开源IP代理池续——整体重构
开源IP代理池
继上一篇开源项目IPProxys的使用之后,大家在github,我的公众号和博客上提出了很多建议。经过两周时间的努力,基本完成了开源IP代理池IPProxyPool的重构任务,业余时间基本上都花在上面了。(我的新书《Python爬虫开发与项目实战》出版了,大家可以看一下样章)
IPProxyPool相对于之前的版本完成了哪些提升呢?主要包括一下几个方面:
- 使用多进程+协程的方式,将爬取和验证的效率提高了50倍以上,可以在几分钟之内获取所有的有效IP
- 使用web.py作为API服务器,重构HTTP接口
- 增加Mysql,MongoDB等数据库的适配
- 支持python3
- 增加了三个代理网站
- 增加评分机制,评比稳定的ip
大家如果感兴趣,可以到github上clone IPProxyPool源码,已经503 star了。
下面说明一下使用方法:
项目依赖
Ubuntu,debian
1.安装sqlite数据库(一般系统内置): apt-get install sqlite3
2.安装requests,chardet,web.py,gevent: pip install requests chardet web.py sqlalchemy gevent
3.安装lxml: apt-get install python-lxml
注意:
- python3下的是pip3
- 有时候使用的gevent版本过低会出现自动退出情况,请使用pip install gevent --upgrade更新)
- 在python3中安装web.py,不能使用pip,直接下载py3版本的源码进行安装
Windows
1.下载sqlite,路径添加到环境变量
2.安装requests,chardet,web.py,gevent: pip install requests chardet web.py sqlalchemy gevent
3.安装lxml: pip install lxml或者下载lxml windows版
注意:
- python3下的是pip3
- 有时候使用的gevent版本过低会出现自动退出情况,请使用pip install gevent --upgrade更新)
- 在python3中安装web.py,不能使用pip,直接下载py3版本的源码进行安装
扩展说明
本项目默认数据库是sqlite,但是采用sqlalchemy的ORM模型,通过预留接口可以拓展使用MySQL,MongoDB等数据库。 配置方法:
1.MySQL配置
第一步:首先安装MySQL数据库并启动
第二步:安装MySQLdb或者pymysql(推荐)
第三步:在config.py文件中配置DB_CONFIG。如果安装的是MySQLdb模块,配置如下:
DB_CONFIG={
'DB_CONNECT_TYPE':'sqlalchemy',
'DB_CONNECT_STRING' : 'mysql+mysqldb://root:root@localhost/proxy?charset=utf8'
}
如果安装的是pymysql模块,配置如下:
DB_CONFIG={
'DB_CONNECT_TYPE':'sqlalchemy',
'DB_CONNECT_STRING' : 'mysql+pymysql://root:root@localhost/proxy?charset=utf8'
}
sqlalchemy下的DB_CONNECT_STRING参考支持数据库,理论上使用这种配置方式不只是适配MySQL,sqlalchemy支持的数据库都可以,但是仅仅测试过MySQL。
2.MongoDB配置
第一步:首先安装MongoDB数据库并启动
第二步:安装pymongo模块
第三步:在config.py文件中配置DB_CONFIG。配置类似如下:
DB_CONFIG={
'DB_CONNECT_TYPE':'pymongo',
'DB_CONNECT_STRING' : 'mongodb://localhost:27017/'
}
由于sqlalchemy并不支持MongoDB,因此额外添加了pymongo模式,DB_CONNECT_STRING参考pymongo的连接字符串。
注意:
如果大家想拓展其他数据库,可以直接继承db下ISqlHelper类,实现其中的方法,具体实现参考我的代码,然后在DataStore中导入类即可。
try:
if DB_CONFIG['DB_CONNECT_TYPE'] == 'pymongo':
from db.MongoHelper import MongoHelper as SqlHelper
else:
from db.SqlHelper import SqlHelper as SqlHelper
sqlhelper = SqlHelper()
sqlhelper.init_db()
except Exception,e:
raise Con_DB_Fail
有感兴趣的朋友,可以将Redis的实现方式添加进来。
如何使用
将项目目录clone到当前文件夹
$ git clone
切换工程目录
$ cd IPProxyPool
$ cd IPProxyPool_py2 或者 cd IPProxyPool_py3
运行脚本
python IPProxy.py
成功运行后,打印信息
IPProxyPool----->>>>>>>>beginning
http://0.0.0.0:8000/
IPProxyPool----->>>>>>>>db exists ip:0
IPProxyPool----->>>>>>>>now ip num < MINNUM,start crawling...
