Hadoop系列之(三):使用Cloudera部署,管理Hadoop集群
1. Cloudera介绍
Hadoop是一个开源项目,Cloudera对Hadoop进行了商业化,简化了安装过程,并对hadoop做了一些封装。
根据使用的需要,Hadoop集群要安装很多的组件,一个一个安装配置起来比较麻烦,还要考虑HA,监控等。
使用Cloudera可以很简单的部署集群,安装需要的组件,并且可以监控和管理集群。
CDH是Cloudera公司的发行版,包含Hadoop,Spark,Hive,Hbase和一些工具等。
Cloudera有两个版本:
Cloudera Express 版本是免费的
Cloudera Enterprise (60天试用期)需要购买注册码
2. 安装Cloudrea Manager,部署Hadoop集群
2.1 安装方法
先安装Cloudrea Manager,再通过Cloudrea Manager在节点上安装Cloudrea Manager客户端,CDH,管理工具。
官方文档:
https://www.cloudera.com/documentation/manager/5-1-x.html
环境需求:
1. 关闭selinux
2. 各节点可以SSH登陆
3. 在/etc/hosts中添加各节点的主机名
2.2 安装Cloudrea Manager
可以通过官方的一键安装包,也可以通过yum或rpm安装。
下面介绍用官方的一键安装包安装。
本次安装环境为CnetOS 7,在3台机器上进行安装
test165 (cloudera manager server)
test166 (cloudera manager agent)
test167 (cloudera manager agent)
2.2.1 下载一键安装包
http://archive.cloudera.com/cm5/installer/latest/
下载最新版: cloudera-manager-installer.bin
2.2.2 安装cloudera manager
在test165上安装cloudera manager server,启动安装向导
# chmod a+x cloudera-manager-installer.bin
# ./cloudera-manager-installer.bin
出现下面画面
一路选择< Next > 和 < Yes >,开始安装。
