solr6.4.1搜索引擎(2)首次同步mysql数据库





注意,不要缺失<uniqueKey>w10_id</uniqueKey>标签,否则会报错:
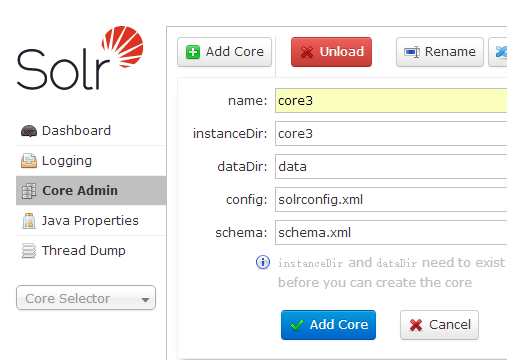


注意勾选上选项 Auto-Refresh Status,这个会自动帮你刷新数据导入状态信息,信息大概变化如下:

请求第一个entity,我这里是w10,数据10万量的表

请求第二个entity,我这里是w100, 数据100万量的表



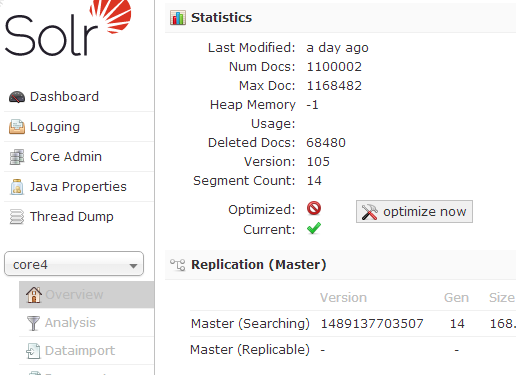
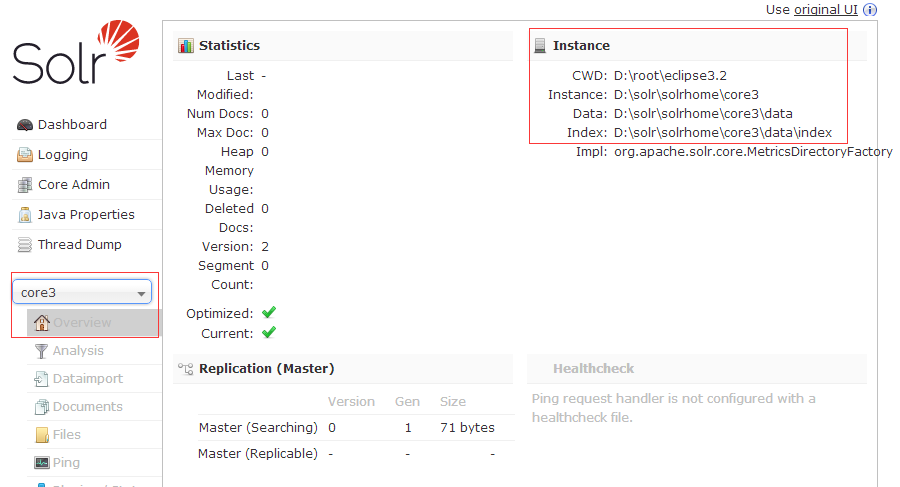
选择core4,点击overview,当在tomcat重启后,有可能出现上图中的optimize now,并且Optimized状态显示为叉叉,这是solr在告诉你这个core4的数据索引并没有按照solr的索引排序以达到最佳查询状态,只需要点击optimize now进行索引重新排序就可以了。
但是注意,这需要花费一定时间,所以会损失性能,当然,重新排序后,性能会提高。
solr6.4.1搜索引擎(2)首次同步mysql数据库的更多相关文章
- solr6.4.1搜索引擎(3)增量同步mysql数据库
尚未实现首次同步mysql数据库的,请参考我的另一篇文章http://www.cnblogs.com/zhuwenjoyce/p/6512378.html(solr6.4.1搜索引擎同步mysql数据 ...
- solr6.4.1搜索引擎同步mysql数据库
尚未成功启动solr的,请参考我的另一篇文章:http://www.cnblogs.com/zhuwenjoyce/p/6506359.html(solr6.4.1 搜索引擎启动eclipse启动) ...
- Logstash同步mysql数据库信息到ES
@font-face{ font-family:"Times New Roman"; } @font-face{ font-family:"宋体"; } @fo ...
- 使用canal增量同步mysql数据库信息到ElasticSearch
本文介绍如何使用canal增量同步mysql数据库信息到ElasticSearch.(注意:是增量!!!) 1.简介 1.1 canal介绍 Canal是一个基于MySQL二进制日志的高性能数据同步系 ...
- 使用go-mysql-elasticsearch同步mysql数据库信息到ElasticSearch
本文介绍如何使用go-mysql-elasticsearch同步mysql数据库信息到ElasticSearch. 1.go-mysql-elasticsearch简介 go-mysql-elasti ...
- 使用logstash同步mysql数据库信息到ElasticSearch
本文介绍如何使用logstash同步mysql数据库信息到ElasticSearch. 1.准备工作 1.1 安装JDK 网上文章比较多,可以参考:https://www.dalaoyang.cn/a ...
- Elasticsearch学习(2) windows环境下Elasticsearch同步mysql数据库
在上一章中,我们已经能够通过spring boot来使用Elasticsearch,但是由于我们习惯性的将数据写入mysql,所以为了解决这个问题,Elasticsearch为我们提供了一个插件log ...
