配置内存中OLTP文件组提高性能
在今天的文章里,我想谈下使用内存中OLTP的内存优化文件组来获得持久性,还有如何配置它来获得高性能。在进入正题前,我想简单介绍下使用你数据库里这个特定文件组,内存OLTP是如何获得持久性的。
内存中OLTP的持久性
早些天对内存中OLTP(代号Hekaton)的一个大误解是,人们认为内存中OLTP是不具有ACID属性的——只有ACI属性,没有D属性(Durability)。但这不是真的,因为在内存中OLTP里,每个在内存中的操作都是完全日志的。如果你的数据库崩溃,内存中OLTP可以将你的数据库和内存优化表在崩溃发生前恢复常态。内存中OLTP记录每个操作到传统SQL Server的事务日志。因为在非持久性内存里发生的一切都是基于MVCC原则,内存中OLTP只记录重做(redo)日志记录,任何时间都没有撤销(undo)日志,因为用内存中OLTP在故障恢复期间从不会有撤销操作发生。对进行中的事务进行回滚操作,只有前版本才是可以的。
当事务的提交时,重做(redo)日志才会写入。另外所谓的离线检查点工作者(Offline Checkpoint Worker)将成功提交的事务从事务填入一对所谓的数据和Delta文件(Data and Delta Files),来自内存中OLTP的数据和Delta文件会加速故障恢复。故障恢复重建你的内存优化表初始于数据和Delta文件对,然后自上个检查发生的所有改变从事务日志里应用。我们来看下这个概念。

因为在内存OLTP里一切都是和高性能有关,数据和Delta文件SQL Server只用顺序读写(sequential I/O)。不会涉及到随机读写(random I/O),因为这会杀死性能。现在的问题是,什么信息会写入数据和Delta文件对?内存中OLTP数据文件包含插入到内存优化表的记录。因为插入只发生在文件末尾,顺序读写很容易实现。当你在内存优化表删除指定记录时,记录只在对应的Delta文件逻辑上标记为删除。这个信息也是加在Delta文件末尾,这样又是真正的在存储里顺序读写。UPDATE语句只是新记录和老记录副本INSERT语句和DELETE语句的组合。很简单,是不是?下图展示了这个重要概念。
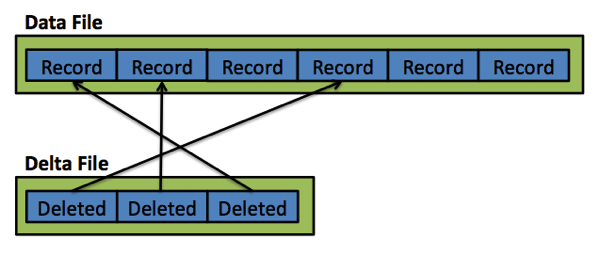
如果你想进一步了解内存中OLTP如何实现持久性的,我强烈推荐Tony Rogerson写的文章How Hekaton (XTP) achieves Durability for “Memory Optimised” Tables。
配置内存中OLTP文件组
内存优化表的故障恢复以你数据和Delta文件对存储的速度进行。因此当你创建数据库,当考虑并决定配置存储文件对的内存中OLTL文件组,仔细对待就非常重要。首先你要包含内存优化数据的存储增加文件组,如下代码所示:
-- Add a new memory optimized file group
ALTER DATABASE InMemoryOLTP
ADD FILEGROUP InMemoryOLTPFileGroup CONTAINS MEMORY_OPTIMIZED_DATA
GO
在内存优化文件组创建后(在传统FILESTREAM文件组覆盖下),你可以添加存储容器(storage container)到文件组。这里你可以使用ADD FILE命令,如下代码所示:
-- Add a new storage container
ALTER DATABASE InMemoryOLTP ADD FILE
(
NAME = N'InMemoryOLTPContainer',
FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL12.SQL2014\MSSQL\DATA\InMemoryOLTPContainer'
)
TO FILEGROUP [InMemoryOLTPFileGroup]
GO
估计你现在网上看到的所有文章里都只介绍增加1个存储容器——这会大大伤及你的性能!原因很简单:
- 数据和Delta文件对存储在同个物理硬盘
- 写数据和Delta文件对在同个物理硬盘导致随机读写(random I/O)
- 故障恢复只能和一个物理硬盘那么块,那里存储这数据和Delta文件
为了克服这些限制,你可以添加多个属于内存优化文件的存储容器在不同的“物理”硬盘上。这样的话,数据和Delta文件在多个存储容器间会以循环(round-robin)样式分配。假设配置2个存储容器会发生什么:
- 第1个数据文件存入第1个存储容器
- 第1个Delta文件存入第2个存储容器
- 第2个数据文件存入第1个存储容器
- 第2个Delta文件存入第2个存储容器
下图给你具体演示了这个概念。

但是只使用2个存储容器并不解决你的磁盘瓶颈问题,因为只有2个容器,所有的数据文件存储在第1个容器,所有的Delta文件存储在第2个容器。一般来说,你的数据文件比你的Delta文件会多很多,这就是说在不同物理硬盘上的2个存储容器之间的读写很不平衡。存储你所有数据文件的第1个存储容器比存储你所有Delta文件的第2个容器需要更多的IOPS。
为了多个物理硬盘之间IOPS平均分布与平衡。对于你的内存优化文件组,微软推荐至少4个存储容器。当你有4个存储容器时,想象下会发生什么,如下图所示:
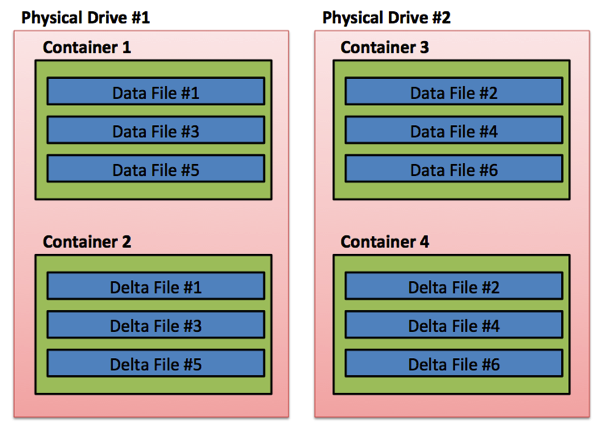
如果你使用这个配置,在第1个物理硬盘上你有第1个文件对(数据和Delta文件),在第2个物理存储上你有第2个文件对(数据和Delta文件),在第1个物理硬盘上你有第3个文件对(数据和Delta文件),以此类推。最后你在多个物理硬盘键平均散布了你的读写请求,这会加速你的故障恢复进程,因为故障恢复可以在存储容器里并行,这会加速你数据库联机。
小结
在这个文件里你看到对于内存中OLTP,存储速度和吞吐量还是非常重要的。在存储里,你的数据必须是物理永驻的,不然当你的SQL Server崩溃或重启时,你的数据就会丢失。你内存优化文件组配置会大大影响文件组给你的吞吐量。如果你在生产环境运行内存中OLTP,你应该至少配置4个存储容器分布在2个物理硬盘。在性能要求更高的场景,你甚至可以增加超过2个物理硬盘的更多存储容器。正如微软说的:“内存中OLTP的故障恢复是以你存储速度进行的”。
感谢关注!