需要下载JAVA和Cloudrea Manager,共600多MB,根据网络情况,会花一些时间。
出现下面页面,安装完成。
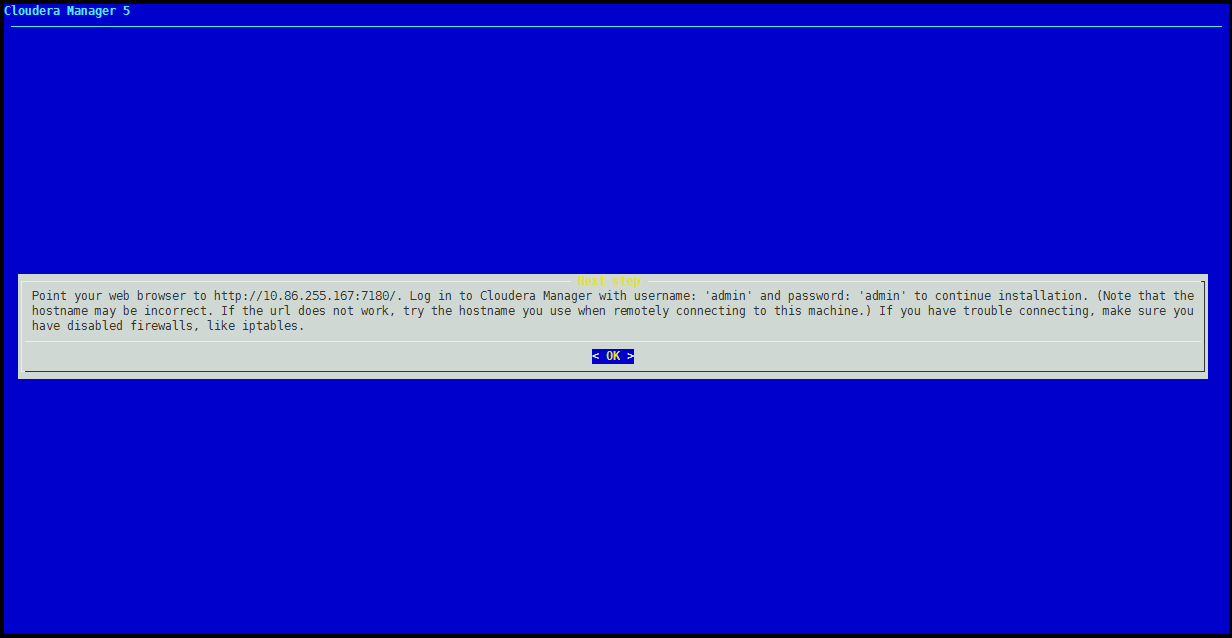
安装完成后,访问Cloudrea Manager的页面,用户名密码都是admin
http://IP或主机名:7180/

2.2.3 安装cloudera manager agent
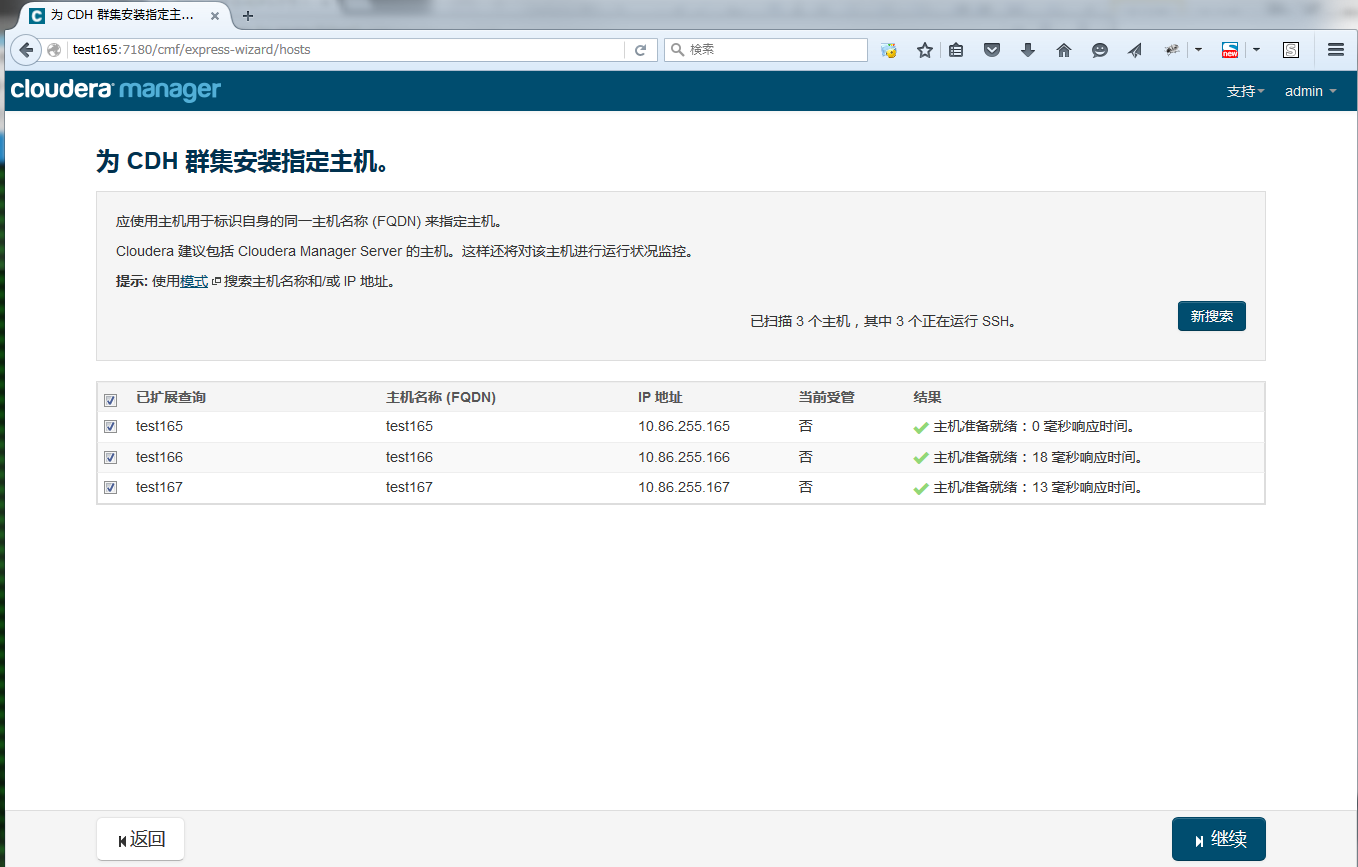
登录Cloudrea Manager页面,选择要安装的版本,本次安装的是Cloudera Express
选择要安装CDH的主机,用主机名或IP搜索,本次是在三个节点上安装CDH
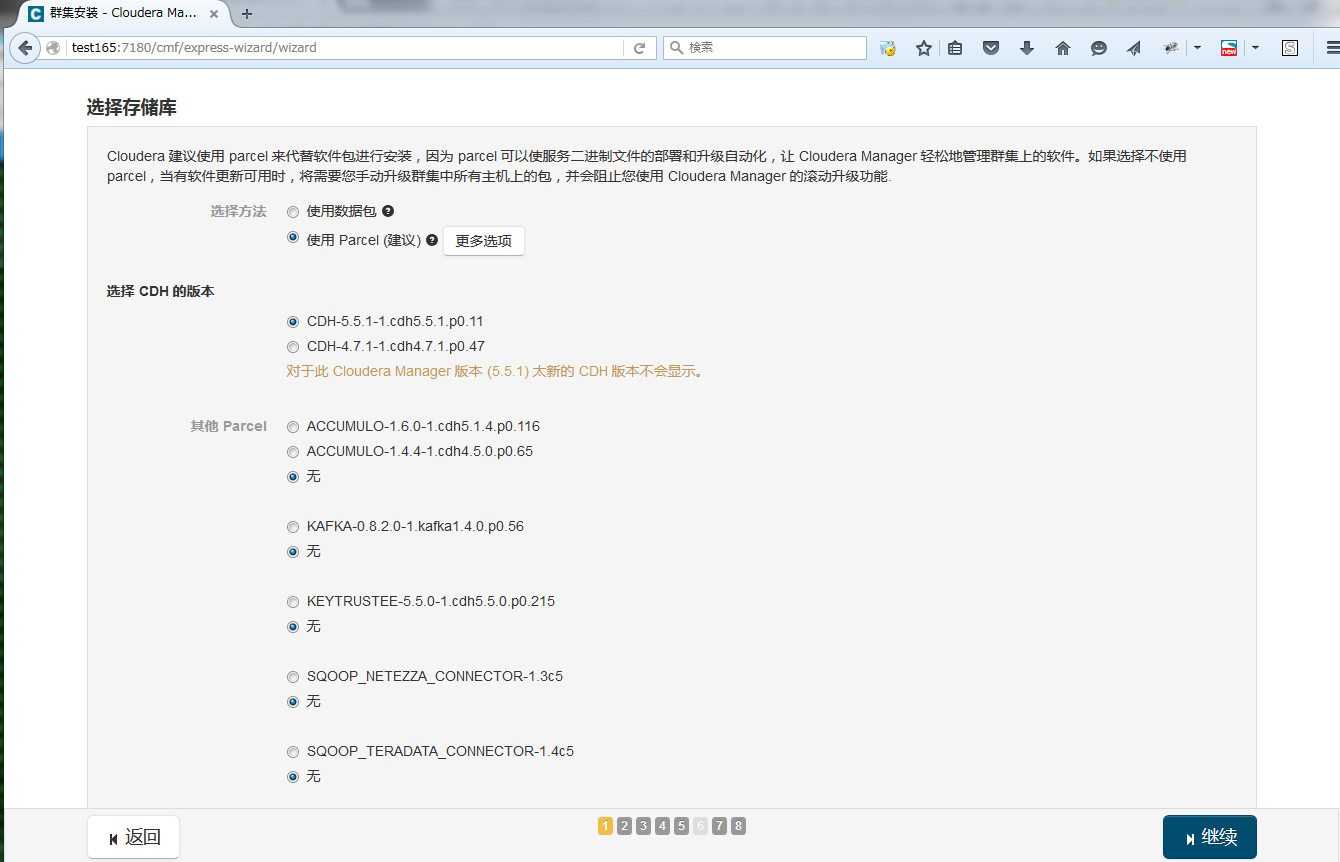
选择使用Parcel安装,选择CDH版本
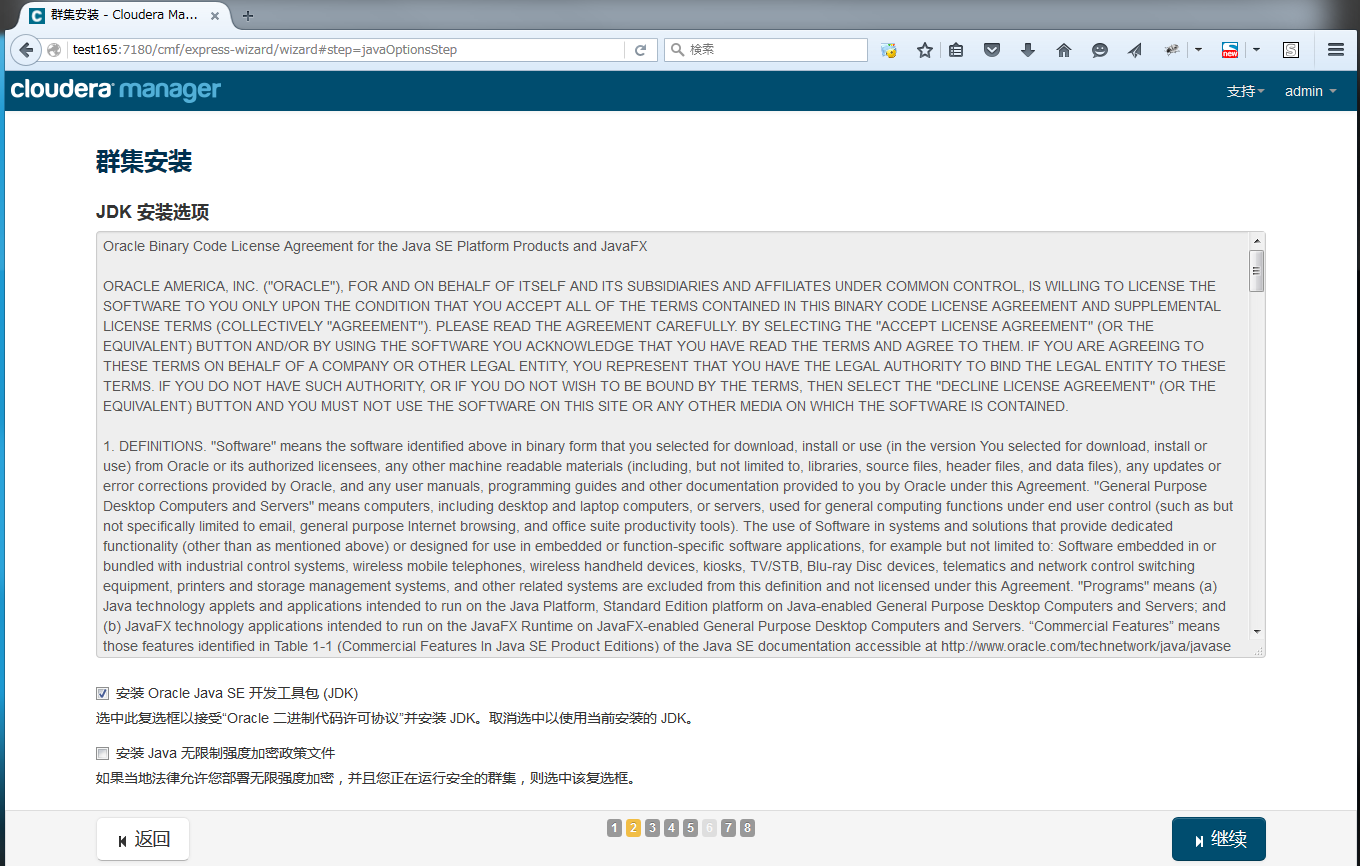
选择安装JDK
提供SSH登录信息

开始安装JDK和cloudera manager agent

如果安装过程中,下载安装jdk 或 cloudera-manager-agent失败,可以在节点上手动安装,然后再在Cloudrea Manager上继续安装
