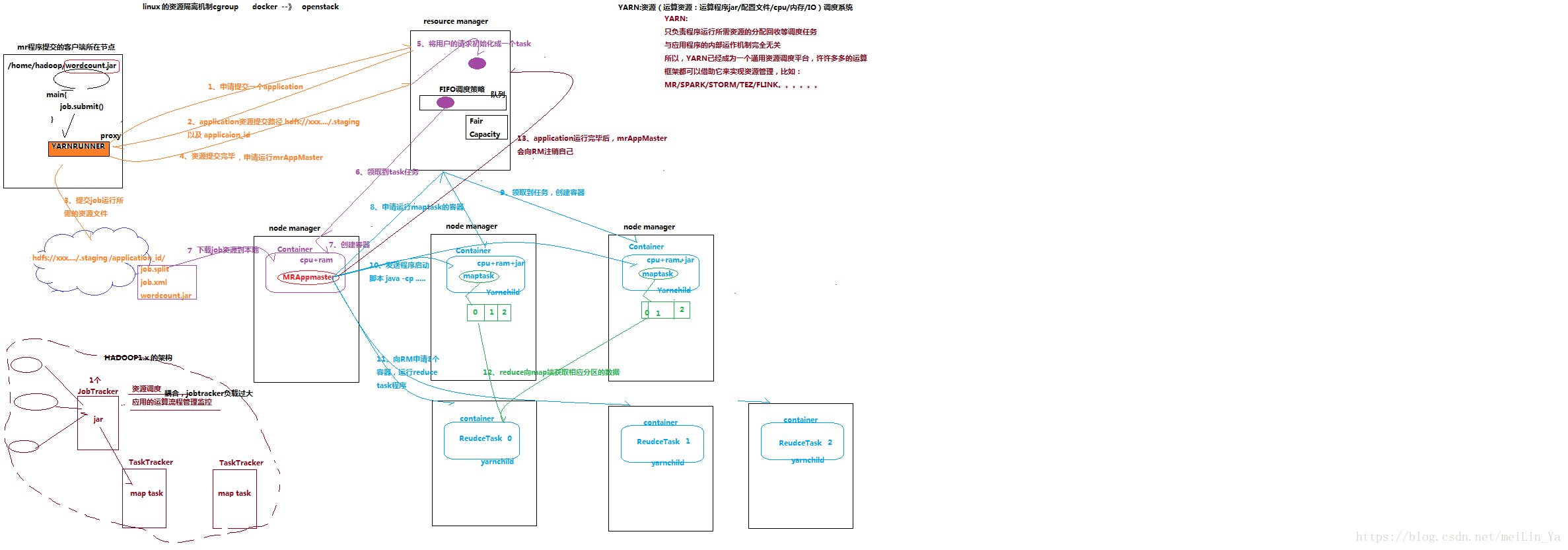
图解说下:
hadoop1版本的MapRdeuce&Yarn的工作机制
1.客户端发来request。JobTracker接受request。
2.JobTracker将客户端发来的request任务分配给TaskTracker
3.然后TaskTracker生成maptask运行程序
4.JobTracker不仅要负责资源调度,还要负责监控应运运算流程。
缺点:耦合的高,当JobTracker死掉时,所有的客户端的请求任务都会死掉,而hadoop2则避免了这个问题,它中的对象多,但都各司其职,耦合的低,运行效率快。
hadoop2版本的MapRdeuce&Yarn的工作机制
1.客户端发出请求,YARNRUNNER接受,生成一个代理对象,向resource manager请求一个application
2.resource manager返回application的提交路径和application_id(这里使用id是应为可能有多个任务用id来区别)
3.YARNRUNNER向hdfs提交job运行所需要的文件(application,job.split,job,.xml,job.jar)
4.向resource manager 报告提交完成,申请一个mrAppMaster
5.将用户的请求初始化成一个task,将task放到队列中,等待node manager来领取task任务。(这其中使用了调度策略,节约资源,如:Fair Capacity等等)
6.node manager领取到任务,
7.生成一个Container,然后在hdfs中下载运行资源。
8.向resource manager申请运行maptask的容器(带着任务,split,运行资源.的元数据..)
9.其他的node manager领取到resouce manager的任务,创建容器,此时的Container则是YarnChild,也是maptask,然后maptask在hdfs下载所要运行的资源。
10.MrAppMaster发送程序脚本运行jar,当maptask中的程序运行完成后,maptask的资源被resource manager回收了,但跑完的资源在node manager中。
11.当maptask运行完成后MRAppmaster又向resorce manager申请 reduce task(至于它申请多少个是由它有多少个map task决定的),然后根据忙于不忙node manager领取任务.创建container,
12.redcuetask 向map获取相应分区的数据资源,运行文件。
13.application运行完毕后MrAppmaster会向resource manager注销自己
总结:Yarn:资源调度系统(jar/xml/cpu/IO)
负责程序运行所需资源的分配回收等任务调度,于程序运行内部即使完全无关,所以yarn只是一个寺院调度平台,mapreudce 则是一个运行技术框架,那别的运算框架也可以使用yarn,如:spark/storm/flink....