参考文章:
配置内存中OLTP文件组提高性能的更多相关文章
- 内存中OLTP(Hekaton)的排序警告
内存中OLTP是关于内存中的一切.但那只是对了一半.在今天的文章里我想给你展示下,当你从内存读取数据时,即使内存中OLTP也会引起磁盘活动.这里的问题是执行计划里,不正确的统计信息与排序(sort)运 ...
- SQL Server 内存中OLTP内部机制概述(一)
----------------------------我是分割线------------------------------- 本文翻译自微软白皮书<SQL Server In-Memory ...
- 内存中 OLTP - 常见的工作负荷模式和迁移注意事项(三)
----------------------------我是分割线------------------------------- 本文翻译自微软白皮书<In-Memory OLTP – Comm ...
- 内存中 OLTP - 常见的工作负荷模式和迁移注意事项(二)
----------------------------我是分割线------------------------------- 本文翻译自微软白皮书<In-Memory OLTP – Comm ...
- 内存中 OLTP - 常见的工作负荷模式和迁移注意事项(一)
----------------------------我是分割线------------------------------- 本文翻译自微软白皮书<In-Memory OLTP – Comm ...
- SQL Server 内存中OLTP内部机制概述(四)
----------------------------我是分割线------------------------------- 本文翻译自微软白皮书<SQL Server In-Memory ...
- SQL Server 内存中OLTP内部机制概述(二)
----------------------------我是分割线------------------------------- 本文翻译自微软白皮书<SQL Server In-Memory ...
- 内存中OLTP与内存不足
我已经写了好几次内存中OLTP的文章和”为什么我还不推荐内存中OLTP给用户”.今天我想进一步谈下内存中OLTP背后的内存需求,还有如果你内存不够的话会发生什么. 一切都与内存有关! 我们都知道很久之 ...
- SQL Server 内存中OLTP内部机制概述(三)
----------------------------我是分割线------------------------------- 本文翻译自微软白皮书<SQL Server In-Memory ...
随机推荐
- 用CSS box-shadow画画
原理:找一幅画,每隔5 pixel取一个点的RGB,在CSS中用box-shadow描绘出这个点 Python from PIL import Image if __name__ == '__main ...
- Md5加密方法
package com.atguigu.surveypark.util; import java.security.MessageDigest; /** * 数据 */ public class Da ...
- python3 crypto winrandom import error
早就听说3的包很成熟了,自从从2.7过渡上来后还是碰到各种不适应,可以想象更早的时候问题该要多么多,特别一些必备库经典库如果没有跟进得多痛苦. [code lang="python" ...
- 可扩展验证框架 - A2DFramework验证框架使用介绍
SUMMARY 用途 DEMO演示 NuGet相关的资料 VS工具端的设置 用途 数据验证的作用很重要,目前.NET提供的内建验证机制是采用DataAnnotation方式来实现属性的验证,并且也提供 ...
- eclipse maven 创建总POM 工程
首先进入到eclipse的workspace,我这里的workspace目录是D:\workspace 1.创建总的POM D:\workspace>mvn archetype:create - ...
- BabeLua
http://cn.cocos2d-x.org/tutorial/show?id=507 command : -workdir E:\xg_svn\client\cocos2d-x-2.2.2\pro ...
- 寻找倒数第K个结点
#include<stdio.h> #include<iostream> using namespace std; /** * 找到链表中的倒数第k个节点 */ //定义结构体 ...
- Django 源码小剖: 响应数据 response 的返回
响应数据的返回 在 WSGIHandler.__call__(self, environ, start_response) 方法调用了 WSGIHandler.get_response() 方法, 由 ...
- 介绍 .NET Standard
作者:Vicey Wang 链接:https://zhuanlan.zhihu.com/p/24267356 原文:Introducing .NET Standard 作者:Immo Landwert ...
- 解决cxf+spring发布的webservice,types,portType和message以import方式导入
用cxf+spring发布了webservice,发现生成的wsdl的types,message和portType都以import的方式导入的.. 原因:命名空间问题 我想要生成的wsdl在同个文件中 ...