zeppelin中运行spark streaming kakfa & 实时可视化
notebook方式运行spark程序是一种比较agile的方式,一方面可以体验像spark-shell那样repl的便捷,同时可以借助notebook的作图能力实现快速数据可视化,非常方便快速验证和demo。notebook有两种选择,一种是ipython notebook,主要针对pyspark;另一种是zeppelin,可以执行scala spark,pyspark以及其它执行引擎,包括hive等。比较而言,ipython notebook的可视化能力更强,zeppelin的功能更强。这里主要介绍基于zeppelin的方式。
spark standalone 部署
本地搭建端到端环境可以采用spark standalone部署方案。
从spark官方网站下载压缩包spark-2.2.1-bin-hadoop2.7.tgz,解压后执行
#start cluster
./sbin/start-all.sh
# check with spark shell
spark-shell --master spark://localhost:7077
# check the web UI
http://localhost:8080
kafka 演示部署
kafka在spark streaming应用场景中使用非常广泛,它有很多优秀的特性,横向扩展、持久化、有序性、API支持三种一致性语义等。
官方网站下载kafka_2.11-0.8.2.0.tar,并解压。
这里简单启动单节点:
#start zookeeper
./bin/zookeeper-server-start.sh config/zookeeper.properties
#start kafka borker
./bin/kafka-server-start.sh config/server.properties
zeppelin部署及示例
官方网站下载zeppelin-0.7.3-bin-all.tgz,解压。
为了避免端口冲突,先指定zeppelin的web端口:export ZEPPELIN_PORT=8088.
启动:
# start daemon
./bin/zeppelin-daemon.sh start
# check status
./bin/zeppelin-daemon.sh status
访问localhost:8088:

创建一个notebook并尝试运行几个快速示例:
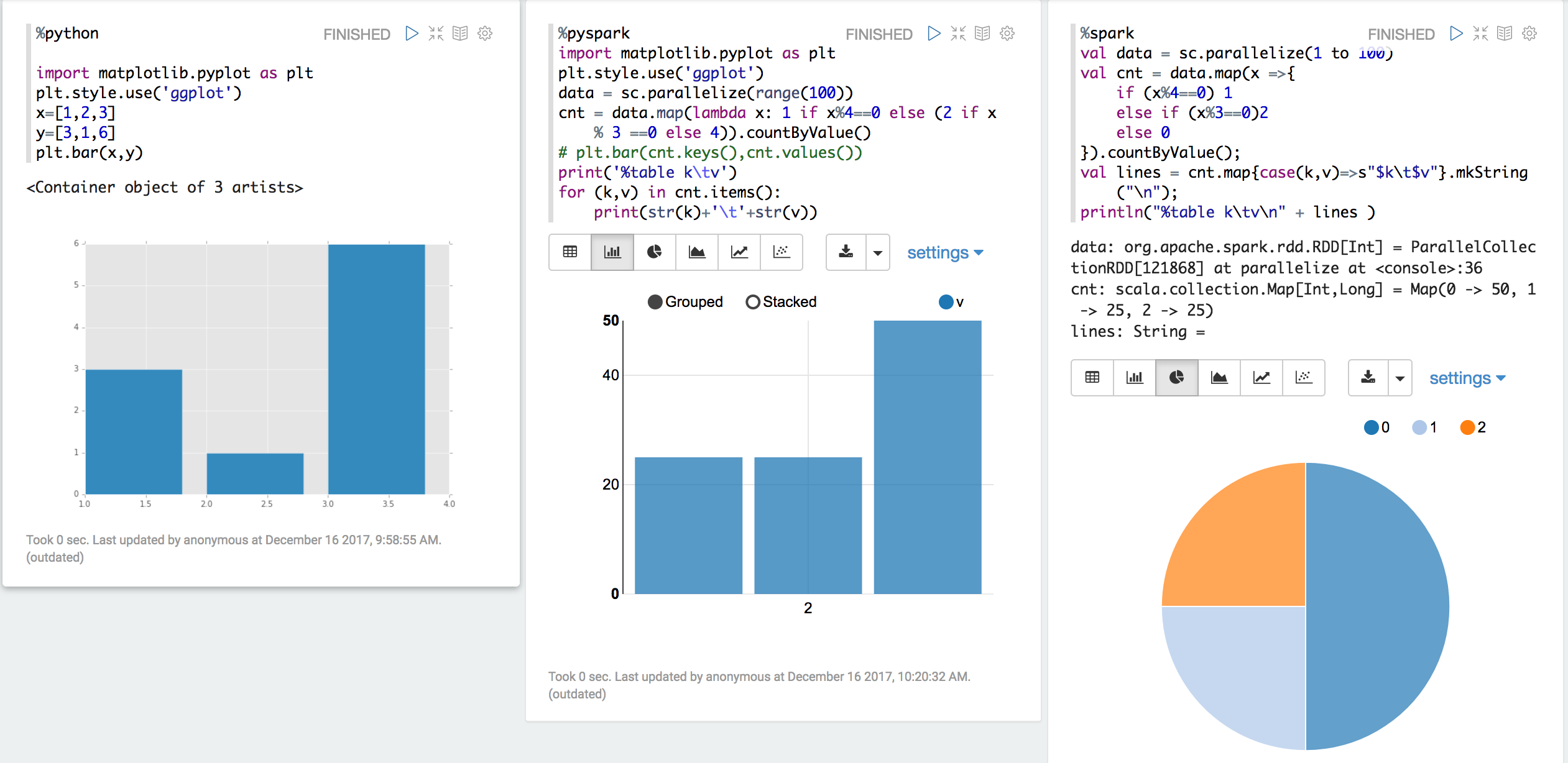
python或者pyspark数据可视化可以使用matplotlib也可以直接将数据打印出来加上table头的注解%table {column name1}\t{column name2}\t...