IPProxyPool----->>>>>>>>Success ip num :134,Fail ip num:7882
API 使用方法
第一种模式
GET /
这种模式用于查询代理ip数据,同时加入评分机制,返回数据的顺序是按照评分由高到低,速度由快到慢制定的。
参数
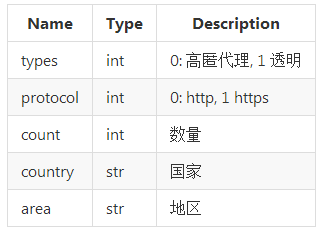
例子
IPProxys默认端口为8000,端口可以在config.py中配置。如果是在本机上测试:
1.获取5个ip地址在中国的高匿代理:http://127.0.0.1:8000/?types=0&count=5&country=中国
2.响应为JSON格式,按照评分由高到低,响应速度由高到低的顺序,返回数据:
[["122.226.189.55", 138, 10], ["183.61.236.54", 3128, 10], ["61.132.241.109", 808, 10], ["183.61.236.53", 3128, 10], ["122.227.246.102", 808, 10]]
以["122.226.189.55", 138, 10]为例,第一个元素是ip,第二个元素是port,第三个元素是分值score。
import requests
import json
r = requests.get('http://127.0.0.1:8000/?types=0&count=5&country=中国')
ip_ports = json.loads(r.text)
print ip_ports
ip = ip_ports[0][0]
port = ip_ports[0][1]
proxies={
'http':'http://%s:%s'%(ip,port),
'https':'http://%s:%s'%(ip,port)
}
r = requests.get('http://ip.chinaz.com/',proxies=proxies)
r.encoding='utf-8'
print r.text
第二种模式
GET /delete
这种模式用于方便用户根据自己的需求删除代理ip数据
参数

大家可以根据指定以上一种或几种方式删除数据。
例子
如果是在本机上测试:
1.删除ip为120.92.3.127的代理:http://127.0.0.1:8000/delete?ip=120.92.3.127
2.响应为JSON格式,返回删除的结果为成功,失败或者返回删除的个数,类似如下的效果:
["deleteNum", "ok"]或者["deleteNum", 1]
import requests
r = requests.get('http://127.0.0.1:8000/delete?ip=120.92.3.127')
print r.text
以上就是重构后的IPProxyPool,两周的辛苦没有白费,当然还有不足,之后会陆续添加智能选择代理的功能。
开源IP代理池续——整体重构的更多相关文章
- python开源IP代理池--IPProxys
今天博客开始继续更新,谢谢大家对我的关注和支持.这几天一直是在写一个ip代理池的开源项目.通过前几篇的博客,我们可以了解到突破反爬虫机制的一个重要举措就是代理ip.拥有庞大稳定的ip代理,在爬虫工作中 ...
- python爬虫18 | 就算你被封了也能继续爬,使用IP代理池伪装你的IP地址,让IP飘一会
我们上次说了伪装头部 ↓ python爬虫17 | 听说你又被封 ip 了,你要学会伪装好自己,这次说说伪装你的头部 让自己的 python 爬虫假装是浏览器 小帅b主要是想让你知道 在爬取网站的时候 ...
- python3爬虫系列19之反爬随机 User-Agent 和 ip代理池的使用
站长资讯平台:python3爬虫系列19之随机User-Agent 和ip代理池的使用我们前面几篇讲了爬虫增速多进程,进程池的用法之类的,爬虫速度加快呢,也会带来一些坏事. 1. 前言比如随着我们爬虫 ...