# yum -y install jdk
# yum -y install oracle-j2sdk1.7
# yum -y install cloudera-manager-agent
下载Parcel并分配Parcel到各节点
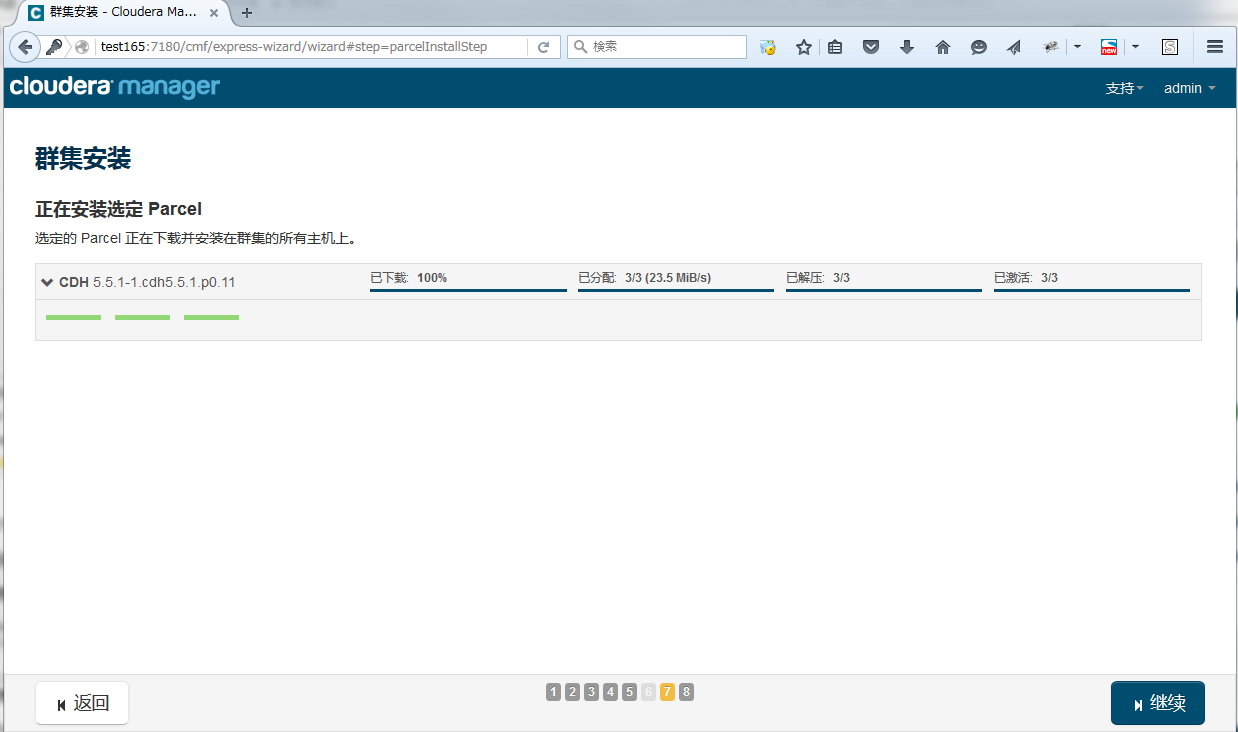
Parcel包1.5G左右,需要一段时间,为了提高安装速度,可以先把包下载到Cloudrea Manager本地,配置本地源
parcel下载地址:
http://archive.cloudera.com/cdh5/parcels/5.5.1/
将下面文件拷贝到/opt/cloudera/parcel-repo/文件夹下
CDH-5.5.1-1.cdh5.5.1.p0.11-el7.parcel
CDH-5.5.1-1.cdh5.5.1.p0.11-el7.parcel.sha
manifest.json
安装完成后,点继续,到检查结果的页面
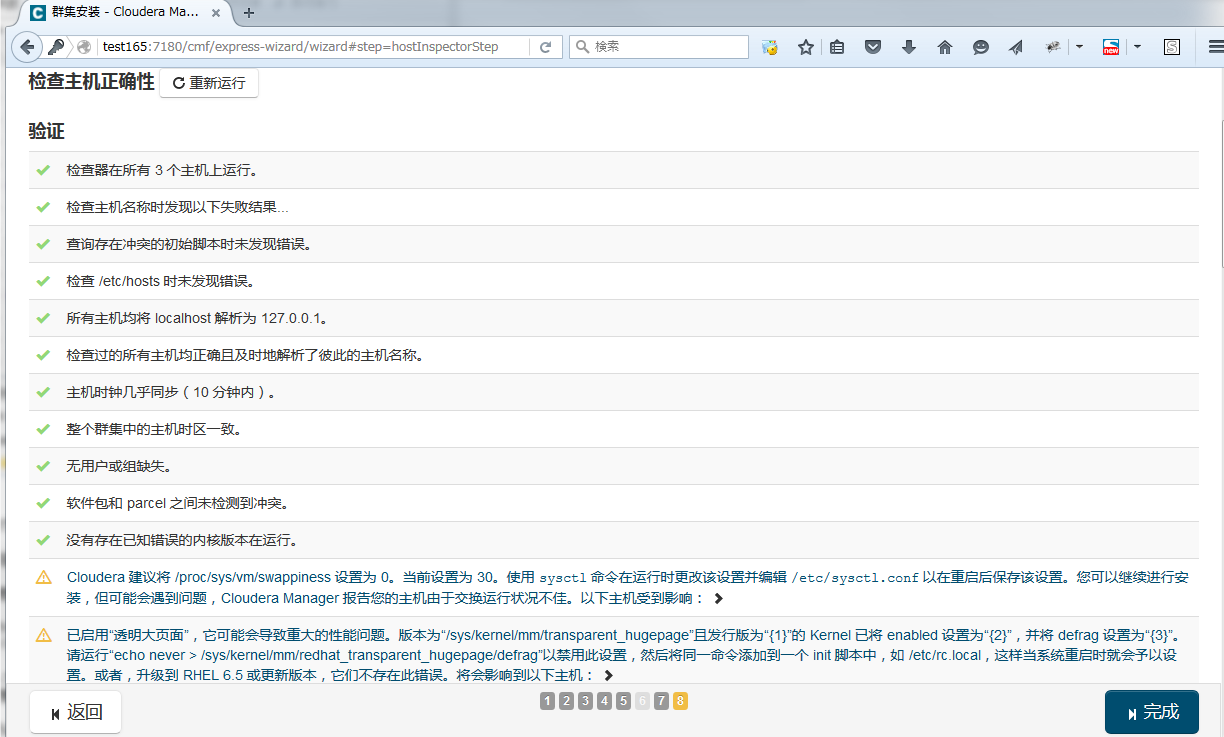