spark-streaming + direct kafka
kafka0.10.0的API跟之前版本变化较大,参照http://spark.apache.org/docs/latest/streaming-kafka-0-10-integration.html,总结如下:
LocationStrategy
kafka partition跟spark executor之间对应关系
-LocationStrategies.PreferConsistent partition被均匀地对应到executor;
-PreferBrokers partition被分配给本地的executor,适合kafka跟spark集群部署在相同节点上的情况;
-PreferFixed 指定partition跟executor的映射关系
ConsumerStrategies
可以subscribe到过个topic
Offset保存
0.10之前的版本中我们需要自己在代码中保存offset,以防止spark程序异常退出,在重启自后能够从failure point开始重新处理数据。新版本的kafka consumer API自身支持了offset commit,周期地commit。示例代码中没有使用自动commit,因为从kafka中成功获取数据后就commit offset存在一些问题。数据成功被读取并不能保证数据被spark成功处理完。在之前的项目中我们的方案也是自己保存offset,例如保存在zookeeper中。
官网表示spark和kafka 0.10.0的集成目前依然是experimental状态。所以我们将基于0.8版本kafka开发。http://spark.apache.org/docs/latest/streaming-kafka-0-8-integration.html
spark-streaming + kafka + zeppelin
在zeppelin中执行streaming程序并将结果创建成temporary table,进而用于实时数据可视化
准备依赖
zeppelin有类似maven的依赖解决方法,paragraph如下:
%dep
z.reset()
z.load("org.apache.spark:spark-streaming-kafka-0-8_2.11:2.2.1")
//z.load("org.apache.kafka:kafka_2.11:0.8.2.0")
z.load("org.apache.kafka:kafka-clients:0.8.2.0")
单词统计代码
读取kafka数据,分词,统计单词数量,并将统计结果创建成temporary table counts。
%spark
import _root_.kafka.serializer.DefaultDecoder
import _root_.kafka.serializer.StringDecoder
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming._
// prevent INFO logging from pollution output
sc.setLogLevel("INFO")
// creating the StreamingContext with 5 seconds interval
val ssc = new StreamingContext(sc, Seconds(5))
val kafkaConf = Map(
"metadata.broker.list" -> "localhost:9092",
"zookeeper.connect" -> "localhost:2181",
"group.id" -> "kafka-streaming-example",
"zookeeper.connection.timeout.ms" -> "1000"
)
val lines = KafkaUtils.createStream[Array[Byte], String, DefaultDecoder, StringDecoder](
ssc,
kafkaConf,
Map("test" -> 1), // subscripe to topic and partition 1
StorageLevel.MEMORY_ONLY
)
val words = lines.flatMap{ case(x, y) => y.split(" ")}
import spark.implicits._
val w=words.map(x=> (x,1L)).reduceByKey(_+_)
w.foreachRDD(rdd => rdd.toDF.registerTempTable("counts"))
ssc.start()
数据展示
从上面的temporary table counts 中查询每小批量的数据中top 10 的单词值。
%sql
select * from counts order by _2 desc limit 10

端到端演示
为了快速搭建端到端的数据流分析,我们可以在上述各个步骤的基础上再创建一个restful service,有很多方式,例如jetty + jersery,或者直接使用nifi连接到kafka。

zeppelin中运行spark streaming kakfa & 实时可视化的更多相关文章
- 使用 Kafka 和 Spark Streaming 构建实时数据处理系统
使用 Kafka 和 Spark Streaming 构建实时数据处理系统 来源:https://www.ibm.com/developerworks,这篇文章转载自微信里文章,正好解决了我项目中的技 ...
