字符串匹配--Karp-Rabin算法
主要特征
1、使用hash函数
2、预处理阶段时间复杂度O(m),常量空间
3、查找阶段时间复杂度O(mn)
4、期望运行时间:O(n+m)
本文地址:http://www.cnblogs.com/archimedes/p/karp-rabin-algorithm.html,转载请注明源地址。
算法描述
在大多数实际情况下,Hash法提供了避免二次方比较时间的一种简单的方法. 不同于检查文本中的每一个位置是否匹配,只检查模式串和指定文本窗口的相似性似乎更高效. hash函数被用来检查两个字符串的相似度.
- 有利于字符串匹配的hash函数应该有如下的性能:
-
1. 高效可计算; -
2. 对字符串高度识别; -
3. hash(y[j+1 .. j+m]) 必须要很容易计算 hash(y[j .. j+m-1]) 和y[j+m]:
hash(y[j+1 .. j+m])= rehash(y[j], y[j+m], hash(y[j .. j+m-1]).
对于一个单词w 长度为m,hash(w) 定义如下:
hash(w[0 .. m-1])=(w[0]*2m-1+ w[1]*2m-2+···+ w[m-1]*20) mod q
其中q 是一个很大的数.
rehash(a,b,h)= ((h-a*2m-1)*2+b) mod q
Karp-Rabin 算法的预处理阶段由计算hash(x)构成. 在常量空间和O(m) 执行时间内完成.
在搜索阶段,使用hash(y[j .. j+m-1]) 0 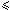 j < n-m,比较hash(x) 就足够了. 如果hash值相等,依然需要逐个字符去比较 x=y[j .. j+m-1]是否相等.
j < n-m,比较hash(x) 就足够了. 如果hash值相等,依然需要逐个字符去比较 x=y[j .. j+m-1]是否相等.
Karp-Rabin算法的搜索阶段的时间复杂度为:O(mn) (例如在an 中搜索 am).期望比较次数为: O(n+m).
举例
预处理阶段: hash[y]=17597
搜索阶段:
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| G | C | A | G | A | G | A | G | ||||||||||||||||
hash(y[0 .. 7]) = 17819
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| G | C | A | G | A | G | A | G | ||||||||||||||||
hash(y[1 .. 8]) = 17533
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| G | C | A | G | A | G | A | G | ||||||||||||||||
hash(y[2 .. 9]) = 17979
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| G | C | A | G | A | G | A | G | ||||||||||||||||
hash(y[3 .. 10]) = 19389
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| G | C | A | G | A | G | A | G | ||||||||||||||||
hash(y[4 .. 11]) = 17339
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | ||||||||||||||||
| G | C | A | G | A | G | A | G | ||||||||||||||||
hash(y[5 .. 12]) = 17597
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| G | C | A | G | A | G | A | G | ||||||||||||||||
hash(y[6 .. 13]) = 17102
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| G | C | A | G | A | G | A | G | ||||||||||||||||
hash(y[7 .. 14]) = 17117
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| G | C | A | G | A | G | A | G | ||||||||||||||||
hash(y[8 .. 15]) = 17678
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| G | C | A | G | A | G | A | G | ||||||||||||||||
hash(y[9 .. 16]) = 17245
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| G | C | A | G | A | G | A | G | ||||||||||||||||
hash(y[10 .. 17]) = 17917
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| G | C | A | G | A | G | A | G | ||||||||||||||||
hash(y[11 .. 18]) = 17723
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| G | C | A | G | A | G | A | G | ||||||||||||||||
hash(y[12 .. 19]) = 18877
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| G | C | A | G | A | G | A | G | ||||||||||||||||
hash(y[13 .. 20]) = 19662
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| G | C | A | G | A | G | A | G | ||||||||||||||||
hash(y[14 .. 21]) = 17885
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| G | C | A | G | A | G | A | G | ||||||||||||||||
hash(y[15 .. 22]) = 19197
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| G | C | A | G | A | G | A | G | ||||||||||||||||
hash(y[16 .. 23]) = 16961
上面的例子中Karp-Rabin 算法执行8个字符的比较.