检查主机正确性时出现 “Cloudera 建议将 /proc/sys/vm/swappiness 设置为 0。当前设置为 30。” 的警告,进行如下设定
# vi /etc/sysctl.conf
vm.swappiness = 0
# sysctl –p
检查主机正确性时出现 “已启用“透明大页面”,它可能会导致重大的性能问题。” 的警告,进行如下设定
echo never > /sys/kernel/mm/transparent_hugepage/enabled
echo never > /sys/kernel/mm/transparent_hugepage/defrag # vi /etc/rc.local
echo never > /sys/kernel/mm/transparent_hugepage/enabled
echo never > /sys/kernel/mm/transparent_hugepage/defrag
2.3 安装集群,包括Hadoop,YARN,Hive等
检查主机正确性后,点击完成,进入集群配置
选择要安装的服务,可以选择组合或自定义
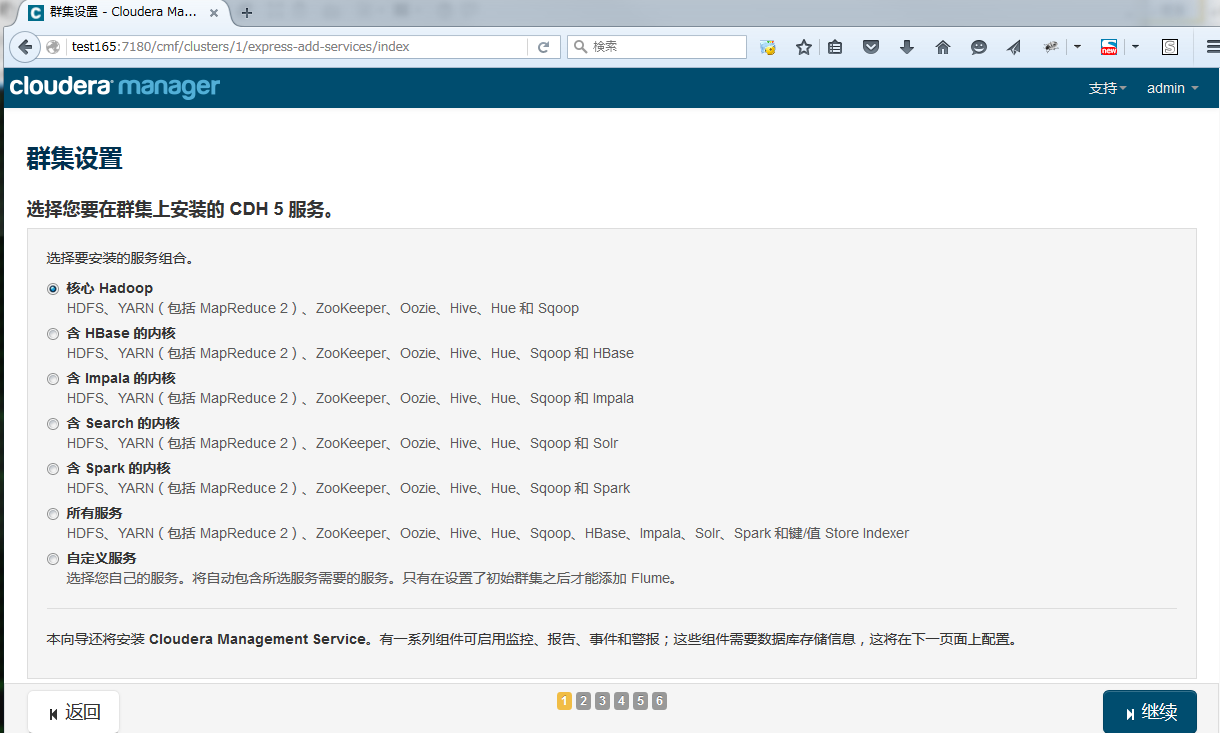
配置各节点间如何分配