- 苏宁基于Spark Streaming的实时日志分析系统实践 Spark Streaming 在数据平台日志解析功能的应用
https://mp.weixin.qq.com/s/KPTM02-ICt72_7ZdRZIHBA 苏宁基于Spark Streaming的实时日志分析系统实践 原创: AI+落地实践 AI前线 20 ...
- 使用 Kafka 和 Spark Streaming 构建实时数据处理系统(转)
原文链接:http://www.ibm.com/developerworks/cn/opensource/os-cn-spark-practice2/index.html?ca=drs-&ut ...
- demo2 Kafka+Spark Streaming+Redis实时计算整合实践 foreachRDD输出到redis
基于Spark通用计算平台,可以很好地扩展各种计算类型的应用,尤其是Spark提供了内建的计算库支持,像Spark Streaming.Spark SQL.MLlib.GraphX,这些内建库都提供了 ...
- 基于Kafka+Spark Streaming+HBase实时点击流案例
背景 Kafka实时记录从数据采集工具Flume或业务系统实时接口收集数据,并作为消息缓冲组件为上游实时计算框架提供可靠数据支撑,Spark 1.3版本后支持两种整合Kafka机制(Receiver- ...
- 转:Sharethrough使用Spark Streaming优化实时竞价
文章来自于:http://www.infoq.com/cn/news/2014/04/spark-streaming-bidding 来自于Sharethrough的数据基础设施工程师Russell ...
- Spark 实践——基于 Spark Streaming 的实时日志分析系统
本文基于<Spark 最佳实践>第6章 Spark 流式计算. 我们知道网站用户访问流量是不间断的,基于网站的访问日志,即 Web log 分析是典型的流式实时计算应用场景.比如百度统计, ...
- 2. 运行Spark Streaming
2.1 IDEA编写程序 Pom.xml加入以下依赖: <dependency> <groupId>org.apache.spark</groupId> <a ...
- Windows下IntelliJ IDEA中运行Spark Standalone
ZHUAN http://www.cnblogs.com/one--way/archive/2016/08/29/5818989.html http://www.cnblogs.com/one--wa ...
随机推荐
- activiti5.22整合modeler时出错TypeError: Cannot read property 'split' of undefined
activiti5.22.0整合modeler时,打开的流程页面不显示工具栏和左边的控件栏,产生如下的错误: TypeError: Cannot read property 'split' of un ...
- 关于Windows 8 合约
浅谈win8合约: http://www.devdiv.com/Windows_Metro-windows_metro_app_windows_contracts_-thread-131717-1-1 ...
- 2018.11.02 NOIP模拟 飞越行星带(最小生成树/二分+并查集)
传送门 发现题目要求的就是从下到上的瓶颈路. 画个图出来发现跟去年noipnoipnoip提高组的奶酪差不多. 于是可以二分宽度+并查集检验,或者直接求瓶颈. 代码
- ThinkPHP redirect 传参
重定向带参 $this->redirect('pay/under_line_success',array('order_id'=>$stuInfo),5,'页面跳转中….'); 第一个参数 ...
- js 判断 undefined,单选 以及下拉框选中状态
name = $(this).attr("title"); if(typeof(name) == 'undefined'){ alert(1); } typeof 函数 radio ...
- boost-使用property_tree来解析xml、json
property_tree是一个保存了多个属性值的树形数据结构,可以用来解析xml.json.ini.info文件.要使用property_tree和xml解析组件的话需要包含"boost/ ...
- illustrator画梯形
1.在空白文档上先绘制出一个长方形: 2.用鼠标点击工具箱中”自由变换“工具: 3.用鼠标指向长方形四个顶点中的任意一个,当鼠标的箭头变为相反反方向的双箭头时,再按住鼠标左键不要松手, 同时按住[sh ...
- Bootstrap Table 超多列 使用滚动条
overflow-x: scroll;横向滑动详细讲解 able显示滚动条,要先把table放到一个div中,控制div 属性overflow值为scroll <div style=" ...
- BZOJ 1059 [ZJOI2007]矩阵游戏 (二分图最大匹配)
1059: [ZJOI2007]矩阵游戏 Time Limit: 10 Sec Memory Limit: 162 MBSubmit: 5281 Solved: 2530[Submit][Stat ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十一之铭文升级版
铭文一级: 第8章 Spark Streaming进阶与案例实战 黑名单过滤 访问日志 ==> DStream20180808,zs20180808,ls20180808,ww ==> ( ...