- 5 使用ip代理池爬取糗事百科
从09年读本科开始学计算机以来,一直在迷茫中度过,很想学些东西,做些事情,却往往陷进一些技术细节而蹉跎时光.直到最近几个月,才明白程序员的意义并不是要搞清楚所有代码细节,而是要有更宏高的方向,要有更专 ...
- python爬虫实战(三)--------搜狗微信文章(IP代理池和用户代理池设定----scrapy)
在学习scrapy爬虫框架中,肯定会涉及到IP代理池和User-Agent池的设定,规避网站的反爬. 这两天在看一个关于搜狗微信文章爬取的视频,里面有讲到ip代理池和用户代理池,在此结合自身的所了解的 ...
- Scrapy学习-13-使用DownloaderMiddleware设置IP代理池及IP变换
设置IP代理池及IP变换方案 方案一: 使用国内免费的IP代理 http://www.xicidaili.com # 创建一个tools文件夹,新建一个py文件,用于获取代理IP和PORT from ...
- 免费IP代理池定时维护,封装通用爬虫工具类每次随机更新IP代理池跟UserAgent池,并制作简易流量爬虫
前言 我们之前的爬虫都是模拟成浏览器后直接爬取,并没有动态设置IP代理以及UserAgent标识,本文记录免费IP代理池定时维护,封装通用爬虫工具类每次随机更新IP代理池跟UserAgent池,并制作 ...
- 打造IP代理池,Python爬取Boss直聘,帮你获取全国各类职业薪酬榜
爬虫面临的问题 不再是单纯的数据一把抓 多数的网站还是请求来了,一把将所有数据塞进去返回,但现在更多的网站使用数据的异步加载,爬虫不再像之前那么方便 很多人说js异步加载与数据解析,爬虫可以做到啊,恩 ...
- 记一次企业级爬虫系统升级改造(六):基于Redis实现免费的IP代理池
前言: 首先表示抱歉,春节后一直较忙,未及时更新该系列文章. 近期,由于监控的站源越来越多,就偶有站源做了反爬机制,造成我们的SupportYun系统小爬虫服务时常被封IP,不能进行数据采集. 这时候 ...
随机推荐
- Windows上x86程序正常但x64程序崩溃问题
先看下面代码: #include <stdio.h> #include <windows.h> #include <memory> class Test { pub ...
- thinkphp实现单图片上传
$config=array( 'maxSize' => 3145728, 'savePath' => './Public/Uploads/', 'rootPath' => './', ...
- 图片form表单提交和id提交
<form action="${pageContext.request.contextPath }/sarchServlet" method="post" ...
- jquery remove/add css
<input type="submit" class="btn btn-primary" id="submit" value=&quo ...
- Jsoncpp的使用
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式. 易于人阅读和编写.同时也易于机器解析和生成. 它基于JavaScript Programming Lan ...
- POJ 1228 - Grandpa's Estate 稳定凸包
稳定凸包问题 要求每条边上至少有三个点,且对凸包上点数为1,2时要特判 巨坑无比,调了很长时间= = //POJ 1228 //稳定凸包问题,等价于每条边上至少有三个点,但对m = 1(点)和m = ...
- Codeforces Round #383 _python作死系列
A. Arpa's hard exam and Mehrdad's naive cheat 题意求1378的n次方的最后一位,懒的写循环节 瞎快速幂 py3 int和LL 合并为int了 def q_ ...
- map,list
---恢复内容开始--- Map<String, List> map=new HashMap<String,List>() HashMap可以理解成是一对对数据的集合我暂时把L ...
- java根据逗号分隔字符串,后加上单引号
public class SpiltString { public String spilt(String str) { StringBuffer sb = new StringBuffer(); ...
- Boo who
function boo(bool) { // What is the new fad diet for ghost developers? The Boolean. //return bool; r ...