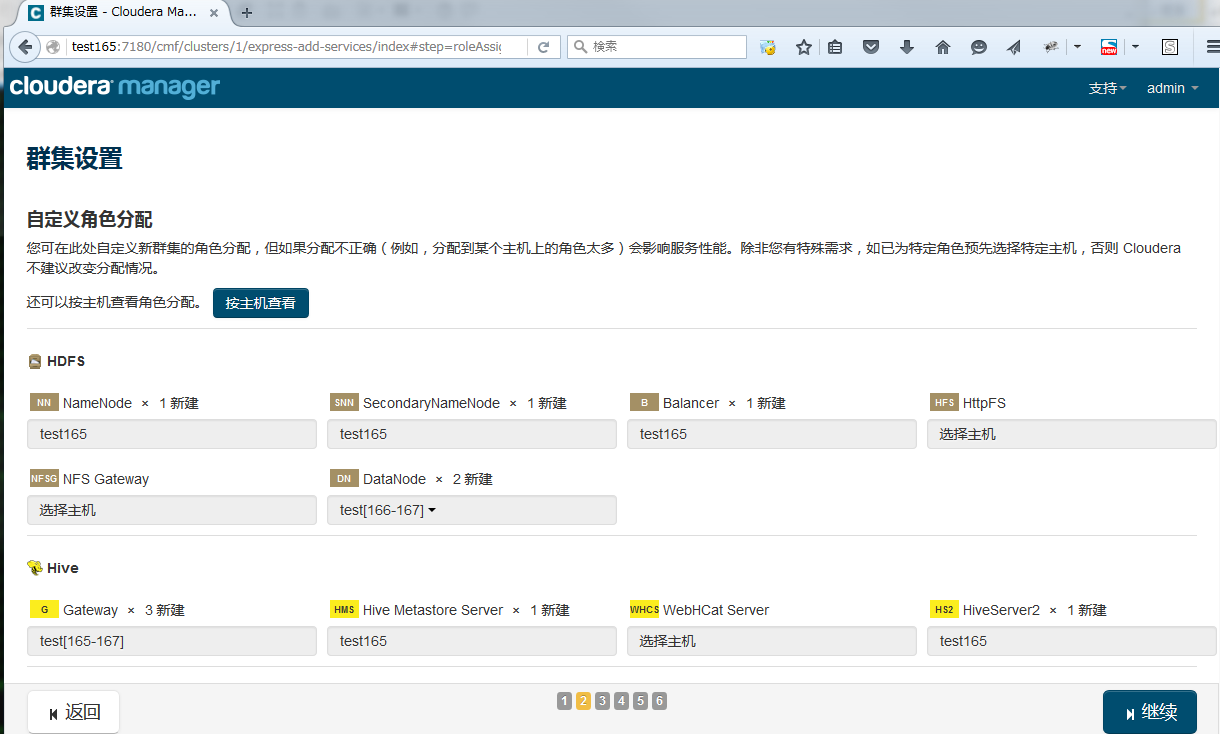
注意: HDFS的Data Node 最少3个。
测试数据库连接

开始安装
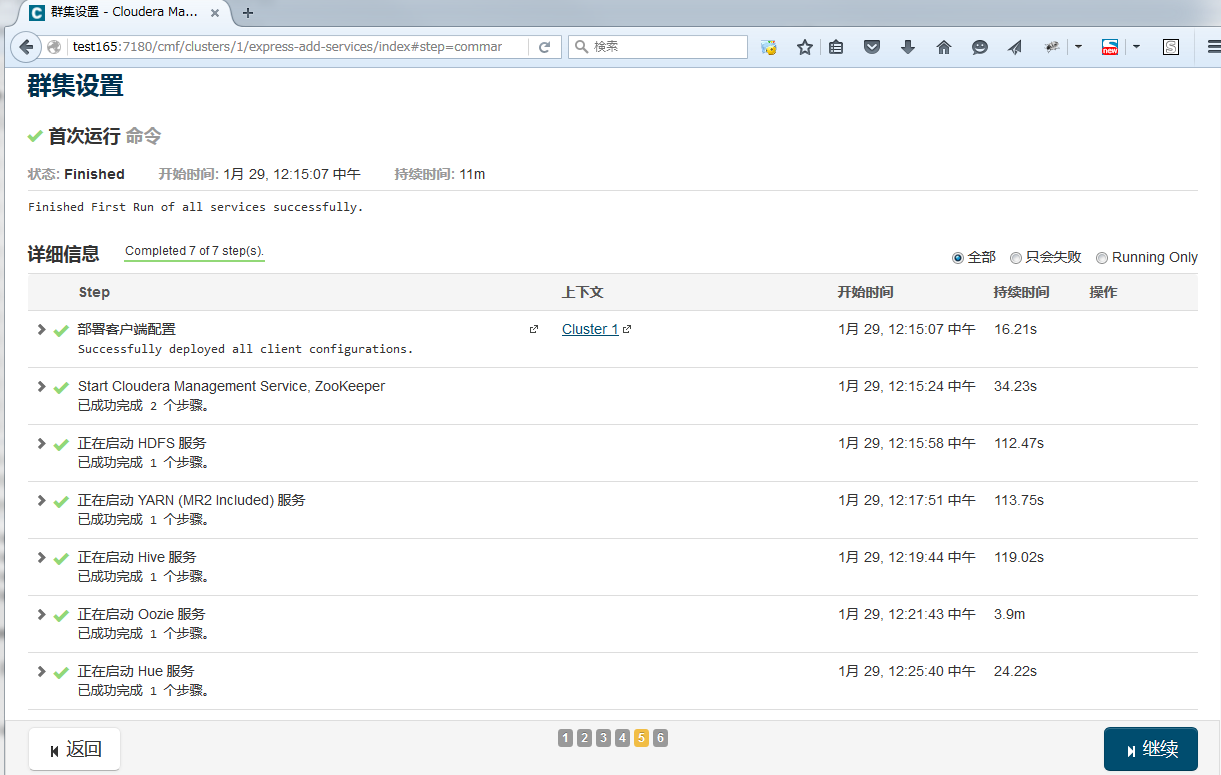
3. 确认,测试
确认集群状态正常,动作正常
1. 在集群页面确认,所有服务状态正常
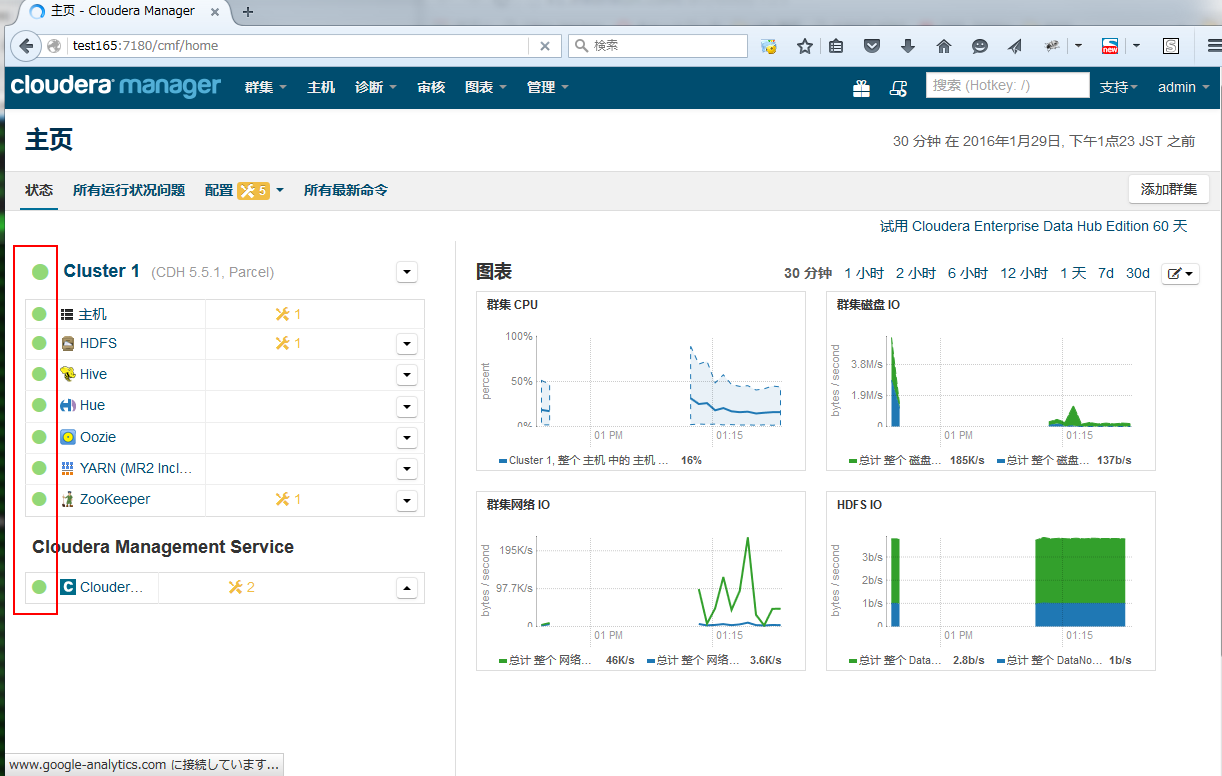
2. 在主机页面确认,各节点的Heartbeat状态正常,并且时间小于15秒
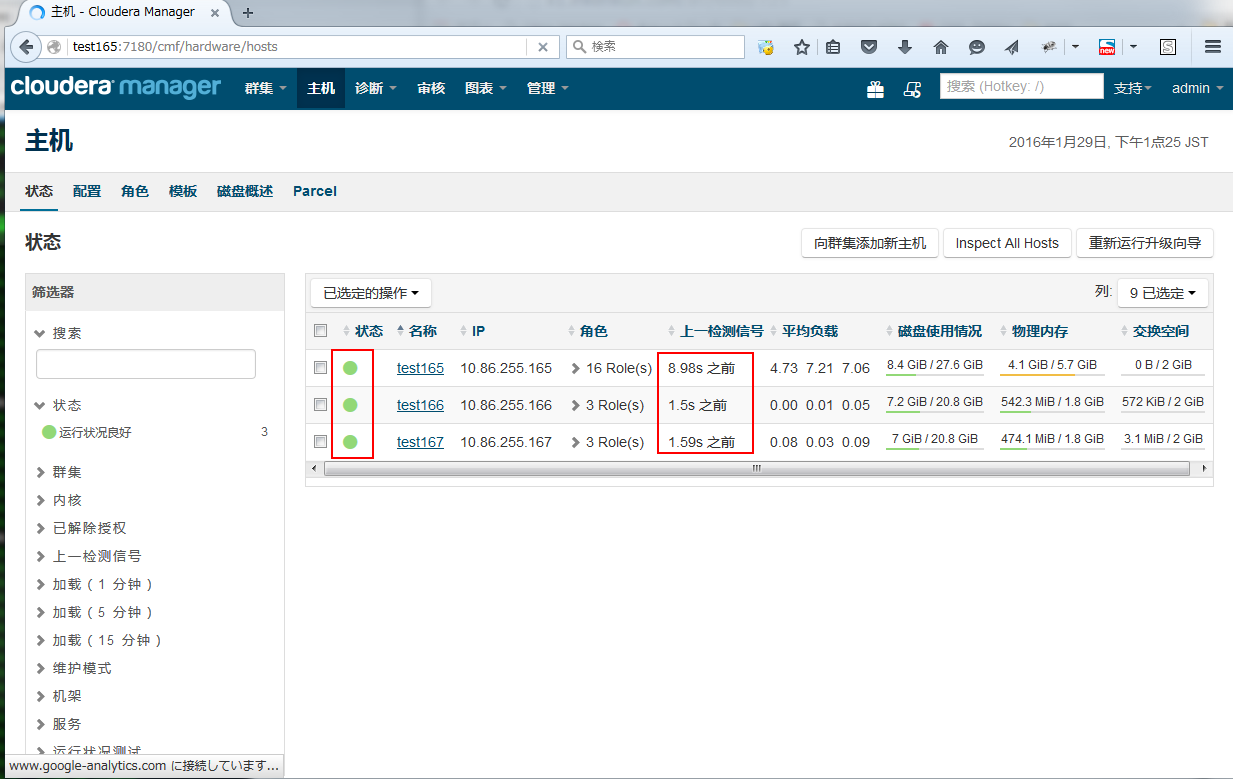
3. 运行任务进行测试
登陆到集群中任意一台主机,执行下面任务(用Hadoop计算PI值,圆周率)
后面2个数字参数的含义: 10指的是要运行10次map任务,10000指的是每个map任务,要投掷多少次,2个参数的乘积就是总的投掷次数。
# sudo -u hdfs hadoop jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar pi 10 10000
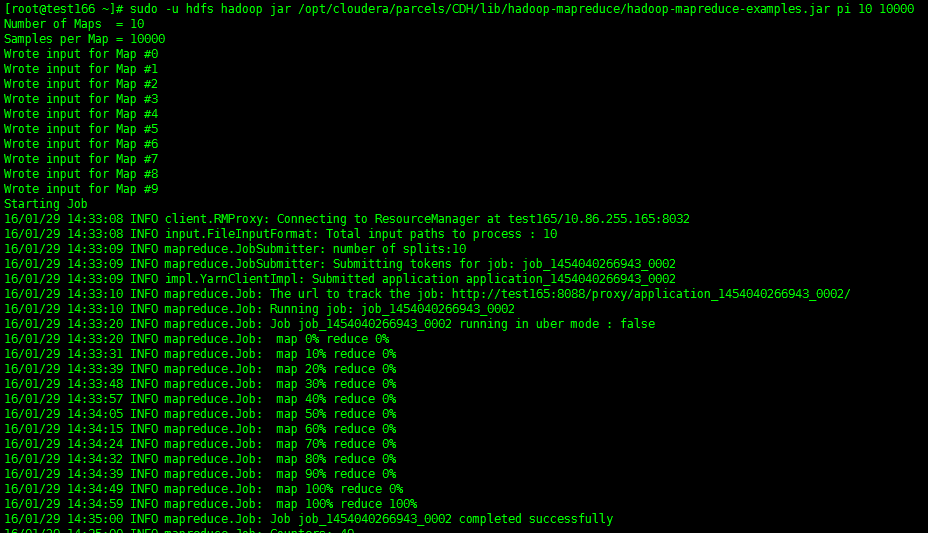