- 如何通过 Docker 部署 Logstash 同步 Mysql 数据库数据到 ElasticSearch
在开发过程中,我们经常会遇到对业务数据进行模糊搜索的需求,例如电商网站对于商品的搜索,以及内容网站对于内容的关键字检索等等.对于这些高级的搜索功能,显然数据库的 Like 是不合适的,通常我们采用 E ...
- django无法同步mysql数据库 Error:1064
[问题] 具体问题:新建django工程,使用django的manage.py的 migrate命令进行更改. 在初始化数据库表时,失败,错误信息为 django.db.migrations.exce ...
随机推荐
- 『Python CoolBook』数据结构和算法_多变量赋值&“*”的两种用法
多变量赋值 a = [1,2,(3,4)] b,c,d = a print(b,c,d) b,c,(d,e) = a print(b,c,d,e) 1 2 (3, 4) 1 2 3 4 a = &qu ...
- 数据结构与算法之PHP排序算法(堆排序)
一.堆的定义 堆通常是一个可以被看做一棵树的数组对象,其任一非叶节点满足以下性质: 1)堆中某个节点的值总是不大于或不小于其父节点的值: 每个节点的值都大于或等于其左右子节点的值,称为大顶堆.即:ar ...
- Jquery获取元素方法
Jquery 获取元素的方法分为两种:jQuery选择器.jQuery遍历函数. 1.获取本身: a.只需要一种jQuery选择器 选择器 实例 说明 #Id $('#myId') ID选择器: 可以 ...
- 2015-10-05 js3
Javascript 实例2九九乘法表 var s = ""; s += "<table>"; for (var i = 1; i < 10; ...
- JavaScript(ES6)学习笔记-Set和Map数据结构(一)
一.Set 1.ES6 提供了新的数据结构 Set.它类似于数组,但是成员的值都是唯一的,没有重复的值. Set 本身是一个构造函数,用来生成 Set 数据结构. , , , , ']); s; // ...
- Python---遍历序列的各种方式
本文主要列举使用for循环遍历类似list结果的方式,因为老是使用for e in w_list真的是太没创意了,这显然不是我的风格,嘿嘿... 1. for item in s: 遍历s中的元素 2 ...
- jdbc从基础到优化
package com.xk.demotest.tools; import java.io.IOException; import java.io.InputStream; import java.s ...
- Windows查看Java内存使用情况
Windows查看Java程序运行时内存使用情况 1.在cmd命令窗口输入 jconsole ,弹出Java监视和管理控制台窗口 2.连接本地进程,首先需要知道想查看的进程ID ( pid ) 在c ...
- cocos2d-x学习笔记(斗地主代码)
满足百度百科上的出牌规则,电脑可以随着玩家出牌. 百度网盘地址:链接: https://pan.baidu.com/s/1eRLpvJ8 提取密码: tf8w
- Power BI和 Visio 集成优缺点
Power BI 的 Visio 自定义视觉,这个功能是非常值得让人兴奋的,小悦相信这是一个非常重要的开发,不仅适用于 Visio,也适用于Power BI.现在已经有越来越多的可视化,它们以更简洁的 ...