MapRdeuce&Yarn的工作机制(YarnChild是什么)的更多相关文章
- yarn/mapreduce工作机制及mapreduce客户端代码编写
首先需要知道的就是在老版本的hadoop中是没有yarn的,mapreduce既负责资源分配又负责业务逻辑处理.为了解耦,把资源分配这块抽了出来,形成了yarn,这样不仅mapreudce可以用yar ...
- Yarn 工作机制
1.工作机制详述 (1)MR程序提交到客户端所在的节点. (2)YarnRunner向ResourceManager申请一个Application. (3)RM将该应用程序的资源路径返回给YarnRu ...
- MapReduce的工作机制
<Hadoop权威指南>中的MapReduce工作机制和Shuffle: 框架 Hadoop2.x引入了一种新的执行机制MapRedcue 2.这种新的机制建议在Yarn的系统上,目前用于 ...
- Hadoop MapReduce 一文详解MapReduce及工作机制
@ 目录 前言-MR概述 1.Hadoop MapReduce设计思想及优缺点 设计思想 优点: 缺点: 2. Hadoop MapReduce核心思想 3.MapReduce工作机制 剖析MapRe ...
- Spark工作机制简述
Spark工作机制 主要模块 调度与任务分配 I/O模块 通信控制模块 容错模块 Shuffle模块 调度层次 应用 作业 Stage Task 调度算法 FIFO FAIR(公平调度) Spark应 ...
- MapReduce工作机制——Word Count实例(一)
MapReduce工作机制--Word Count实例(一) MapReduce的思想是分布式计算,也就是分而治之,并行计算提高速度. 编程思想 首先,要将数据抽象为键值对的形式,map函数输入键值对 ...
- Hadoop的namenode的管理机制,工作机制和datanode的工作原理
HDFS前言: 1) 设计思想 分而治之:将大文件.大批量文件,分布式存放在大量服务器上,以便于采取分而治之的方式对海量数据进行运算分析: 2)在大数据系统中作用: 为各类分布式运算框架(如:mapr ...
- Hadoop记录-MRv2(Yarn)运行机制
1.MRv2结构—Yarn模式运行机制 Client---客户端提交任务 ResourceManager---资源管理 ---Scheduler调度器-资源分配Containers ----在Yarn ...
- MapReduce1 工作机制
本文转自:Hadoop MapReduce 工作机制 工作流程 作业配置 作业提交 作业初始化 作业分配 作业执行 进度和状态更新 作业完成 错误处理 作业调度 shule(mapreduce核心)和 ...
随机推荐
- 编写Shell脚本的最佳实践
编写Shell脚本的最佳实践 http://kb.cnblogs.com/page/574767/ 需要记住的 代码有注释 #!/bin/bash # Written by steven # Name ...
- [js]js代码执行顺序/全局&私有变量/作用域链/闭包
js代码执行顺序/全局&私有变量/作用域链 <script> /* 浏览器提供全局作用域(js执行环境)(栈内存) --> 1,预解释(仅带var的可以): 声明+定义 1. ...
- Python Pyinstaller打包含pandas库的py文件遇到的坑
今天的主角依然是pyinstaller打包工具,为了让pyinstaller打包后exe文件不至过大,我们的py脚本文件引用库时尽可能只引用需要的部分,不要引用整个库,多使用“from *** imp ...
- 家庭记账本之微信小程序(二)
在网上查阅了资料后,了解到了在完成微信小程序之前要完成注册阶段的工作,此次在这介绍注册阶段的流程. 1.首先你要确定小程序的定位.目的以及文案资料等(准备工作). 2.打开微信公众平台官网,点击右上角 ...
- Linq动态查询
public class ExpressionCall { List<Customer> customers = new List<Customer>() { new Cust ...
- Software Testing 1 —— 有关编程错误的经历
最令我印象深刻的程序错误几乎都是那些细节,具体的记不清了,因为真的很细.他们不会报正常的错,要么是时而可以正常运行,时而不能正常运行但是没有报错,比如闪退或者持续运行没有输出:要么是报的错误意义很宽泛 ...
- 2017.11.18 手把手教你学51单片机-点亮LED
In Doing We Learning 在操作中学习.如果只是光看教程,没有实际的操作,对编程语言的理解很空泛,所以决定从单片机中学习C语言. #include<reg52.h> ...
- 关于lazyload的实现原理
核心原理是: 1 设置一个定时器,计算每张图片是否会随着滚动条的滚动,而出现在视口(也就是浏览器中的 展现网站的空白部分 )中: 2 为<img>标签设置一个暂存图片URL的自定义属性(例 ...
- dart字符串处理
1.字符串创建(1)使用单引号,双引号创建字符串(2)使用三个引号或双引号创建多行字符串(3)使用r创建原始raw字符串(转义字符等特殊字符会输出出来,而不会自动被转义) (1)例如:String s ...
- rest_framework视图和组件
一.视图 1.基本视图 #基本视图 #抽取基类 from rest_framework.response import Response from rest_framework.views impor ...