C代码实现
// Completed on 2014.10.7 8:45
// Language: C99
//
// 版权所有(C)codingwu (mail: oskernel@126.com)
// 博客地址:http://www.cnblogs.com/archimedes/ #define REHASH(a, b, h) ((((h) - (a)*d) << 1) + (b)) int KR(char *x, int m, char *y, int n) {
int d, hx, hy, i, j; /* 预处理*/
/* 计算 d = 2^(m-1) 使用左移位运算操作 */
for (d = i = ; i < m; ++i)
d = (d<<); for (hy = hx = i = ; i < m; ++i) {
hx = ((hx<<) + x[i]);
hy = ((hy<<) + y[i]);
} /* 搜索*/
j = ;
while (j <= n-m) {
if (hx == hy && memcmp(x, y + j, m) == )
return j;
hy = REHASH(y[j], y[j + m], hy);
++j;
}
}
参考资料
- AHO, A.V., 1990, Algorithms for finding patterns in strings. in Handbook of Theoretical Computer Science, Volume A, Algorithms and complexity, J. van Leeuwen ed., Chapter 5, pp 255-300, Elsevier, Amsterdam.
- CORMEN, T.H., LEISERSON, C.E., RIVEST, R.L., 1990. Introduction to Algorithms, Chapter 34, pp 853-885, MIT Press.
- CROCHEMORE, M., HANCART, C., 1999, Pattern Matching in Strings, in Algorithms and Theory of Computation Handbook, M.J. Atallah ed., Chapter 11, pp 11-1--11-28, CRC Press Inc., Boca Raton, FL.
- GONNET, G.H., BAEZA-YATES, R.A., 1991. Handbook of Algorithms and Data Structures in Pascal and C, 2nd Edition, Chapter 7, pp. 251-288, Addison-Wesley Publishing Company.
- HANCART, C., 1993. Analyse exacte et en moyenne d'algorithmes de recherche d'un motif dans un texte, Ph. D. Thesis, University Paris 7, France.
- CROCHEMORE, M., LECROQ, T., 1996, Pattern matching and text compression algorithms, in CRC Computer Science and Engineering Handbook, A. Tucker ed., Chapter 8, pp 162-202, CRC Press Inc., Boca Raton, FL.
- KARP R.M., RABIN M.O., 1987, Efficient randomized pattern-matching algorithms. IBM J. Res. Dev. 31(2):249-260.
- SEDGEWICK, R., 1988, Algorithms, Chapter 19, pp. 277-292, Addison-Wesley Publishing Company.
- SEDGEWICK, R., 1988, Algorithms in C, Chapter 19, Addison-Wesley Publishing Company.
- STEPHEN, G.A., 1994, String Searching Algorithms, World Scientific.
字符串匹配--Karp-Rabin算法的更多相关文章
- 实现字符串匹配的KMP算法
KMP算法是Knuth-Morris-Pratt算法的简称,它主要用于解决在一个长字符串S中匹配一个较短字符串s. 首先我们从整体来把我这个算法的思想. 字符串匹配的朴素算法: 我们容易想到朴素算法, ...
- Luogu 3375 【模板】KMP字符串匹配(KMP算法)
Luogu 3375 [模板]KMP字符串匹配(KMP算法) Description 如题,给出两个字符串s1和s2,其中s2为s1的子串,求出s2在s1中所有出现的位置. 为了减少骗分的情况,接下来 ...
- 字符串匹配的 Boyer-Moore 算法
上一篇文章,我介绍了 字符串匹配的KMP算法 但是,它并不是效率最高的算法,实际采用并不多.各种文本编辑器的” 查找” 功能(Ctrl+F),大多采用 Boyer-Moore 算法. 下面,我根据 M ...
- 字符串匹配的 KMP算法
一般字符串匹配过程 KMP算法是字符串匹配算法的一种改进版,一般的字符串匹配算法是:从主串(目标字符串)和模式串(待匹配字符串)的第一个字符开始比较,如果相等则继续匹配下一个字符, 如果不相等则从主串 ...
- 字符串匹配的kmp算法 及 python实现
一:背景 给定一个主串(以 S 代替)和模式串(以 P 代替),要求找出 P 在 S 中出现的位置,此即串的模式匹配问题. Knuth-Morris-Pratt 算法(简称 KMP)是解决这一问题的常 ...