执行结果如下:

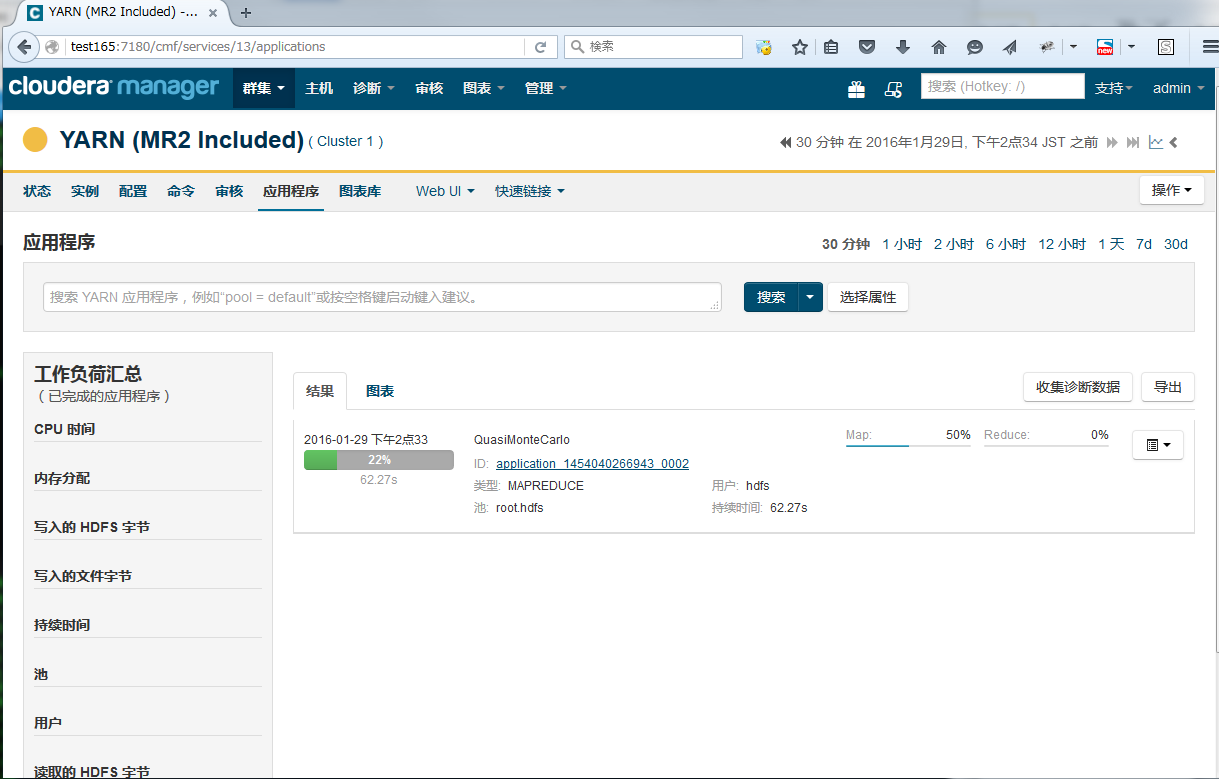
任务的执行情况可以在YARN页面上进行确认
群集 -> Cluster 1 -> YARN -> 应用程序
4. 其他
在Cloudrea Manager页面上,可以向集群中添加/删除主机,添加服务到集群等。
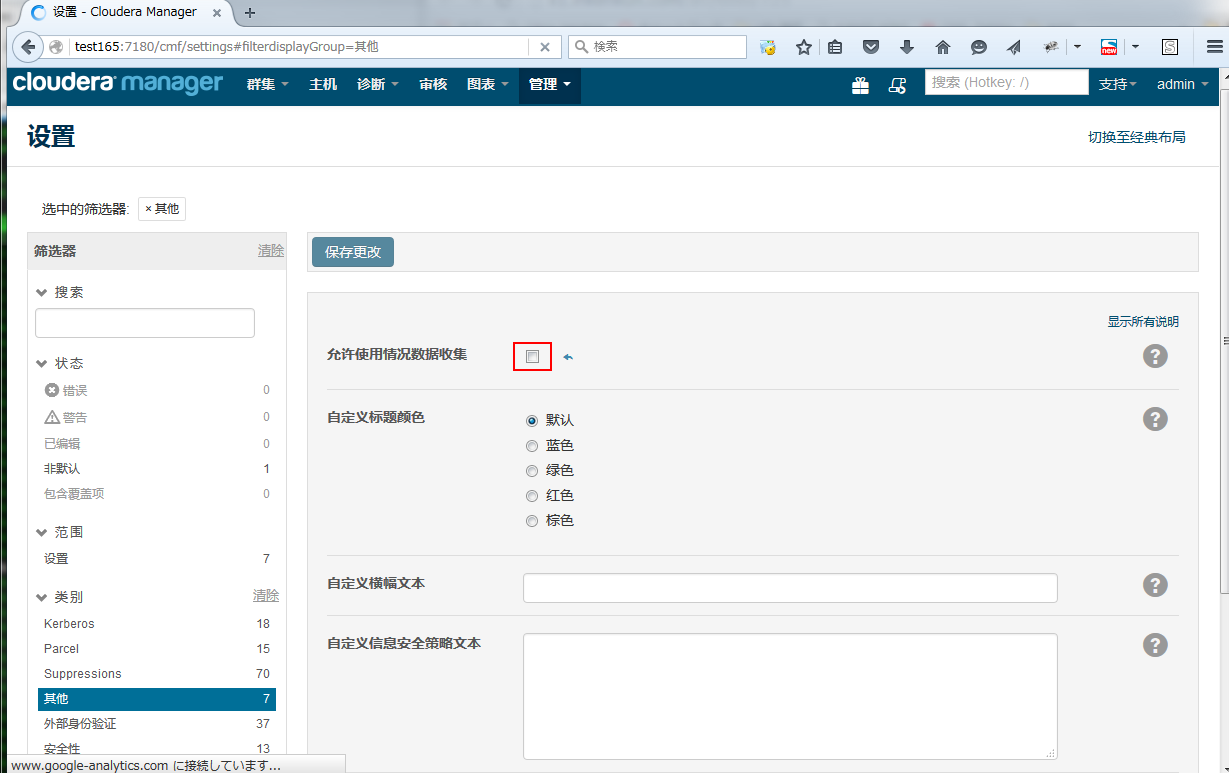
Cloudrea Manager页面开启了google-analytics,因为从国内访问很慢,可以关闭google-analytics
管理 -> 设置 -> 其他 -> 允许使用情况数据收集 不选
5. 后记
工欲善其事必先利其器,管理Hadoop 集群,Cloudrea 是个不错的选择。
Hadoop系列之(三):使用Cloudera部署,管理Hadoop集群的更多相关文章
- 三、Linux部署MinIO分布式集群
MinIO的官方网站非常详细,以下只是本人学习过程的整理 一.MinIO的基本概念 二.Windows安装与简单使用MinIO 三.Linux部署MinIO分布式集群 四.C#简单操作MinIO 一. ...