- HDU 1711 Number Sequence (字符串匹配,KMP算法)
HDU 1711 Number Sequence (字符串匹配,KMP算法) Description Given two sequences of numbers : a1, a2, ...... , ...
- 字符串匹配(KMP 算法 含代码)
主要是针对字符串的匹配算法进行解说 有关字符串的基本知识 传统的串匹配法 模式匹配的一种改进算法KMP算法 网上一比較易懂的解说 小样例 1计算next 2计算nextval 代码 有关字符串的基本知 ...
- 字符串匹配的KMP算法
~~~摘录 来源:阮一峰~~~ 字符串匹配是计算机的基本任务之一. 举例来说,有一个字符串”BBC ABCDAB ABCDABCDABDE”,我想知道,里面是否包含另一个字符串”ABCDABD”? 许 ...
- 字符串匹配的KMP算法详解及C#实现
字符串匹配是计算机的基本任务之一. 举例来说,有一个字符串"BBC ABCDAB ABCDABCDABDE",我想知道,里面是否包含另一个字符串"ABCDABD" ...
- 字符串匹配与KMP算法实现
>>字符串匹配问题 字符串匹配问题即在匹配串中寻找模式串是否出现, 首先想到的是使用暴力破解,也就是Brute Force(BF或蛮力搜索) 算法,将匹配串和模式串左对齐,然后从左向右一个 ...
随机推荐
- Teambition可用性测试记
引言:最开始知道Teambition是几个月前,当时是想找一个团队协作工具.Teambition是候选之一,它的界面设计给我留下了印象.后来得知其背后年轻的创始团队还是让我有些小惊讶的.这次通过朋友介 ...
- codeforces MUH and Important Things
/* 题意:给一个序列,表示每一项任务的难度,要求完成每一项任务的循序是按照难度由小到大的!输出三种符合要求的工作顺序的序列! 思路:直接看代码.... */ 1 #include<iostre ...
- springboot themleaf 开发笔记
<form id="form-query" th:action="@{/member-score/rule-save}" th:object=" ...
- 云计算之路-阿里云上:消灭“黑色n秒”第二招——给w3wp进程指定CPU核
虽然昨天的第一招失败了,但是从失败中我们学到了与多核CPU相关的Processor Affinity(处理器关联)的知识. 既然我们可以让.NET程序的不同线程运行于指定的CPU核,那是不是也可以让I ...
- 创意欣赏:20幅字体排版(Typography)素描
通常我们都只关注最终的作品,但其实幕后还有很多的过程,其中一个是素描.素描用来表达最初思想观念的原型.有时客户需要一个独特的品牌新LOGO或字体,这时先绘制在纸上是比较方便的,之后扫描到 Photos ...
- 用emacs的org2blog组件写cnblogs博客 -- 环境配置及使用
Table of Contents 配置 使用 创建一篇博文并发布 更新一篇博文 删除一篇博文 待办 本文给出了一个安装.配置org2blog的方法,实现在emacs中书写blog文章.并发布到cnb ...
- Python3.x中bytes类型和str类型深入分析
Python 3最重要的新特性之一是对字符串和二进制数据流做了明确的区分.文本总是Unicode,由str类型表示,二进制数据则由bytes类型表示.Python 3不会以任意隐式的方式混用str和b ...
- 分享一个ASP.NET 文件压缩解压类 C#
需要引用一个ICSharpCode.SharpZipLib.dll using System; using System.Collections.Generic; using System.Linq; ...
- 【jQuery基础学习】00 序
作为一个从来没有认真学过jQuery的菜来讲,我所学的都是jQuery基础. 算是让自己从0开始系统学一遍吧.学习书籍为:<锋利的jQuery>. 虽然是个序,表示一下我是个菜,但还是来几 ...
- QR二维码生成器源码(中间可插入小图片)
二维码终于火了,现在大街小巷大小商品广告上的二维码标签都随处可见,而且大都不是简单的纯二维码,而是中间有个性图标的二维码. 我之前做了一个使用google开源项目zxing实现二维码.一维码编码解码的 ...