- Hadoop 系列(三)Java API
Hadoop 系列(三)Java API <dependency> <groupId>org.apache.hadoop</groupId> <artifac ...
- K8S部署Redis Cluster集群(三主三从模式) - 部署笔记
一.Redis 介绍 Redis代表REmote DIctionary Server是一种开源的内存中数据存储,通常用作数据库,缓存或消息代理.它可以存储和操作高级数据类型,例如列表,地图,集合和排序 ...
- Docker系列之(二):使用Mesos管理Docker集群(Mesos + Marathon + Chronos + Docker)
1. Mesos简介 1.1 Mesos Apache Mesos 是一个分布式系统的管理软件,对集群的资源进行分配和管理. Mesos主要由以下几部分组成: Master: 管理各Slave节点 S ...
- 使用Cloudera Manager搭建MapReduce集群及MapReduce HA
使用Cloudera Manager搭建MapReduce集群及MapReduce HA 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.通过CM部署MapReduce On ...
- 使用Docker构建持续集成与自动部署的Docker集群
为什么使用Docker " 从我个人使用的角度讲的话 部署来的更方便 只要构建过一次环境 推送到镜像仓库 迁移起来也是分分钟的事情 虚拟化让集群的管理和控制部署都更方便 hub.docke ...
- VLAN 模式下的 OpenStack 管理 vSphere 集群方案
本文不合适转载,只用于自我学习. 关于为什么要用OpenStack 管理 vSphere 集群,原因可以有很多,特别是一些传统企业,VMware 的使用还是很普遍的,用 OpenStack 纳管至少会 ...
- [转帖]Ansible管理windows集群
Ansible管理windows集群 http://www.cnblogs.com/Dev0ps/p/10026908.html 写的挺好的 我关注点还是不够好呢 最近公司新项目需要安装400+win ...
- 厉害—Ansible管理windows集群
最近公司新项目需要安装400+windows server 2012系统的工作站,想着怎么能像linux下运用ansible批量管理,linux就很简单了有ssh服务 但是下却没这么简单,但还是有办法 ...
- 001.Ansible部署RHCS存储集群
一 前期准备 1.1 前置条件 至少有三个不同的主机运行monitor (MON)节点: 至少三个直接存储(非外部SAN硬件)的OSD节点主: 至少两个不同的manager (MGR)节点: 如果使用 ...
随机推荐
- javascript的单例/单体模式(Singleton)
首先,单例模式是对象的创建模式之一,此外还包括工厂模式.单例模式的三个特点:1,该类只有一个实例2,该类自行创建该实例(在该类内部创建自身的实例对象)3,向整个系统公开这个实例接口 Java中大概是这 ...
- AngulaJs -- 隔离作用域
具有隔离作用域的指令最主要的使用场景是创建可复用的组件 创建具有隔离作用域的指令需要将scope属性设置为一个空对象{}.如果这样做了,指令的 模板就无法访问外部作用域了: <div ng-co ...
- HTML5 移动开发(CSS3设计移动页面样式)
1.如何创建CSS样式表 2.CSS3的卓越特性 3.基于设备属性改变样式的媒体查询 4.如何使用属性改变元标签创建更美观移动页面 层叠样式表是移动WEB开发中的一个重要组成部分,本次分享将学到如 ...
- Vue.js几个简单用法
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- HDU 1728 逃离迷宫 BFS题
题目描述:输入一个m*n的地图,地图上有两种点,一种是 . 表示这个点是空地,是可以走的,另一种是 * ,表示是墙,是不能走的,然后输入一个起点和一个终点,另外有一个k输入,现在要你确定能否在转k次弯 ...
- 图文详解 解决 MVC4 Code First 数据迁移
在使用Code first生成数据库后 当数据库发生更改时 运行程序就会出现数据已更改的问题 这时可以删除数据库重新生成解决 但是之前的数据就无法保留 为了保留之前的数据库数据 我们需要使用到C ...
- C#使用redis学习笔记
1.官网:http://redis.io/(英) http://www.redis.cn/(中) 2.下载:https://github.com/dmajkic/redis/downloads(Wi ...
- 使用eclipse构建Maven项目及发布一个Maven项目
开发环境: Eclipse Jee Mars(截止2015年12月1日目前的最新版eclipse4.5),下载地址:http://www.eclipse.org/downloads/ 因为此版本已经集 ...
- 015_sublime插件管理及所有非常有用插件
一. <1>按照这个进行Package Control的安装 https://packagecontrol.io/installation import urllib.request,os ...
- http跨域时的options请求
1.背景 在前后端分离的项目中经常会遇到跨域请求的问题,如果没有进行跨域配置,会浏览器请求失败.我一般采用两种解决方案: 1.采用nginx进行转发,是前后端服务处于同一个域下面,从根本上避免跨域问题 ...